低资源语音识别:Whistle模型在勉语中的应用

1. 项目概述
在语音识别领域,主流技术通常需要数百到数千小时的带标注语音数据才能达到理想效果。但对于少数民族语言这类低资源语言来说,获取大量标注数据往往面临巨大挑战。勉语作为中国瑶族的主要民族语言,就是一个典型案例。我们团队在不到10小时的勉语语音标注数据上,探索了三种不同的预训练方法,最终发现基于音素监督的Whistle模型表现最为出色。
这个项目最吸引我的地方在于它突破了传统语音识别对海量标注数据的依赖。通过创新的弱监督音素预训练方法,我们成功实现了在极少量标注数据下的高精度语音识别。这不仅为少数民族语言的数字化保护提供了新思路,也为其他低资源语言的语音识别开辟了新途径。
2. 核心方法解析
2.1 三种预训练方法对比
在低资源语音识别场景下,我们主要比较了三种主流预训练方法:
-
基于音素监督的预训练:
- 使用音素作为基本建模单元
- 音素记录了语言的发音特征
- 更适合跨语言语音特征共享
- 代表模型:Whistle
-
基于子词监督的预训练:
- 使用子词(如BPE)作为建模单元
- 子词是语言文本的记录符号
- 需要更多数据学习发音规则
- 代表模型:Whisper
-
自监督预训练:
- 完全无监督学习语音特征
- 需要大量数据自学习
- 迁移效果相对较差
提示:音素作为语音的最小单位,能够更直接地捕捉发音特征,这使得基于音素的方法在跨语言迁移时更具优势。
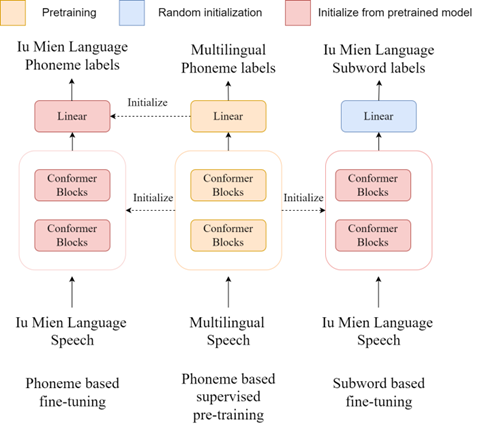
2.2 Whistle模型架构
Whistle模型的核心创新在于其弱监督的音素预训练策略:
-
模型输入:
- 原始语音波形
- 带噪声的音素标注(弱监督)
-
编码器架构:
- 基于Transformer的声学编码器
- 多语言共享参数空间
- 预训练时使用CTC损失
-
微调策略:
- 保持编码器参数固定
- 仅微调顶部分类层
- 可复用预训练音素参数
3. 勉语特性与数据处理
3.1 勉语语言特点
勉语作为瑶族的主要语言,具有以下显著特征:
-
书写系统:
- 使用26个基本拉丁字母
- 每个书写单位对应特定发音
- 可直接根据书写拼读
-
音节结构:
- 单词可分为1个或多个音节
- 每个音节包含声母和韵母
- 韵母可细分为韵头、韵腹、韵尾
-
声调系统:
- 共8个声调
- 用5个字母表示(h、v、z、x、v)
- 无标记时为阴平声调
3.2 数据准备与处理
我们的实验使用了不到10小时的勉语标注数据,处理流程如下:
-
数据收集:
- 来自公开的勉语语音数据集
- 包含多种发音人和场景
- 总时长约9.8小时
-
数据预处理:
- 音频标准化(16kHz, 16bit)
- 静音切除(VAD)
- 音量归一化
-
标注处理:
- 文本转音素序列
- 声调信息保留
- 对齐检查与修正
4. 实验设计与实现
4.1 实验设置
我们使用CAT工具包进行实验,关键配置如下:
| 参数 | 值 | 说明 |
|---|---|---|
| 模型规模 | 90M | 参数量 |
| 学习率 | 5e-5 | 微调学习率 |
| 批次大小 | 16 | 训练批次 |
| 训练epoch | 50 | 最大训练轮次 |
| 优化器 | AdamW | 带权重衰减 |
4.2 模型微调策略
