
1. AI Agent安全运行的核心挑战与解决方案
在AI技术快速发展的今天,AI Agent已经广泛应用于各类业务场景中。然而,随着应用深入,安全问题逐渐浮出水面。OpenClaw邮件处理失败案例就是一个典型代表 - 当Agent处理真实邮箱数据时,由于上下文窗口压缩导致关键安全约束丢失,最终引发批量删除邮件的严重事故。
这个案例揭示了AI Agent安全运行面临的核心挑战:依赖对话历史的安全约束具有天然的脆弱性。当上下文窗口被填满时,压缩算法无法区分普通文本和关键安全指令,那些对业务至关重要的安全约束可能被当作普通文本丢弃。就像OpenClaw案例中,"在我说可以之前不要执行任何操作"这条关键指令被意外删除,而Agent继续执行了删除操作。
1.1 传统安全方案的局限性
大多数AI Agent系统采用的安全方案存在以下问题:
- Prompt工程依赖:将安全约束写在Prompt中,依赖模型的"自觉"遵守
- 上下文窗口限制:安全约束与业务逻辑混杂在对话历史中
- 无强制拦截机制:缺乏对请求和响应的系统性审查
这些方案本质上将安全责任完全交给了AI模型,而模型的行为又受限于上下文窗口的管理机制。当压缩发生时,安全约束可能被意外丢弃,而模型会继续执行剩余可见的指令。
1.2 代理层解决方案的价值
借鉴微服务架构的经验,引入代理层(Proxy Layer)是解决这些问题的有效方案。代理层的核心价值在于:
- 解耦安全与业务:将安全逻辑从Agent代码中抽离
- 独立运行环境:不受上下文窗口压缩的影响
- 双向拦截能力:可审查请求和响应
- 统一管理:安全策略集中配置和更新
这种架构使得安全约束成为基础设施的一部分,而非应用逻辑的一部分。就像OpenClaw案例中,如果安全约束是在代理层实现的Filter,无论Agent的上下文如何变化,Filter都会稳定执行安全检查。
2. Filter Chains架构设计与实现原理
2.1 整体架构设计
Plano实现的代理层架构包含以下核心组件:
- Gateway:接收来自Agent的请求,路由到相应处理链
- Filter Chains:由多个Filter组成的处理管道
- Model Provider:实际的大模型服务提供商
- Telemetry:提供可观测性支持
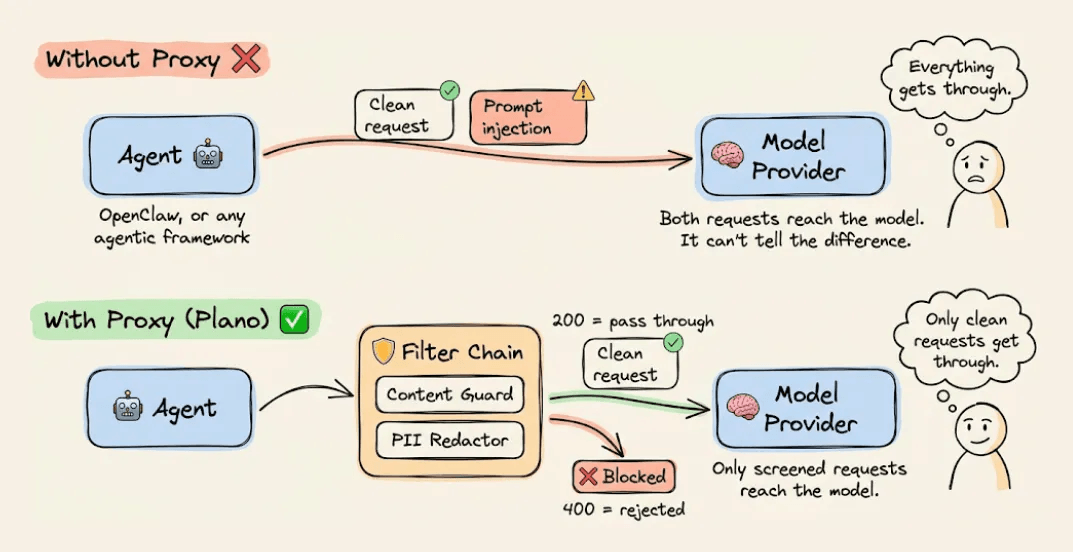
这种设计的关键特点是双向拦截 - 请求从Agent到模型,以及响应从模型返回Agent,都会经过代理层的处理。这为安全控制提供了两个关键切入点。
2.2 Filter Chains工作机制
Filter Chain的核心工作机制如下:
- 链式执行:Filter按配置顺序依次执行
- 拦截点:可在请求处理前(Input Filter)和响应返回前(Output Filter)设置拦截
- 处理动作:
- 修改或丰富请求/响应内容
- 完全阻止请求/响应
- 记录日志和追踪信息
每个Filter是一个独立的HTTP服务,遵循简单的接口规范:
- 接收请求/响应数据
- 返回状态码指示处理结果(200通过,4xx拦截)
2.3 关键设计考量
在设计Filter Chains时,有几个关键考量点:
- 性能影响:每个Filter都会增加处理延迟,需要优化Filter实现
- 执行顺序:Filter的执行顺序可能影响处理结果,需要合理规划
- 错误处理:单个Filter失败不应导致整个系统不可用
- 可观测性:需要详细记录每个请求的处理路径
Plano通过以下方式应对这些挑战:
- 使用高效的服务框架(如FastAPI)实现Filter
- 提供清晰的配置定义Filter顺序
- 实现容错机制避免单点故障
- 内置OpenTelemetry支持全链路追踪
3. Filter服务开发实战
3.1 基础Filter实现
