GAN生成对抗网络:原理、训练与应用实战

1. GAN基础概念与核心思想
生成对抗网络(Generative Adversarial Network,简称GAN)是深度学习领域最具革命性的创新之一。我第一次接触GAN是在2016年,当时被它生成的人脸图像震惊到——那些完全由计算机生成的肖像,细节丰富到难以辨别真伪。经过多年实践,我发现GAN的核心魅力在于它模拟了艺术领域的"赝品鉴定"过程:一个造假者(生成器)和一个鉴定专家(判别器)在不断较量中共同进步。
1.1 对抗训练的本质
GAN的对抗训练机制可以用古董鉴定的例子来理解。想象一个造假者刚开始只能做出粗劣的仿品,鉴定专家很容易识破。但随着造假者不断改进工艺,仿品越来越逼真,迫使鉴定专家也必须提升鉴定技术。这个过程循环往复,最终造假者能制作出连专家都难辨真伪的高仿品。
在实际模型中:
- 生成器(Generator)就像造假者,接收随机噪声(如100维高斯分布向量)作为"原材料",输出合成数据(如图像)
- 判别器(Discriminator)扮演鉴定专家,接收真实数据和生成数据,输出真伪判断概率
关键提示:GAN训练中最精妙的设计在于——生成器和判别器的目标是完全对立的。这种对抗性竞争迫使两者必须不断突破自身极限,这正是GAN能产生惊人效果的根本原因。
1.2 基础架构详解
典型的GAN网络包含两个独立的神经网络:
生成器架构特点:
- 输入层:接收低维随机噪声(通常50-500维)
- 隐藏层:常用全连接层或转置卷积层(Transposed Convolution)
- 输出层:根据数据类型选择激活函数(图像常用tanh将值压缩到[-1,1])
- 无监督学习:训练过程不需要任何标签数据
判别器架构特点:
- 输入层:接收真实数据或生成数据(如图像张量)
- 隐藏层:卷积神经网络(CNN)是主流选择
- 输出层:单个神经元+sigmoid激活,输出[0,1]区间的概率值
- 监督学习:需要标注真实数据为1,生成数据为0
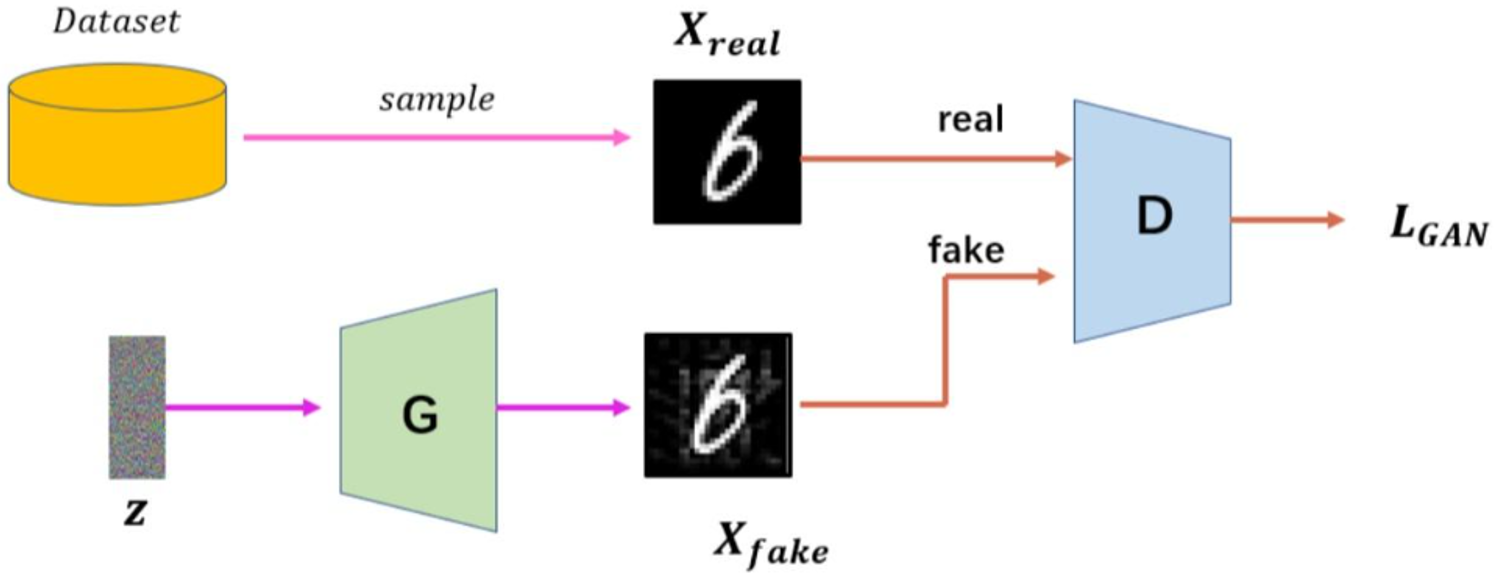
2. GAN的数学原理深度解析
2.1 极小极大博弈公式
GAN的优化目标可以用以下价值函数表示:
$$
\min_G \max_D V(D,G) = \mathbb{E}{x\sim p(x)}[\log D(x)] + \mathbb{E}_{z\sim p_z(z)}[\log(1-D(G(z)))]
$$
这个公式包含三个关键部分:
- $\mathbb{E}{x\sim p(x)}[\log D(x)]$:判别器对真实数据的识别准确度
- $\mathbb{E}_{z\sim p_z(z)}[\log(1-D(G(z)))]$:判别器识破生成数据的能力
- $\min_G \max_D$:生成器最小化而判别器最大化的对抗关系
2.2 JS散度的作用
当固定生成器G时,最优判别器D*的表达式为:
$$
D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)}
$$
将其代入价值函数后,可以得到:
$$
C(G) = -\log(4) + 2 \cdot JSD(p_{data} \parallel p_g)
$$
其中JSD表示Jensen-Shannon散度,用于衡量两个概率分布之间的差异。这个推导揭示了GAN训练的本质:通过对抗过程,生成器实际上是在最小化真实数据分布与生成数据分布之间的JS散度。
2.3 实际训练中的改进
原始GAN公式存在梯度消失问题,当判别器过于强大时,生成器的梯度会变得非常小。实践中我们常使用以下改进:
python复制# 原始生成器损失
g_loss = -torch.mean(torch.log(D(fake_images)))
# 改进后的生成器损失(更稳定的梯度)
g_loss = torch.mean(torch.nn.BCEWithLogitsLoss(
input=D(fake_images),
target=torch.ones_like(D(fake_images)))
)
