
1. 多模态Agent评测的现状与挑战
当前AI领域最令人振奋的进展之一,就是多模态大模型在视觉理解能力上的突破。从GPT-4V到Gemini 1.5,这些模型在标准测试集上展现出的图像理解能力常常令人惊叹。然而,当我们把这些"实验室优等生"放到真实世界场景中,情况却往往令人大跌眼镜。
最近,由香港科技大学、浙江大学等机构联合发布的AgentVista评测基准,给我们敲响了警钟。这个包含209道真实世界任务的测试集,让当前最先进的AI模型集体"翻车"——即便是表现最好的Gemini-3-Pro,整体准确率也仅有27.27%。这意味着,在四分之三的情况下,这些号称拥有强大视觉理解能力的AI,实际上无法正确解决现实世界中的视觉问题。
1.1 现有评测的局限性
为什么实验室表现和真实场景表现会有如此巨大的差距?问题很大程度上出在现有的评测方法上。目前主流的多模态Agent评测存在两个致命缺陷:
能力碎片化评测(Capability-Specific Evaluation):大多数benchmark只测试单一能力,比如有的只测图像分类,有的只测目标检测,有的只测视觉问答。这种"单项考试"模式无法评估AI在复杂任务中协调多种技能的真实能力。就像测试一个厨师,只让他切菜或只让他炒菜,却从不评估他完成一道完整菜品的能力。
真实性与难度的失衡:为了增加测试难度,很多benchmark会简化视觉输入或采用不自然的任务设置。比如VisualToolBench会对输入图像进行预处理,移除背景干扰,调整大小和对比度。这就像测试驾驶技术时,把车放在空旷的停车场里,而不是真实的城市街道上。
1.2 AgentVista的创新设计
AgentVista针对这些问题提出了全新的评测框架,其核心设计原则包括:
视觉中心(Vision-Centric):每道题的关键证据必须从图像中获取,这些图像都是真实拍摄或截图的,包含各种现实世界中的视觉噪声和干扰。比如要识别商品标签上的小字,或者电路板上的芯片型号。
混合工具交错使用(Interleaved Hybrid Tool Use):每道题至少需要两种以上工具类别的组合使用。典型的解题流程可能是:先用代码工具裁剪放大图像细节,再用图像搜索找到类似产品,接着用网页搜索查询参数,最后用计算工具得出答案。
可验证性(Verifiable):每道题都有明确的标准答案,避免主观评判带来的评测噪声。答案可能是数字、名称或简短描述,就像数学题一样客观。
2. AgentVista的构建与任务分析
构建一个真正反映现实世界复杂性的评测集绝非易事。AgentVista团队从超过30万张候选图像开始,经过四轮严格筛选,最终只保留了209道题目,淘汰率高达99.93%。这种近乎苛刻的筛选标准,确保了每道题都能真实挑战AI的视觉理解能力。
2.1 四阶段筛选流程
第一阶段:模型辅助筛选
使用Claude-Opus-4进行初步筛选,过滤掉视觉信息不足或问题定义不明确的图像。从30万张图中保留了约568张(0.19%)。
第二阶段:专家标注
专业标注员将任务改写为真实的用户请求,确保每道题都符合"视觉中心"原则,并且有明确答案。产出315道候选任务。
第三阶段:执行验证
在实际工具环境中测试每道题,确保需要跨工具协作才能解决。淘汰了74道过于简单或工具使用单一的任务。
第四阶段:双重复核
两轮人工检查,移除证据不充分或答案不稳定的样本。最终得到209道精品题目,每道题的平均构建时间约4小时。
2.2 任务领域分布
AgentVista覆盖了7大生活与专业领域,25个子方向,确保评测的全面性:
| 领域 | 子方向示例 | 任务数量 |
|---|---|---|
| 技术 | 电路维修、设备调试 | 34 |
| 商业 | 商品比价、营养分析 | 28 |
| 地理 | 地图导航、地标识别 | 26 |
| 娱乐 | 电影场景、游戏攻略 | 24 |
| 社会生活 | 交通标志、公共设施 | 31 |
| 学术 | 图表分析、论文图解 | 32 |
| 文化 | 艺术品鉴定、历史照片 | 34 |