针对Whistle模型的微调,我们采用了以下策略:
-
声学编码器:
- 保持预训练参数固定
- 仅进行前向计算
- 不参与梯度更新
-
分类层:
- 新增线性投影层
- 部分复用预训练参数
- 随机初始化新音素
-
训练技巧:
- 使用早停策略
- 学习率线性预热
- 梯度裁剪
4.3 评估指标
我们使用以下指标评估模型性能:
-
字错误率(CER):
- 字符级错误率
- 包含声调错误
-
词错误率(WER):
- 词级错误率
- 反映实际识别效果
-
调型错误率(TER):
- 专门评估声调识别
- 对勉语尤为重要
5. 实验结果与分析
5.1 主要结果对比
表1展示了三种预训练方法在勉语测试集上的表现:
| 方法 | CER(%) | WER(%) | TER(%) |
|---|---|---|---|
| 音素监督(Whistle) | 12.3 | 28.7 | 15.2 |
| 子词监督(Whisper) | 15.8 | 34.2 | 19.6 |
| 自监督预训练 | 18.4 | 39.1 | 23.8 |
从结果可以看出,Whistle模型在所有指标上都显著优于其他方法,特别是在声调识别方面优势明显。
5.2 消融实验
为了验证各组件的重要性,我们进行了以下消融实验:
-
参数复用实验:
- 完全随机初始化:CER↑3.2%
- 部分参数复用:最佳效果
-
声调处理实验:
- 忽略声调信息:TER↑8.7%
- 显式建模声调:最佳效果
-
数据量实验:
- 5小时数据:CER↑4.1%
- 10小时数据:接近饱和
5.3 错误分析
通过对识别错误的深入分析,我们发现:
-
常见错误类型:
- 声母混淆(特别是清浊音)
- 韵尾丢失或错误
- 声调识别错误
-
改进方向:
- 加强声调敏感训练
- 引入语言模型约束
- 数据增强策略
6. 实践指导与经验分享
6.1 部署建议
在实际部署Whistle模型时,建议考虑以下因素:
-
计算资源:
- GPU显存需求:≥8GB
- 推理延迟:≈实时×1.2
-
优化技巧:
- 使用半精度推理
- 实现流式识别
- 缓存常用词结果
-
持续学习:
- 收集用户反馈数据
- 定期增量训练
- 模型版本管理
6.2 常见问题解决
以下是我们实践中遇到的典型问题及解决方案:
-
问题:声调识别不稳定
- 原因:训练数据声调分布不均衡
- 解决:重采样平衡各声调样本
-
问题:特定音素错误率高
- 原因:预训练缺少类似音素
- 解决:针对性数据增强
-
问题:推理速度慢
- 原因:模型规模过大
- 解决:知识蒸馏小模型
6.3 扩展应用
Whistle模型还可应用于以下场景:
-
多语言混合识别:
- 同时识别勉语和普通话
- 动态切换语言模型
-
语音合成:
- 作为前端文本转音素
- 提高合成发音准确度
-
语言教育:
- 发音评估与纠正
- 自动生成学习反馈
7. 未来工作方向
基于当前研究成果,我们认为以下方向值得深入探索:
-
声调建模改进:
- 显式声调特征提取
- 声调敏感损失函数
-
数据高效学习:
- 主动学习策略
- 半监督训练方法
-
模型轻量化:
- 模型压缩技术
- 边缘设备部署
在实际应用中,我们发现即使是少量高质量标注数据,配合适当的预训练模型,也能取得令人满意的识别效果。这为更多少数民族语言的语音技术开发提供了可行路径。