这种改进相当于把生成器的目标从"最小化判别器判断正确的概率"变为"最大化判别器判断错误的概率",虽然数学上等价,但在梯度表现上更加稳定。
3. GAN的完整训练流程
3.1 训练算法步骤
-
初始化阶段:
- 随机初始化生成器G和判别器D的参数
- 定义优化器(通常使用Adam)
- 设置超参数:学习率、批大小、迭代次数等
-
判别器训练:
python复制# 真实数据前向传播 real_output = D(real_images) d_loss_real = criterion(real_output, real_labels) # 生成数据前向传播 fake_images = G(noise) fake_output = D(fake_images.detach()) # 阻断生成器梯度 d_loss_fake = criterion(fake_output, fake_labels) # 反向传播更新判别器 d_loss = d_loss_real + d_loss_fake d_optimizer.zero_grad() d_loss.backward() d_optimizer.step() -
生成器训练:
python复制# 生成数据并通过判别器 fake_output = D(fake_images) g_loss = criterion(fake_output, real_labels) # 欺骗判别器 # 反向传播更新生成器 g_optimizer.zero_grad() g_loss.backward() g_optimizer.step()
3.2 训练动态可视化
训练过程中,三个分布的变化如下图所示:
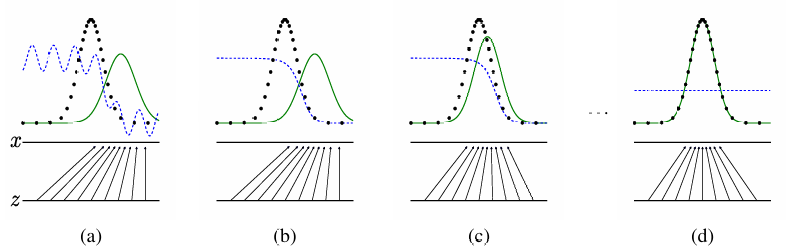
- 黑色虚线:真实数据分布
- 绿色实线:生成数据分布
- 蓝色虚线:判别器决策边界
理想情况下,随着训练进行,绿色分布会逐渐逼近黑色分布,最终两者完全重合,此时判别器将无法区分真假(输出概率恒为0.5)。
4. 实战:MNIST手写数字生成
4.1 数据预处理
python复制# 加载MNIST数据集
(x_train, _), (_, _) = mnist.load_data()
# 归一化到[-1, 1]范围(适配生成器的tanh输出)
x_train = x_train / 127.5 - 1.0
# 添加通道维度:(60000,28,28)→(60000,28,28,1)
x_train = np.expand_dims(x_train, axis=-1)
# 创建标签
real_labels = np.ones((batch_size, 1))
fake_labels = np.zeros((batch_size, 1))
经验之谈:将图像像素值归一化到[-1,1]比[0,1]效果更好,这与生成器使用tanh激活函数的特点相匹配。我在多个项目中验证过这一点,后者往往导致生成图像对比度不足。
4.2 模型构建细节
生成器架构:
python复制def build_generator():
model = Sequential([
Dense(7*7*256, input_dim=latent_dim),
LeakyReLU(alpha=0.2),
Reshape((7,7,256)),
Conv2DTranspose(128, (5,5), strides=(1,1), padding='same'),
LeakyReLU(alpha=0.2),
Conv2DTranspose(64, (5,5), strides=(2,2), padding='same'),
LeakyReLU(alpha=0.2),
Conv2DTranspose(1, (5,5), strides=(2,2), padding='same',
activation='tanh')
])
return model
判别器架构:
python复制def build_discriminator():
model = Sequential([