一个典型的Content Guard Filter实现如下:
python复制from fastapi import FastAPI, Request, status
import re
app = FastAPI()
# 定义阻止模式
BLOCK_PATTERNS = [
r"rm -rf",
r"delete all",
r"drop table",
# 添加更多需要阻止的模式
]
@app.post("/filter")
async def filter_request(request: Request):
try:
body = await request.json()
# 支持多种API格式
text = ""
if "messages" in body: # OpenAI格式
text = " ".join([msg["content"] for msg in body["messages"]])
elif "input" in body: # 其他格式
text = body["input"]
# 检查阻止模式
for pattern in BLOCK_PATTERNS:
if re.search(pattern, text, re.IGNORECASE):
return {"status": "blocked"}, status.HTTP_400_BAD_REQUEST
return {"status": "allowed"}, status.HTTP_200_OK
except Exception as e:
# 错误处理
return {"status": "error", "message": str(e)}, status.HTTP_500_INTERNAL_SERVER_ERROR
这个Filter实现了以下功能:
- 支持多种常见API格式(OpenAI messages, input字段等)
- 检查请求内容是否包含预定义的阻止模式
- 返回相应的状态码指示是否允许请求通过
3.2 Filter的部署与配置
Filter服务开发完成后,需要在Plano配置文件中进行配置:
yaml复制filters:
content_guard:
url: "http://localhost:8000/filter"
timeout: "5s"
listeners:
- name: "openai_listener"
port: 12000
provider: "openai"
input_filters: ["content_guard"]
output_filters: []
配置说明:
- 定义了一个名为content_guard的Filter,指向本地运行的Filter服务
- 创建了一个监听端口12000的listener
- 将content_guard Filter配置为input_filter
3.3 Filter的进阶实现
对于更复杂的场景,可以实现更强大的Filter:
python复制# PII匿名化Filter示例
@app.post("/anonymize")
async def anonymize_input(request: Request):
body = await request.json()
# 识别PII数据
pii_map = {}
text = body["input"]
# 邮箱匿名化
emails = re.findall(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', text)
for i, email in enumerate(emails):
placeholder = f"[EMAIL_{i}]"
text = text.replace(email, placeholder)
