大模型工程规范演进与React架构实战解析

1. 大模型工程规范演进与架构设计
作为一名深耕AI领域多年的技术老兵,我见证了从早期提示词工程到如今多智能体架构的完整演进历程。这次分享的React框架实现方案,是我们在饿了么内部经过多次迭代验证的实战成果。不同于市面上泛泛而谈的理论文章,本文将深入剖析ToolCalls+MCP模式的技术细节,并附上可直接复用的核心代码。
大模型工程规范的发展本质上是研发效能不断提升的过程。最初我们仅靠精心设计的prompt来激发模型能力,后来引入RAG(检索增强生成)技术解决知识更新问题。但随着业务复杂度提升,简单的流程编排已无法满足需求。我们开发的"小e"机器人集成30多项大模型指令后,逐渐意识到需要更灵活的架构来应对复杂场景。
2. React模式的核心设计理念
2.1 React模式本质解析
React模式的核心在于建立LLM与环境之间的动态反馈机制。这里的"环境"包含三个关键要素:
- 工具列表:可供调用的功能集合
- 对话上下文:历史交互信息
- 系统变量:运行时的状态参数
这种模式与传统流程编排的最大区别在于决策过程的自主性。如下图所示,模型会根据环境反馈自主决定下一步行动,而非按预设路径执行:
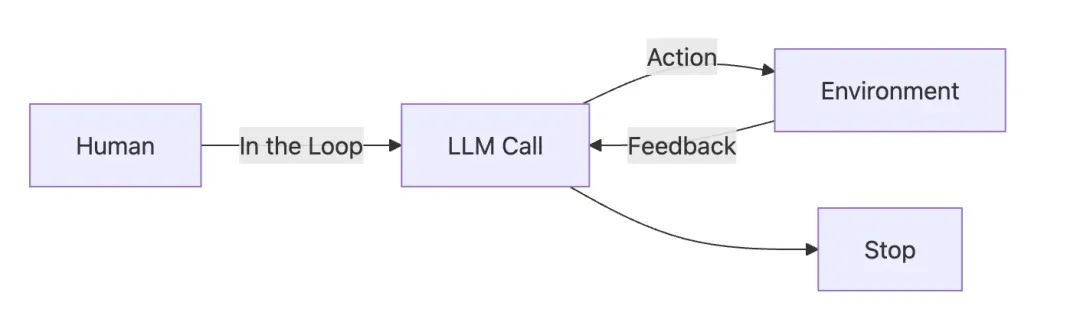
2.2 三种主流决策方案对比
在实现React模式时,我们调研了三种典型方案:
| 方案类型 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 分层代理 | Planning/Controller/Step分工 | 职责清晰 | 架构复杂 |
| OpenAI显式引导 | 强制模型分步输出 | 实现简单 | 灵活性差 |
| Planning As Tool | 将思考作为特殊工具 | 扩展性强 | 需要额外设计 |
我们最终选择Planning As Tool方案,主要基于以下考量:
- 与现有工具系统无缝集成
- 保留最大灵活性的同时降低架构复杂度
- 便于后续扩展为多智能体协作
2.3 上下文管理的挑战与对策
上下文管理是React模式中最容易被忽视却至关重要的环节。我们遇到的主要问题包括:
- Token消耗爆炸式增长(单次对话可达上万token)
- 无关信息导致模型幻觉
- 多轮对话中的信息衰减
解决方案:
python复制# 上下文压缩示例代码
def compress_context(messages, max_tokens=4000):
"""
基于重要性的动态上下文压缩
保留:系统提示、最近对话、关键工具输出
压缩:早期对话、冗余信息
"""
compressed = []
current_length = 0
for msg in sorted(messages, key=lambda x: -x['priority']):
if current_length + len(msg['content']) > max_tokens:
msg['content'] = msg['content'][:max_tokens-current_length] + "...[truncated]"
compressed.append(msg)
current_length += len(msg['content'])
return compressed
3. ToolCalls+MCP架构实现
3.1 技术选型深度解析
放弃SpringAI而选择自研框架的决策过程:
-
SpringAI局限性分析:
- 中间过程黑箱,无法展示决策链路
- 工具调用结果强制返回,不符合平台需求
- 国内模型适配性差(如通义千问特殊参数)
-
原生MCPSDK问题:
- 不支持带鉴权参数的Aone MCP服务
- 缺乏必要的监控和熔断机制
-
最终技术栈:
- 基础框架:React式事件驱动架构
- MCP调用:定制化ElemeMcpClient