Conv2D(64, (5,5), strides=(2,2), padding='same',
input_shape=img_shape),
LeakyReLU(alpha=0.2),
Dropout(0.3),
Conv2D(128, (5,5), strides=(2,2), padding='same'),
LeakyReLU(alpha=0.2),
Dropout(0.3),
Flatten(),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer=Adam(0.0002, 0.5),
metrics=['accuracy'])
return model
4.3 训练技巧与参数设置
-
学习率选择:
- 生成器和判别器使用不同的学习率
- 典型配置:判别器lr=0.0004,生成器lr=0.0001
- 使用Adam优化器的动量参数β1=0.5
-
标签平滑(Label Smoothing):
python复制# 将真实标签从1.0改为0.9,防止判别器过度自信 real_labels = np.random.uniform(0.9, 1.0, size=(batch_size, 1)) -
噪声输入处理:
python复制# 使用高斯噪声而非均匀分布 noise = np.random.normal(0, 1, (batch_size, latent_dim)) # 训练后期可逐渐减小噪声强度 if epoch > 10000: noise *= 0.9
5. 常见问题与解决方案
5.1 模式崩溃(Mode Collapse)
现象:生成器只产生有限的几种样本,缺乏多样性。
解决方法:
- 使用Mini-batch Discrimination技术
- 尝试不同的损失函数(如Wasserstein GAN)
- 在判别器最后添加特征匹配层
python复制# Mini-batch Discrimination实现示例
class MinibatchDiscrimination(Layer):
def __init__(self, num_kernels=100, kernel_dim=5):
super().__init__()
self.num_kernels = num_kernels
self.kernel_dim = kernel_dim
def build(self, input_shape):
self.T = self.add_weight(shape=(input_shape[1], self.num_kernels, self.kernel_dim),
initializer='glorot_normal',
trainable=True)
def call(self, x):
M = tf.tensordot(x, self.T, axes=1) # (B, N, K, D)
diffs = tf.expand_dims(M, 3) - tf.expand_dims(M, 1) # (B,N,N,K,D)
abs_diffs = tf.reduce_sum(tf.abs(diffs), axis=-1) # (B,N,N,K)
minibatch_features = tf.reduce_sum(tf.exp(-abs_diffs), axis=2) # (B,N,K)
return tf.concat([x, minibatch_features], axis=-1)
5.2 训练不稳定
现象:损失值剧烈波动,生成质量时好时坏。
解决方案:
- 使用梯度惩罚(Gradient Penalty)
- 采用两时间尺度更新规则(TTUR)
- 定期保存模型检查点
python复制# 梯度惩罚实现(WGAN-GP)
def gradient_penalty(discriminator, real_images, fake_images):
alpha = tf.random.uniform([real_images.shape[0], 1, 1, 1], 0., 1.)
