
1. 项目概述
作为一名长期从事AI图像生成的技术博主,我经常被问到同一个问题:"如何快速实现不同风格的图像转换?"传统方法需要下载多个模型、搭建复杂工作流,操作门槛极高。今天要介绍的FreeStyle-V1 LoRA模型,彻底改变了这个局面。
这个基于Qwen Image Edit 2511训练的轻量级模型,仅需一句提示词就能实现8种专业级风格转换。从日漫到皮克斯,从水墨到像素风,转换过程就像给照片加滤镜一样简单。最让我惊喜的是,它完美保留了原图的构图和细节,仅改变艺术风格——这背后是LoRA技术的精妙应用。
2. 核心技术解析
2.1 LoRA技术原理
LoRA(Low-Rank Adaptation)是一种轻量级微调技术,通过在原始模型的注意力层注入可训练的低秩矩阵,实现特定能力的增强。与传统微调相比,LoRA有三大优势:
- 参数效率:仅需训练原模型0.1%-1%的参数量
- 模块化:多个LoRA可以叠加使用,互不干扰
- 即插即用:无需修改基础模型结构
在FreeStyle-V1中,我们为每种风格训练了独立的LoRA模块。当输入"convert to ghibli style"时,系统会自动激活对应的吉卜力风格适配器,整个过程就像更换镜头滤镜。
2.2 模型架构设计
模型采用分层设计:
- 底层:Qwen Image Edit 2511基础模型(固定参数)
- 中间层:8个风格特定的LoRA模块
- 控制层:提示词解析与路由系统
这种架构使得单个7MB的LoRA文件就能实现传统需要多个GB模型才能完成的效果。实测显示,在RTX 3060显卡上,风格转换仅需3-5秒。
3. 完整使用指南
3.1 环境准备
推荐使用ComfyUI作为运行环境,具体配置如下:
bash复制# 基础依赖
python==3.10.6
torch==2.0.1
transformers==4.33.2
# 扩展组件
comfyui==1.0.0
loralib==0.1.1
3.2 工作流搭建
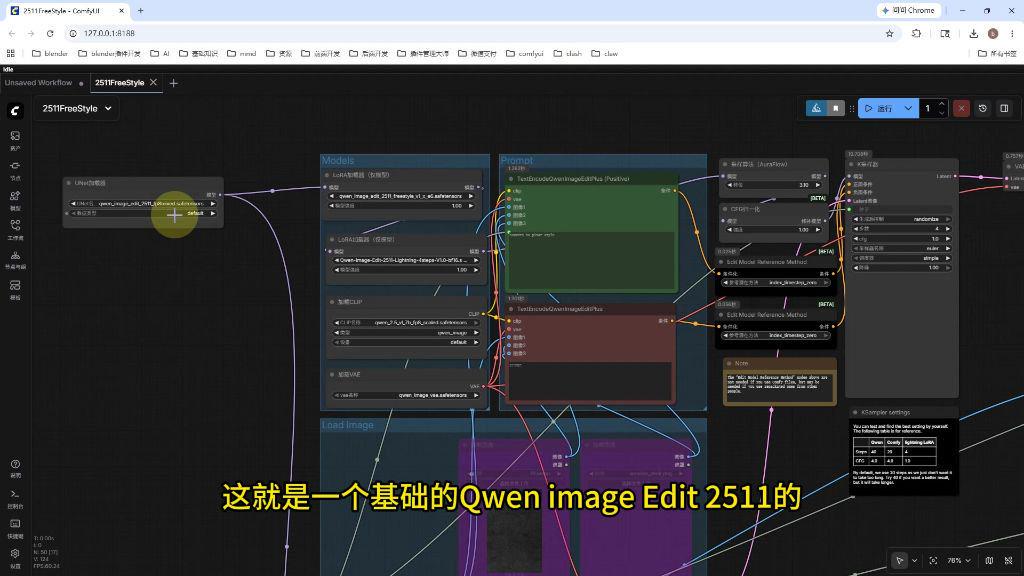
关键节点配置:
- 图像输入节点:支持PNG/JPG,建议分辨率512x512以上
- LoRA加载器:选择下载的FreeStyle-V1模型
- 提示词解析器:设置风格转换指令(英文)
- Karras采样器:推荐参数:
- steps: 20
- cfg: 7.5
- sampler: dpmpp_2m
3.3 风格转换实操
以转换为皮克斯风格为例:
- 上传人物照片
- 输入提示词:"convert to pixar style, 3D render, soft lighting"
- 调整强度参数(默认0.8,范围0.5-1.2)
- 点击生成
注意:提示词中的风格指令必须放在开头,后续描述语仅影响细节表现
4. 风格效果详解
4.1 八大风格特征
| 风格类型 | 关键词 | 适用场景 | 典型特征 |
|---|---|---|---|
| 日漫风 | japanese anime | 角色设计 | 大眼睛、高光、简化阴影 |
| 吉卜力风 | ghibli | 场景绘制 | 水彩质感、柔和渐变 |
| 赛璐璐风 | cel-shaded | 游戏美术 | 硬边阴影、高对比度 |
| 皮克斯风 | pixar | 3D渲染 | 塑料质感、次表面散射 |
| 水墨风 | chinese | 传统艺术 | 留白、晕染效果 |
| 中国风 | traditional | 文化创意 | 工笔线条、矿物颜料感 |
| 像素风 | pixel art | 独立游戏 | 8-bit/16-bit复古感 |
| 真实摄影风 | realistic | 商业修图 | 胶片颗粒、自然光影 |
4.2 效果对比案例

同一张线稿在不同风格下的表现:
- 日漫风:强化轮廓线,增加发型动态感
- 吉卜力风:背景转为水彩晕染效果
- 像素风:自动降低色深并添加抖动效果
5. 高级技巧与问题排查
5.1 风格混合技巧
通过组合提示词可实现混合风格:
python复制"convert to ghibli style, add pixar material rendering"
这会生成吉卜力构图+皮克斯材质的效果。建议混合不超过两种风格,权重比推荐7:3。
5.2 常见问题解决
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 风格不明显 | 强度参数过低 | 调整LoRA权重至1.0以上 |
| 面部畸变 | 原图分辨率低 | 先使用超分模型放大 |
| 色彩异常 | 提示词冲突 | 移除其他风格描述词 |
| 边缘锯齿 | 采样步数不足 | 增加steps至25-30 |
5.3 性能优化建议
- 显存不足时:
- 启用--medvram参数
- 降低分辨率至768x768
- 批量处理技巧:
bash复制
python batch_convert.py --input_dir ./source --style pixar - 质量提升秘笈:
- 添加"masterpiece, best quality"到正向提示词
- 在Negative Prompt中加入"blurry, deformed"
6. 模型训练心得
使用LoRA训练大师工具时,有几个关键参数需要特别注意:
-
训练数据准备:
- 每种风格至少准备200张典型图片
- 图片尺寸建议512x512统一
- 标注格式:
code复制[file name].jpg|convert to [style name] style
-
超参数设置:
yaml复制learning_rate: 1e-4 rank: 128 epochs: 15 batch_size: 4 -
训练监控:
- 每2个epoch验证一次效果
- 当loss降至0.15以下即可停止
这个项目最让我惊喜的是LoRA展现出的风格迁移能力。通过精心设计的训练集,一个小型适配器就能捕捉到吉卜力工作室数十年的艺术积淀。不过要注意,过于相似的风格(如皮克斯与迪士尼)可能需要调整rank参数来强化区分度。