- LLM接入:多平台客户端适配层
3.2 系统架构设计详解
规划类Agent的完整执行流程:
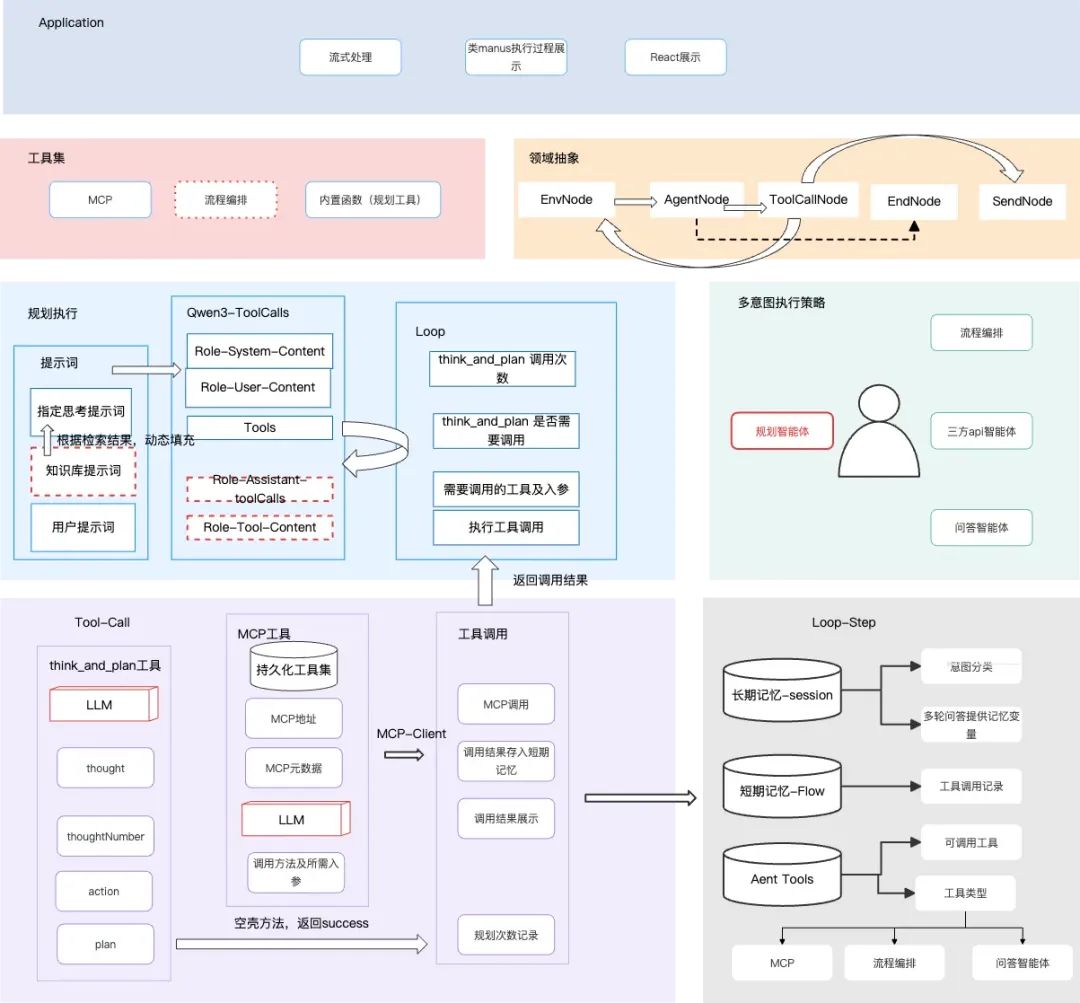
核心组件说明:
-
记忆系统:
- 长期记忆:MongoDB存储对话历史
- 短期记忆:Redis缓存工具调用中间状态
-
执行节点:
- StartNode:初始化执行环境
- ProcessNode:主循环控制器
- ToolManagerNode:工具执行器
- StepNode:执行状态记录
- SendNode:结果格式化输出
-
LLM客户端:
- 抽象工厂模式支持多平台接入
- 自动降级和熔断机制
3.3 关键代码实现
流程控制核心类
java复制// 流程节点基类
public abstract class ReactNode {
protected ReactContext context;
protected ReactNode next;
public abstract void execute();
protected void passToNext() {
if (next != null) {
next.execute();
}
}
}
// StartNode实现
public class StartNode extends ReactNode {
@Override
public void execute() {
// 组装系统提示词
String systemPrompt = buildSystemPrompt();
// 检索RAG片段
List<String> ragResults = retrieveRAG(context.getQuery());
// 调用LLM获取初始响应
LLMResponse initResponse = llmClient.call(
systemPrompt,
ragResults,
context.getTools()
);
context.setCurrentResponse(initResponse);
passToNext();
}
}
工具调用模块
java复制public class ToolManager {
private Map<String, ToolExecutor> toolRegistry;
public ToolResult executeTool(String toolName, Map<String, Object> params) {
ToolExecutor executor = toolRegistry.get(toolName);
if (executor == null) {
throw new ToolNotFoundException(toolName);
}
// 监控工具执行时间
long start = System.currentTimeMillis();
ToolResult result = executor.execute(params);
long duration = System.currentTimeMillis() - start;
// 记录执行指标
MetricRecorder.recordToolCall(toolName, duration, result.isSuccess());
return result;
}
}
LLM客户端工厂
python复制class LLMClientFactory:
@classmethod
def get_client(cls, model_config):
if model_config.platform == "WHALE":
return WhaleClient(model_config)
elif model_config.platform == "IDEALAB":
return IdealabHttpClient(model_config)
