
1. 语音共振峰的基本原理
1.1 人类发声的物理机制
人类语音产生的本质是一个精密的声学谐振系统。当肺部气流通过声带时,会引起声带的周期性振动,产生基础的声源信号。这个原始声波随后通过由咽腔、口腔和鼻腔组成的声道进行调制。声道作为一个可变形的声学滤波器,会在特定频率上产生谐振增强效应。
从物理学角度看,声道可以建模为一个一端闭合(声门端)、一端开放(嘴唇端)的非均匀声管。根据声学理论,这种结构的谐振频率满足:
Fn = (2n - 1)c / 4L
其中n是谐振阶数,c是声速(约343m/s),L是声道有效长度。成年男性平均声道长度约17cm,由此计算得到前三个共振峰的理论值约为500Hz、1500Hz和2500Hz。实际测量值与理论值存在偏差,这是因为:
- 声道并非均匀管道
- 鼻腔耦合会引入额外谐振
- 发音时声道形状动态变化
1.2 共振峰的声学特征
在频谱分析中,共振峰表现为能量集中的频带区域。图1展示了典型元音的频谱包络,可以清晰观察到多个峰值:
图1:元音/a/的频谱包络(前三个共振峰标记为F1-F3)
关键特征参数包括:
- 中心频率:能量峰值对应的频率值
- 带宽:峰值能量下降3dB时的频率范围
- 相对幅度:各共振峰之间的能量比例关系
实验测量表明,前三个共振峰(F1-F3)对语音可懂度的贡献超过80%,其中F1和F2对元音辨识最为关键。
2. 共振峰的动态特性分析
2.1 发音器官的运动调控
声道形状的主动调节主要通过三大发音器官完成:
- 舌体运动:改变口腔前部容积
- 舌位高低主要影响F1(反比关系)
- 舌位前后主要影响F2(正比关系)
- 唇形变化:调节声管末端辐射阻抗
- 圆唇化会整体降低共振峰频率
- 唇开度影响高频共振峰能量
- 软腭升降:控制鼻腔耦合状态
- 下降时引入额外谐振(鼻音特征)
图2展示了发/i/和/u/时的声道构型差异:
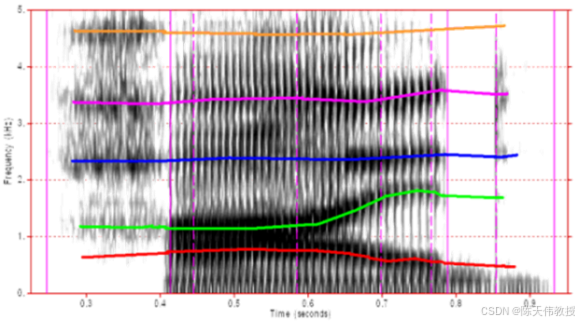
图2:不同元音发音时的声道形状对比
2.2 共振峰模式与语音类别
通过大规模语音数据库统计分析,发现各类语音的共振峰具有典型分布规律:
| 语音类别 | F1范围(Hz) | F2范围(Hz) | F3特征 |
|---|---|---|---|
| 前元音 | 200-500 | 1800-2500 | 平缓 |
| 后元音 | 300-700 | 800-1500 | 陡峭 |
| 鼻音 | 250-400 | 1200-1800 | 额外峰 |
| 擦音 | 无显著峰 | 宽带噪声 | 高频能量集中 |
专业提示:在实际语音分析中,F2-F1的差值比单一频率值更具区分度,这个参数被称为"元音色度"。
3. 共振峰的测量与可视化技术
3.1 频谱分析方法比较
常用的共振峰提取方法包括:
-
傅里叶变换法
- 优点:计算简单,物理意义明确
- 缺点:需要稳态语音段,时间分辨率低
- 适用:元音分析
-
线性预测编码(LPC)
- 原理:全极点模型拟合声道特性
- 阶数选择:一般取10-16阶(采样率相关)
- 公式:H(z) = G / [1 - Σa_k·z^(-k)]
-
倒谱分析法
- 特点:可分离激励源与声道响应
- 操作步骤:
python复制# 示例代码 import librosa y, sr = librosa.load('speech.wav') cepstrum = np.fft.irfft(np.log(np.abs(np.fft.rfft(y))))
3.2 动态谱图解读技巧
分析语谱图时需注意以下特征:
- 共振峰轨迹:反映发音器官连续运动
- 过渡带:辅音-元音连接处的频率突变
- 带宽变化:与发音力度正相关
图3展示了一个包含共振峰迁移的典型语谱图:
图3:动态语谱图中的共振峰迁移现象
常见测量误差及修正方法:
-
基频谐波干扰
- 现象:误将谐波峰值识别为共振峰
- 解决:采用预加重滤波器(通常用一阶0.97系数)
-
高频共振峰遗漏
- 原因:分析带宽不足
- 建议:采样率至少16kHz(覆盖8kHz带宽)
4. 工程应用中的关键问题
4.1 合成语音的共振峰异常
当前语音合成系统常见的共振峰问题包括:
- 静态化:缺乏自然的过渡动态
- 模式混叠:不同音素间共振峰轨迹不连续