特别值得注意的是,58道题(27.8%)需要处理多张关联图像,模拟现实世界中需要综合多方信息的场景。比如家居装修任务,可能需要对比多张房间照片,匹配地板样式,再查询产品规格并计算费用。
3. 评测结果与深度分析
当我们将当前最先进的14个多模态模型放在AgentVista上测试时,结果令人深思。表现最好的Gemini-3-Pro整体准确率仅为27.27%,而其他模型的平均表现更低。这说明在真实世界的视觉问题面前,现有AI还有很长的路要走。
3.1 各模型表现对比
下表展示了部分模型在不同领域的表现:
| 模型 | 商业 | 地理 | 技术 | 社会生活 | 整体 |
|---|---|---|---|---|---|
| Gemini-3-Pro | 16.67% | 28.21% | 32.35% | 32.00% | 27.27% |
| GPT-5 | 23.81% | 23.08% | 35.29% | 28.00% | 24.40% |
| Claude-Opus-4.1 | 11.90% | 23.08% | 29.41% | 16.00% | 18.18% |
| Qwen3-VL-235B | 7.14% | 7.69% | 26.47% | 16.00% | 12.92% |
从结果中我们可以发现几个有趣的现象:
-
没有全能冠军:Gemini-3-Pro在整体上领先,但GPT-5在商业和技术领域表现更好,Claude则在地理领域有优势。这说明不同模型有各自的"专长"。
-
多图任务表现更好:出乎意料的是,需要处理多张图像的任务,模型表现反而优于单图任务。比如Gemini-3-Pro在多图任务上达到36.84%,远高于单图的23.68%。这表明多角度信息实际上降低了歧义性,真正的瓶颈在于长链条的推理和工具使用。
-
开源模型差距明显:Qwen3-VL-235B作为开源代表,表现显著落后于商业模型,反映出开源生态在多模态Agent领域的滞后。
3.2 错误类型分析
通过分析模型的错误案例,我们可以更深入地理解它们的局限性:
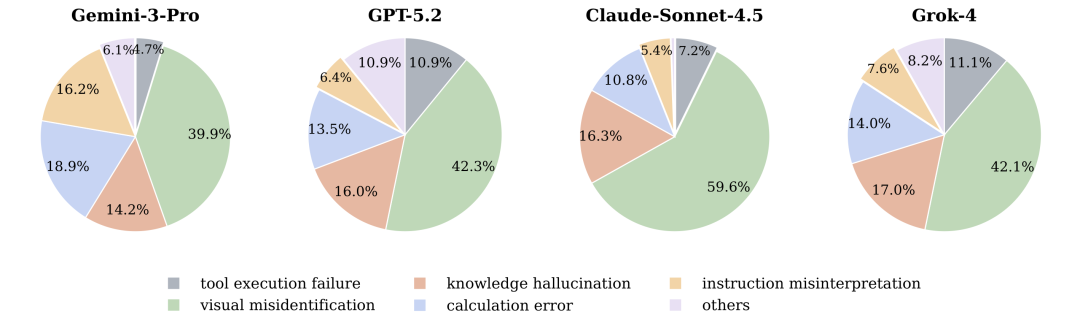
视觉误识别(Visual Misidentification):占比最高(约40%)的错误类型。模型经常看错图像中的关键细节,比如把"10mg"看成"100mg",或者混淆相似的电子元件。这种基础感知错误会引发后续推理的连锁反应。
知识幻觉(Knowledge Hallucination):模型会编造看似合理但缺乏图像依据的事实。比如看到一张药品图片,可能会错误地声称"这是处方药",而实际上图片中并没有相关说明。
工具使用不当:约20%的错误源于工具使用策略问题。比如该用图像搜索时用了网页搜索,或者代码工具的参数设置错误。
规划失败:15%的错误是因为模型无法制定合理的解题步骤,陷入循环或遗漏关键环节。
3.3 工具使用模式差异
不同模型展现出显著不同的工具使用偏好:
-
GPT-5系列:重度依赖代码工具(特别是图像裁剪),占总工具使用量的45%以上。这反映出其强项在于图像处理和计算。
-
Gemini系列:偏好网页搜索(占38%),倾向于先检索相关信息再结合视觉理解。
-
Claude系列:工具使用最为均衡,但在图像搜索上使用最少,可能是其视觉搜索能力相对较弱。
-
开源模型:工具使用次数明显少于商业模型,反映出其在复杂任务规划上的不足。
4. 挑战与未来方向
AgentVista的评测结果清晰地揭示了当前多模态Agent面临的几大核心挑战,也为我们指明了可能的改进方向。
4.1 关键挑战
细粒度视觉理解:模型在微观层面的视觉感知仍然不够可靠。一个微小的识别错误就可能导致整个任务失败。这需要更好的视觉编码器和更精细的注意力机制。
长链条推理:AgentVista任务平均需要12.67轮工具调用,复杂任务甚至超过25轮。现有模型很难维持如此长时间的连贯性和一致性,经常出现"忘记"早期信息或偏离主题的情况。
领域泛化:没有模型能在所有领域保持稳定表现。在商业场景表现良好的模型,可能在文化领域表现平平。这说明当前的多模态能力还缺乏真正的通用性。
4.2 潜在解决方案