elif model_config.platform == "SPRING_AI":
return SpringAIClientWrapper(model_config)
else:
raise ValueError(f"Unsupported platform: {model_config.platform}")
# 客户端基类
class BaseLLMClient(ABC):
@abstractmethod
def call(self, messages, tools=None):
pass
# Whale平台实现
class WhaleClient(BaseLLMClient):
def __init__(self, config):
self.endpoint = config.endpoint
self.api_key = config.api_key
def call(self, messages, tools=None):
payload = {
"model": "gpt-4",
"messages": messages,
"tools": tools or []
}
response = requests.post(
self.endpoint,
json=payload,
headers={"Authorization": f"Bearer {self.api_key}"}
)
return self._parse_response(response.json())
4. 多智能体架构演进
4.1 单智能体到多智能体的必然性
我们在实践中发现单智能体架构存在明显瓶颈:
-
Token效率问题:
- 复杂任务需要拼接大量上下文
- 中心Agent需要处理所有信息
- 平均Token消耗增长呈指数级
-
职责边界模糊:
- 单个Agent需要具备多种能力
- 输出质量难以保证专业性
- 错误排查成本高
4.2 两种多智能体模式对比
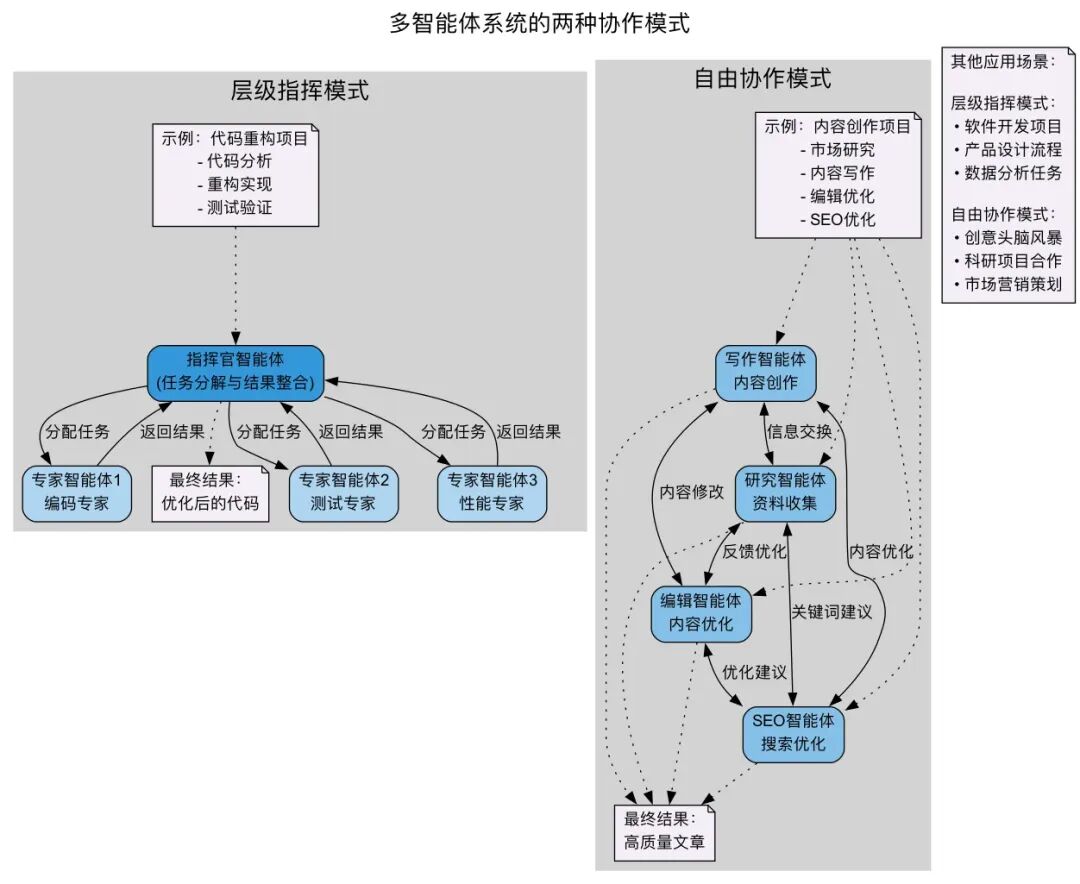
层级调度模式:
- 中心Agent作为调度器
- 将子Agent抽象为特殊工具
- 适合流程明确的业务场景
自由协作模式:
- Agent之间自主交互
- 动态形成解决路径
- 适合开放性问题求解
我们选择层级调度模式的原因:
- 饿了么业务场景需求明确
- 与现有架构兼容性好
- 实施成本和风险可控
4.3 多智能体实现方案
将Agent抽象为工具的代码示例:
java复制public class AgentAsTool implements ToolExecutor {
private Agent targetAgent;
@Override
public ToolResult execute(Map<String, Object> params) {
// 转换参数格式
AgentRequest request = convertParams(params);
// 调用子Agent
AgentResponse response = targetAgent.execute(request);
// 封装返回结果
return new ToolResult(
response.isSuccess(),
response.getOutput(),
response.getMetadata()
);
}
}
上下文共享机制设计:
python复制class ContextManager:
def __init__(self):
self.shared_mem = SharedMemory()
self.lock = threading.Lock()
def update_context(self, agent_id, context):
with self.lock:
current = self.shared_mem.get(agent_id, {})
