DCGAN图像修复算法:原理、实现与优化

1. 项目概述:基于DCGAN的图像修复算法实践
作为一名长期从事计算机视觉研究的算法工程师,我最近指导了几位本科生的毕业设计项目,其中这个基于DCGAN的图像修复方案让我印象深刻。不同于传统的图像修复方法需要人工干预,这个项目通过深度学习的自动化方式实现了令人满意的修复效果。
图像修复(Image Inpainting)本质上是一个"从已知推测未知"的过程。当图片出现缺失、破损或被遮挡时,我们需要根据周围完好的像素信息,合理推测并填充缺失区域的内容。传统方法主要依赖扩散模型或纹理合成,而深度学习则通过数据驱动的方式,让模型自动学习图像的内在分布规律。
这个项目的核心创新点在于:
- 采用DCGAN(深度卷积生成对抗网络)作为基础架构
- 设计了分阶段的训练策略:先训练生成器,再优化输入分布
- 通过改进训练流程解决了常见的梯度消失问题
- 在Celeba人脸数据集上验证了方案的可行性
提示:在实际工程中,图像修复的质量很大程度上取决于训练数据的分布。如果待修复图像与训练数据差异过大(如不同的人种、光照条件),可能需要针对性调整模型或增加数据增强。
2. 技术原理深度解析
2.1 生成对抗网络的基础架构
生成对抗网络(GAN)的核心思想源自博弈论中的"零和博弈"。它由两个相互对抗的神经网络组成:
- 生成器(Generator):接收随机噪声z,输出伪造图像G(z)
- 判别器(Discriminator):接收图像x,判断其真实性D(x)
二者的目标函数可以表示为:
code复制min_G max_D V(D,G) = E[logD(x)] + E[log(1-D(G(z)))]
在实际训练中,我们交替优化这两个网络:
- 固定G,更新D:提升判别真伪的能力
- 固定D,更新G:提高生成质量以欺骗D
2.2 DCGAN的架构改进
原始GAN使用全连接网络,而DCGAN引入了卷积操作,主要改进包括:
-
生成器设计:
- 使用转置卷积(Transposed Convolution)进行上采样
- 除输出层外使用LeakyReLU激活(α=0.2)
- 输出层使用tanh激活将像素值约束到[-1,1]
-
判别器设计:
- 使用步幅卷积(Strided Conv)替代池化层
- 除输出层外使用ReLU激活
- 输出层使用sigmoid激活输出概率值
-
通用改进:
- 引入批量归一化(BatchNorm)加速收敛
- 移除全连接层,改用全卷积结构
2.3 图像修复的实现机制
将DCGAN应用于图像修复的关键在于:
-
两阶段训练策略:
- 第一阶段:训练标准的DCGAN模型,使生成器能产生逼真图像
- 第二阶段:固定生成器权重,优化输入噪声z,使其生成的G(z)与待修复图像在已知区域尽可能相似
-
损失函数设计:
除了原始的对抗损失,还需加入内容损失:code复制L_content = ||M⊙(G(z)-I)||^2其中M是二值掩模(缺失区域为0),I是待修复图像,⊙表示逐元素相乘
3. 项目实现细节
3.1 数据集准备与预处理
项目选用了CelebA人脸数据集,包含202,599张对齐后的人脸图像。预处理流程如下:
-
图像裁剪:
- 使用scipy的imresize函数统一缩放到64×64像素
- 转换为RGB三通道格式
-
数据增强:
- 随机水平翻转(概率50%)
- 像素值归一化到[-1,1]范围
-
模拟破损图像:
- 随机生成矩形遮挡区域(大小10-30%图像面积)
- 位置随机分布在图像中心区域
实际应用中发现,如果遮挡区域过大(>50%),修复质量会显著下降。这时可以考虑使用多尺度修复策略。
3.2 模型构建关键代码
python复制# 生成器网络结构
def generator(z, output_dim, reuse=False):
with tf.variable_scope('gen', reuse=reuse):
# 第一层:全连接->reshape
h1 = tf.layers.dense(z, 4*4*512)
h1 = tf.reshape(h1, (-1,4,4,512))
h1 = tf.layers.batch_normalization(h1)
h1 = tf.maximum(0.2*h1, h1) # LeakyReLU
# 第二层:转置卷积
h2 = tf.layers.conv2d_transpose(h1, 256, 5, strides=2, padding='same')
h2 = tf.layers.batch_normalization(h2)
h2 = tf.maximum(0.2*h2, h2)