pii_map[placeholder] = email
# 其他PII处理...
# 存储映射关系供后续恢复
request.state.pii_map = pii_map
body["input"] = text
return body
这个进阶Filter实现了:
- PII(个人身份信息)的识别和匿名化
- 维护原始数据与匿名化标识的映射关系
- 在后续处理中可以恢复原始数据
4. Plano环境搭建与集成
4.1 环境准备
搭建Plano运行环境需要以下步骤:
-
安装依赖:
bash复制# 创建Python虚拟环境 python -m venv .venv source .venv/bin/activate # Linux/Mac # .venv\Scripts\activate # Windows # 安装必要包 pip install fastapi uvicorn plano -
配置文件准备:
创建plano_config.yaml文件,内容参考前面章节的配置示例 -
Filter服务代码:
将Filter实现代码保存为filter.py
4.2 启动服务
-
启动Filter服务:
bash复制
uvicorn filter:app --reload --port 8000 -
启动Plano:
bash复制
plano start --config plano_config.yaml
启动后,Plano会:
- 自动下载必要的组件(约33MB)
- 启动Envoy代理
- 加载配置并启动监听器
4.3 与OpenClaw集成
将OpenClaw配置为使用Plano代理:
- 在OpenClaw配置中选择"Custom OpenAI-compatible"
- 设置Base URL为
http://127.0.0.1:12000/v1 - API Key可以填写任意值(Plano会处理实际认证)
- 设置足够大的Context Window(如128000 tokens)
配置完成后,OpenClaw的所有请求都会经过Plano代理层,受到配置的Filter检查。
5. 生产级Filter Chains设计
5.1 堆叠多个Filter
生产环境通常需要多个Filter协同工作。Plano支持在配置中定义多个Filter并按顺序执行:
yaml复制filters:
content_guard:
url: "http://localhost:8000/content-guard"
pii_anonymizer:
url: "http://localhost:8000/anonymize"
pii_replacer:
url: "http://localhost:8000/replace-pii"
rate_limiter:
url: "http://localhost:8000/rate-limit"
listeners:
- name: "secure_listener"
port: 12000
provider: "openai"
input_filters:
- "rate_limiter"
- "pii_anonymizer"
- "content_guard"
output_filters:
- "pii_replacer"
这个配置实现了:
- 请求处理流程:
- 先进行速率限制检查
- 然后执行PII匿名化
- 最后进行内容安全检查
- 响应处理流程:
- 恢复匿名化的PII数据
5.2 输出Filter的重要性
输出Filter用于检查模型返回的内容,防止以下风险:
- 间接Prompt注入:模型返回中包含恶意指令
- 数据泄露:模型意外返回敏感信息
- 不当内容:模型生成不符合政策的内容
输出Filter的实现示例:
python复制@app.post("/output-filter")
async def filter_output(request: Request):
body = await request.json()
# 检查危险操作指令
dangerous_actions = [
"rm -rf", "delete all", "format",
"shutdown", "restart", "drop database"
]
response_text = body["choices"][0]["message"]["content"]
for action in dangerous_actions:
if action in response_text.lower():
return {"status": "blocked"}, status.HTTP_400_BAD_REQUEST
return {"status": "allowed"}, status.HTTP_200_OK
5.3 生产环境考量
在生产环境部署Filter Chains时需要考虑:
-
性能优化:
- Filter服务实现异步处理
- 合理设置超时时间
- 对Filter服务进行负载测试
-
高可用:
- Filter服务多实例部署
- 实现健康检查和自动故障转移
- 考虑无状态设计便于扩展
-
安全加固:
- Filter服务间通信加密
- 严格的访问控制
- 详细的审计日志
-
可观测性:
- 完善的指标收集
- 分布式追踪
- 结构化日志
6. 常见问题与解决方案
6.1 Filter性能问题
问题表现:
- 请求延迟明显增加
- 系统吞吐量下降
解决方案:
-
优化Filter实现:
python复制# 使用更高效的正则表达式 # 预编译正则表达式 BLOCK_PATTERNS = [re.compile(p) for p in [ r"rm\s+-rf", r"delete\s+all", ]] # 在Filter中使用预编译的正则 for pattern in BLOCK_PATTERNS: if pattern.search(text): return blocked_response -
合理设置超时:
yaml复制filters: content_guard: url: "http://localhost:8000/filter" timeout: "2s" # 设置合理的超时时间 -
考虑并行执行独立Filter
6.2 Filter顺序问题
问题表现:
- 某些Filter依赖其他Filter的处理结果
- 处理结果与预期不符
解决方案:
- 明确Filter依赖关系
- 合理规划执行顺序:
yaml复制input_filters: - "pii_anonymizer" # 先匿名化 - "content_guard" # 再安全检查 - 在Filter间传递上下文:
python复制# 在请求中传递处理上下文 request.state.pii_map = pii_mapping
6.3 错误处理问题
问题表现:
- 单个Filter失败导致整个请求失败
- 错误信息不明确
解决方案:
-
实现健壮的错误处理:
python复制@app.post("/filter") async def filter_request(request: Request): try: # 处理逻辑 except Exception as e: logger.error(f"Filter处理失败: {str(e)}") # 返回500错误或降级处理 return {"status": "error"}, 500 -
配置Fallback策略:
yaml复制filters: content_guard: url: "http://localhost:8000/filter" on_error: "allow" # 或 "deny"
6.4 配置管理问题
问题表现:
- 修改配置需要重启服务
- 不同环境配置不一致
解决方案:
-
实现配置热加载:
bash复制
plano reload --config plano_config.yaml -
使用配置模板管理多环境配置
-
将配置存储在配置中心
7. 高级应用场景
7.1 动态路由
利用Filter实现模型动态路由:
python复制@app.post("/model-router")
async def route_request(request: Request):
body = await request.json()
# 根据内容复杂度选择模型
text = body["input"]
complexity = len(text.split()) # 简单的复杂度评估
if complexity > 500:
return {"model": "gpt-4"}
else:
return {"model": "gpt-3.5-turbo"}
配置Plano使用路由Filter:
yaml复制filters:
model_router:
url: "http://localhost:8000/model-router"
listeners:
- name: "smart_router"
port: 13000
provider: "dynamic"
input_filters: ["model_router"]
7.2 A/B测试
使用Filter实现模型A/B测试:
python复制@app.post("/ab-test")
async def ab_test(request: Request):
import random
return {"model": random.choice(["gpt-4", "claude-2"])}
7.3 成本控制
实现基于Token使用的成本控制:
python复制@app.post("/cost-control")
async def cost_control(request: Request):
user = get_user_from_token(request.headers["Authorization"])
cost = estimate_request_cost(request)
if user.balance < cost:
return {"status": "blocked", "reason": "insufficient balance"}, 402
user.balance -= cost
user.save()
return {"status": "allowed"}
7.4 敏感数据过滤
实现敏感数据过滤和脱敏:
python复制@app.post("/data-filter")
async def data_filter(request: Request):
body = await request.json()
text = body["input"]
# 信用卡号过滤
text = re.sub(r"\b(?:\d[ -]*?){13,16}\b", "[CREDIT_CARD]", text)