测试时扩展(Test-Time Scaling):实验表明,通过多次采样并选择最佳答案,可以显著提升表现。比如Gemini-3-Flash在16次采样后,Pass@K指标从21.05%提升到51.67%。但这种方法计算成本高昂,需要更智能的选择策略。
强化学习优化:当前的模型在生成多个候选方案后,缺乏有效的评估机制。结合强化学习训练专门的奖励模型,可能帮助系统更好地选择最优解。
混合专家架构:针对不同领域训练专门的子模型,再通过路由机制组合使用,可能是提升领域适应性的有效途径。
人类反馈微调:引入更多的人类偏好数据,帮助模型更好地理解复杂任务的需求和评估标准。
5. 对AI开发的实践启示
AgentVista的研究不仅具有学术价值,也为实际AI应用开发提供了重要参考。以下是几点关键启示:
5.1 不要过度依赖实验室指标
一个在标准测试集上达到90%准确率的模型,在真实场景中可能连30%都达不到。开发者需要建立更贴近实际应用的评估体系,避免陷入"指标游戏"的陷阱。
5.2 重视工具链建设
单一模型很难解决所有问题。构建完善的工具生态系统(搜索、计算、专业数据库等),并训练模型有效利用这些工具,比一味增大模型规模可能更有效。
5.3 关注错误传播
在多步任务中,早期的小错误会导致后续完全偏离轨道。需要开发更好的错误检测和恢复机制,比如引入验证步骤或备选方案。
5.4 领域适配至关重要
通用模型在实际业务场景中往往需要针对性的优化。收集领域特定的数据和用例,进行有针对性的微调,是提升实用性的关键。
6. 评测基准的使用建议
对于想要使用AgentVista进行模型评估或改进的研究团队,以下是一些实用建议:
逐步测试:不要一开始就尝试所有209道题。可以按领域或难度分批测试,先聚焦最相关的任务类型。
详细记录:不仅要记录最终答案是否正确,还要详细记录模型的完整推理过程、工具使用序列和中间结果。这些细节对分析改进至关重要。
对比分析:同时测试多个模型时,注意比较它们在工具选择、推理步骤上的差异,而不仅仅是最终准确率。
可视化分析:对模型的注意力图进行可视化,了解它到底"看"了图像的哪些部分,这有助于诊断视觉理解的问题。
人类基线:条件允许时,可以请人类专家完成部分任务,建立人类表现基线,更合理地评估模型差距。
7. 开源生态的机遇
AgentVista作为一个开源项目,为学术界和工业界提供了宝贵的资源。基于此,开源社区可以在以下方向做出贡献:
扩展任务集:在现有7大领域基础上,增加更多专业场景,如医疗影像、工业检测等。
开发轻量级方案:探索在较小模型上实现更好表现的方法,推动技术民主化。
工具插件开发:丰富工具生态系统,开发更多专业领域的工具插件,如化学式识别、法律条文查询等。
错误分析工具:构建自动化的错误分类和分析工具,帮助研究者更快定位模型缺陷。
8. 商业应用的考量
对于考虑将多模态Agent投入实际应用的企业,AgentVista的结果提示了几点重要考量:
场景选择:先从视觉需求相对简单、工具链清晰的场景入手,如商品信息查询、简单图像分类等,避免一开始就挑战过于复杂的任务。
混合智能:在关键环节保留人工审核或干预的可能性,构建人机协作的工作流,而非完全依赖AI。
持续评估:建立与业务真实需求相符的评估体系,定期测试模型表现,监控性能变化。
成本平衡:最先进的模型不一定性价比最高。根据实际需求选择适当规模的模型,平衡性能和成本。
9. 个人研究体会
在实际使用AgentVista进行模型测试的过程中,我有几点深刻体会:
首先,当前AI的视觉能力被严重高估了。即使在看似简单的任务上,模型的失败方式常常出人意料。比如在一个识别药品剂量的任务中,多个顶级模型都把"10mg"误认为"100mg",而这种错误在真实医疗场景中可能是灾难性的。
其次,工具使用能力比预想的更重要。一个擅长选择和使用工具的模型,即使基础视觉能力稍弱,整体表现也可能更好。这提示我们在模型开发中应该更重视工具学习和规划能力的培养。
最后,评测基准的设计真的能左右技术发展的方向。像AgentVista这样贴近真实场景的评测,可能会推动研究社区更多地关注实际应用价值,而不仅仅是刷榜。