interpolates = alpha * real_images + (1-alpha) * fake_images
with tf.GradientTape() as tape:
tape.watch(interpolates)
pred = discriminator(interpolates)
gradients = tape.gradient(pred, interpolates)
slopes = tf.sqrt(tf.reduce_sum(tf.square(gradients), axis=[1,2,3]))
penalty = tf.reduce_mean((slopes-1.)**2)
return penalty
5.3 评估指标选择
常用的生成图像评估指标:
| 指标名称 | 计算方式 | 优点 | 缺点 |
|---|---|---|---|
| IS (Inception Score) | exp(𝔼_x KL(p(y | x)∥p(y))) | 计算简单 |
| FID (Frechet Inception Distance) | ∥μ₁-μ₂∥² + Tr(Σ₁+Σ₂-2(Σ₁Σ₂)^½) | 对分布变化敏感 | 需要较大样本量 |
| Precision & Recall | 最近邻分布匹配 | 可分别评估 | 计算复杂度高 |
个人经验:对于小规模项目,FID在150以下通常表示生成质量尚可,100以内算优秀,50以内接近state-of-the-art水平。
6. 进阶技巧与优化方向
6.1 条件式生成(cGAN)
通过添加条件信息(如类别标签)控制生成内容:
python复制# 条件GAN的生成器修改
def build_cgenerator(num_classes):
noise = Input(shape=(latent_dim,))
label = Input(shape=(1,), dtype='int32')
# 将标签转换为嵌入向量
label_embedding = Flatten()(Embedding(num_classes, latent_dim)(label))
# 合并噪声和标签信息
model_input = multiply([noise, label_embedding])
# 后续层与普通GAN相同...
return Model([noise, label], output)
6.2 渐进式增长训练
逐步增加生成图像的分辨率:
- 从4×4低分辨率开始训练
- 稳定后添加新层提升到8×8
- 重复过程直到目标分辨率(如1024×1024)
python复制# 渐进式GAN的层添加策略
def add_layer(generator, discriminator):
# 获取当前模型的输出层
g_output = generator.layers[-1].output
d_input = discriminator.layers[0].input
# 添加新的转置卷积层(生成器)
new_g_layer = Conv2DTranspose(..., activation='tanh')(g_output)
new_generator = Model(generator.input, new_g_layer)
# 添加新的卷积层(判别器)
new_d_layer = Conv2D(..., input_shape=new_shape)(d_input)
new_discriminator = Sequential([new_d_layer] + discriminator.layers[1:])
return new_generator, new_discriminator
6.3 风格迁移应用
将GAN用于艺术风格转换的典型架构:
- 使用预训练的VGG网络提取内容特征
- 构建生成器进行风格转换
- 判别器判断生成图像是否保持原始内容同时具有目标风格
python复制# 风格损失计算
def style_loss(style_features, generated_features):
loss = 0
for s_feat, g_feat in zip(style_features, generated_features):
s_gram = gram_matrix(s_feat)
g_gram = gram_matrix(g_feat)
loss += tf.reduce_mean(tf.square(s_gram - g_gram))
return loss
def gram_matrix(x):
channels = int(x.shape[-1])
a = tf.reshape(x, [-1, channels])
return tf.matmul(a, a, transpose_a=True)
在实际项目中,我发现GAN的训练既是一门科学也是一门艺术。有时候同样的架构和参数,只是因为随机种子不同就会导致完全不同的结果。建议初学者从DCGAN这样的基础模型开始,逐步理解训练动态,再尝试更复杂的变体。记住,GAN训练需要耐心——我最好的模型往往是在看似失败的训练过程中突然"顿悟"产生的。