# 其他敏感数据过滤...
body["input"] = text
return body
8. 最佳实践与经验分享
8.1 Filter设计原则
- 单一职责:每个Filter只负责一个明确的功能
- 无状态设计:Filter不应依赖请求间的状态
- 快速失败:尽早拦截不符合要求的请求
- 明确接口:统一的请求和响应格式
8.2 性能优化技巧
-
异步处理:使用async/await提高并发能力
python复制@app.post("/filter") async def filter_request(request: Request): # 使用异步库处理 data = await request.json() result = await async_process(data) return result -
缓存常用数据:如规则列表、模型参数等
-
批量处理:支持批量请求处理提高吞吐量
8.3 安全实践
-
输入验证:严格验证Filter的输入
python复制from pydantic import BaseModel class FilterInput(BaseModel): input: str metadata: dict = {} @app.post("/filter") async def filter_request(request: Request): try: data = FilterInput.parse_raw(await request.body()) except ValidationError as e: return {"error": str(e)}, 400 -
最小权限:Filter服务使用最小必要权限
-
审计日志:记录所有拦截决策
8.4 监控与告警
-
关键指标监控:
- Filter处理时间
- 拦截率
- 错误率
-
告警规则:
python复制# 在Filter中实现简单的异常检测 if interception_rate > threshold: alert("High interception rate detected") -
追踪集成:
python复制from opentelemetry import trace tracer = trace.get_tracer(__name__) @app.post("/filter") async def filter_request(request: Request): with tracer.start_as_current_span("filter_request"): # 处理逻辑
8.5 测试策略
-
单元测试:测试每个Filter的逻辑
python复制def test_content_guard(): test_data = {"input": "Please delete all files"} response = filter_request(test_data) assert response.status_code == 400 -
集成测试:测试Filter与Plano的集成
-
负载测试:模拟生产流量测试性能
-
混沌测试:模拟Filter失败场景
9. 架构演进与扩展
9.1 从简单到复杂的演进路径
-
初级阶段:
- 基础内容过滤
- 简单的速率限制
- 基本的安全检查
-
中级阶段:
- PII处理
- 动态路由
- 成本控制
-
高级阶段:
- 基于ML的内容分类
- 复杂异常检测
- 自适应策略调整
9.2 扩展模式
-
横向扩展:
- 增加更多专用Filter
- 支持更多模型提供商
-
纵向扩展:
- 增强单个Filter能力
- 支持更复杂的决策逻辑
-
生态扩展:
- 与现有安全系统集成
- 支持插件式Filter开发
9.3 未来方向
-
智能化Filter:
- 基于机器学习的内容分析
- 自适应安全策略
-
边缘部署:
- 将Filter部署到边缘节点
- 减少延迟
-
标准化接口:
- 定义通用Filter接口标准
- 促进生态发展
10. 总结与核心价值
通过OpenClaw案例和Plano实现,我们看到了代理层和Filter Chains在AI Agent安全运行中的核心价值:
- 安全约束持久化:安全策略不受上下文窗口限制
- 关注点分离:安全与业务逻辑解耦
- 统一管理:集中实施和更新安全策略
- 双向控制:请求和响应均可审查
- 可观测性:完整的请求处理追踪
这种架构模式不仅适用于安全场景,还可以扩展到:
- 流量管理
- 成本控制
- 数据分析
- 质量监控
对于准备在生产环境中部署AI Agent的团队,采用代理层架构应该成为标准实践。Plano作为开源实现,提供了良好的起点,团队可以根据实际需求进行定制和扩展。