current.update(context)
self.shared_mem[agent_id] = current
def get_relevant_context(self, agent_id, query):
# 基于向量相似度检索相关上下文
all_context = self.shared_mem.values()
query_embedding = get_embedding(query)
relevant = []
for ctx in all_context:
sim = cosine_similarity(
query_embedding,
ctx['embedding']
)
if sim > 0.7: # 相似度阈值
relevant.append(ctx)
return relevant
5. 关键问题与优化方向
5.1 上下文管理的进阶方案
我们在实践中总结的优化策略:
-
动态压缩算法:
- 基于重要性评分保留关键信息
- 使用文本摘要技术压缩冗余内容
- 示例压缩率可达60%以上
-
分层存储策略:
- 高频访问内容:内存缓存
- 近期对话:Redis存储
- 历史记录:持久化到数据库
-
向量化检索:
- 将上下文转换为向量存储
- 按需检索相关片段
- 显著降低无关信息干扰
5.2 性能优化实战经验
-
Token消耗控制:
- 工具描述精简优化(平均减少40%长度)
- 上下文窗口滑动机制
- 响应流式处理
-
系统稳定性保障:
java复制// 带熔断的工具调用封装 public class ResilientToolInvoker { private CircuitBreaker breaker; private RateLimiter limiter; public ToolResult safeInvoke(ToolCall call) { if (!limiter.tryAcquire()) { throw new RateLimitExceeded(); } return breaker.run(() -> { return toolManager.executeTool( call.getToolName(), call.getParams() ); }, fallback -> { return new ToolResult(false, "Fallback response"); }); } } -
监控指标体系:
- 工具调用成功率/耗时
- LLM响应Token统计
- 异常触发频率
- 上下文压缩效率
5.3 典型问题排查指南
我们遇到的常见问题及解决方案:
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 工具选择错误 | 工具描述不准确 | 优化工具描述模板 |
| 参数解析失败 | 示例参数不足 | 补充更多调用示例 |
| 循环无法终止 | 停止条件不明确 | 明确停止规则和最大迭代次数 |
| 响应质量下降 | 上下文污染 | 加强上下文过滤机制 |
| 执行时间过长 | 工具响应超时 | 设置合理超时阈值 |
6. 架构演进路线图
基于当前实践,我们规划的未来优化方向:
-
智能体能力增强:
- 引入技能学习机制
- 支持动态工具注册
- 实现跨Agent知识共享
-
上下文系统升级:
- 基于RAG的长期记忆
- 注意力机制驱动的信息筛选
- 自动生成执行摘要
-
平台化建设:
- 可视化编排界面
- 性能分析仪表盘
- 自动化测试框架
-
多模态扩展:
- 支持图像理解工具
- 音频处理能力集成
- 跨模态信息融合
这套架构已经在饿了么内部多个业务场景落地,平均提升开发效率3倍以上。特别是在动态性强的场景(如客服、运营策略等)中,React模式展现出显著优势。对于计划构建类似系统的团队,建议先从核心工具链开始建设,逐步扩展智能体能力。