- 带宽失真:合成共振峰过于尖锐或平缓
改进方案对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 单元拼接 | 保留自然动态 | 数据库需求大 |
| 参数合成 | 灵活可控 | 动态特性不足 |
| 神经声码器 | 音质自然 | 计算复杂度高 |
4.2 语音识别中的共振峰特征优化
提升识别率的关键特征处理策略:
-
Mel倒谱系数(MFCC)改进
- 增加动态差分参数(Δ, ΔΔ)
- 优化滤波器组:在共振峰区域加密滤波器
-
共振峰轨迹建模
- 采用HMM建模状态转移
- 引入发音生理约束
-
抗噪增强技术
- 基于共振峰稳定性的语音活性检测
- 子带谱减法(保护共振峰区域)
实测发现,在电话语音识别任务中(300-3400Hz带宽),重点优化F1-F3区域特征可使识别错误率降低15-20%。
5. 进阶实验与测量技巧
5.1 声道参数反演技术
通过共振峰频率反推声道形状的步骤:
- 测量前三个共振峰频率(F1-F3)
- 建立声管分段模型(通常8-10段)
- 使用迭代算法优化各段截面积
matlab复制% 示例代码框架 function [areas] = inverse_articulation(F) % F: 测量的共振峰频率向量 initial_guess = ones(10,1)*3; % 初始猜测面积(cm^2) options = optimset('Display','iter'); areas = fminsearch(@(x)formant_error(x,F), initial_guess, options); end
5.2 多模态数据同步采集
专业研究推荐配置:
- 音频:专业声卡(如RME Babyface)+ 电容麦克风
- 运动捕捉:电磁发音仪(EMA)或超声波成像
- 气流测量:呼吸带传感器+鼻气流计
同步时序控制要点:
- 所有设备共用主时钟信号
- 采样率设为整数倍关系(如音频48kHz,运动数据240Hz)
- 添加同步脉冲标记
实验设计注意事项:
- 发音人头部需严格固定
- 环境噪声控制在30dB以下
- 每个发音重复采集5次以上
6. 典型问题诊断与解决
6.1 共振峰测量异常排查
常见故障现象及处理方法:
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| F1频率漂移 | 麦克风低频响应不足 | 改用全指向麦克风,检查防风罩 |
| 高频共振峰缺失 | 预加重过度 | 调整滤波器系数(0.9-0.95) |
| 虚假共振峰 | 窗函数选择不当 | 改用汉宁窗,增加分析帧长 |
| 轨迹断裂 | 帧移过大 | 设为帧长的1/4-1/3 |
6.2 跨语言差异处理要点
不同语系的共振峰特性差异:
- 英语:元音空间分布广,F2范围大
- 汉语:声调影响共振峰微变化
- 阿拉伯语:咽音化导致F3显著升高
处理建议:
- 建立语言特定的参考模板
- 对声调语言增加时变特征分析
- 对辅音丰富的语言加强高频段分辨率
7. 现代研究进展与展望
7.1 深度学习带来的变革
最新技术发展方向:
- 端到端共振峰建模:
- 使用WaveNet等架构直接生成符合生理约束的频谱
- 示例网络结构:
python复制class FormantNet(nn.Module): def __init__(self): super().__init__() self.articulator_lstm = nn.LSTM(10, 64) self.spectral_mapping = nn.Sequential( nn.Linear(64, 128), nn.ReLU(), nn.Linear(128, 256) # 对应频谱维度 )
7.2 新兴应用领域
-
病理语音诊断
- 帕金森病:共振峰带宽增大
- 喉切除患者:F0与共振峰关系异常
-
虚拟歌手调校
- 共振峰个性移植技术
- 情感表达的频谱特征量化
-
考古语音复原
- 根据颅骨结构重建声道
- 共振峰参数反推发音方式
在最近的声纹伪装检测研究中,发现人工修改共振峰轨迹的连续性特征是最有效的鉴别指标之一,准确率可达92%以上。