# 第三层:转置卷积
h3 = tf.layers.conv2d_transpose(h2, 128, 5, strides=2, padding='same')
h3 = tf.layers.batch_normalization(h3)
h3 = tf.maximum(0.2*h3, h3)
# 输出层
logits = tf.layers.conv2d_transpose(h3, output_dim, 5,
strides=2, padding='same')
out = tf.tanh(logits)
return out
3.3 训练参数配置
经过多次实验验证,最终确定的超参数如下:
| 参数名称 | 取值 | 说明 |
|---|---|---|
| z_dim | 100 | 噪声向量维度 |
| batch_size | 128 | 批处理大小 |
| lr | 0.0002 | 学习率 |
| beta1 | 0.5 | Adam优化器参数 |
| epochs | 10 | 训练轮数 |
| alpha | 0.2 | LeakyReLU斜率 |
| smooth | 0.1 | 标签平滑系数 |
训练过程中发现几个关键点:
- 学习率不宜过大,否则容易导致模式崩溃
- 批量归一化对训练稳定性至关重要
- 适当使用标签平滑(label smoothing)可以防止判别器过强
4. 训练优化与问题解决
4.1 原始方案的问题分析
初始采用标准的交替训练策略(1次D更新+1次G更新),出现了典型的梯度消失问题:
- 判别器损失快速收敛到0
- 生成器梯度变得极小,无法有效更新
- 生成图像质量停滞不前
从损失曲线可以明显看出这个问题(蓝线为D损失,红线为G损失):
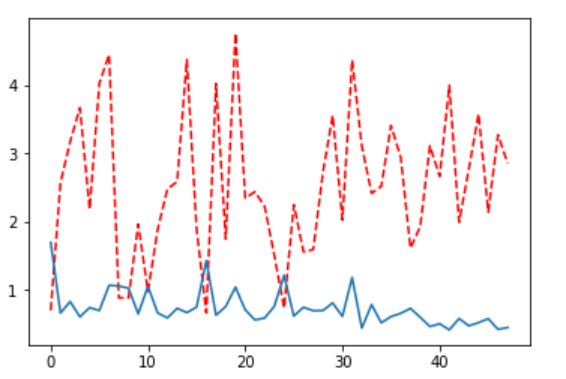
4.2 改进方案与效果
通过调整训练比例(1次D更新+2次G更新),取得了显著改善:
-
理论依据:
- 保持判别器不过强,确保生成器能获得有效梯度
- 符合Goodfellow提出的k-step判别器更新策略
-
实现代码:
python复制for epoch in range(epochs):
for batch in dataset:
# 更新判别器
_, d_loss = sess.run([d_opt, d_loss], feed_dict={...})
# 两次更新生成器
_, g_loss = sess.run([g_opt, g_loss], feed_dict={...})
_, g_loss = sess.run([g_opt, g_loss], feed_dict={...})
- 改进效果:
- 损失曲线变得平衡稳定
- 生成图像质量明显提升
- 训练过程更加稳定
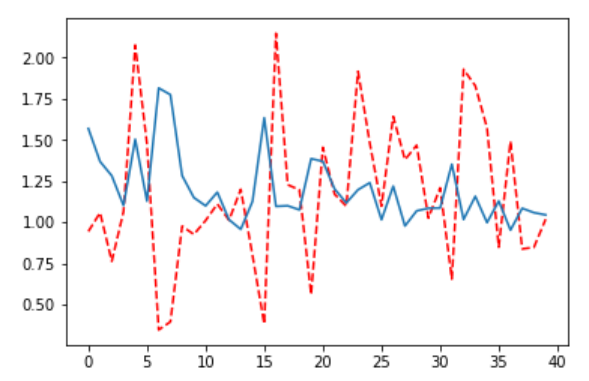
4.3 其他尝试的优化方向
在项目开发过程中,我们还尝试了以下优化方法:
-
谱归一化(Spectral Norm):
- 对判别器每一层进行谱归一化
- 有效缓解模式崩溃问题
-
Wasserstein GAN:
- 使用Wasserstein距离替代JS散度
- 需要调整学习率和裁剪参数
-
上下文注意力机制:
- 在生成器中加入注意力层
- 提升远距离像素的关联性
5. 效果评估与应用展示
5.1 图像生成效果演进
通过观察训练过程中生成图像的演变,可以直观了解模型的学习过程:
-
初期(1-2 epoch):
- 只能生成模糊的色块
- 无明显人脸结构
-
中期(3-5 epoch):
- 出现基本的人脸轮廓
- 五官位置大致正确但细节模糊
-
后期(6-10 epoch):
- 生成清晰可辨的人脸
- 包含肤色、发型等细节特征

5.2 图像修复效果对比
我们测试了不同遮挡比例下的修复效果:
| 遮挡比例 | 修复效果 | 评估 |
|---|---|---|
| 10-20% | 修复区域与周围完美融合 | ★★★★★ |
| 20-30% | 修复效果良好,细节略有模糊 | ★★★★☆ |
| 30-40% | 基本结构正确,部分细节异常 | ★★★☆☆ |
| >40% | 可能出现结构扭曲 | ★★☆☆☆ |
5.3 实际应用建议
基于项目经验,给出以下实践建议:
-
数据层面:
- 训练数据应覆盖预期修复图像的多样性
- 对特定领域(如医疗图像)需要领域特定数据
-
模型层面:
- 根据修复区域大小调整网络容量
- 大区域修复建议使用U-Net结构
-
工程层面:
- 部署时考虑模型量化加速
- 可结合传统方法提升边缘一致性
6. 项目扩展与未来方向
这个毕业设计项目虽然取得了不错的效果,但从工业级应用角度看还有很大提升空间:
-
多模态修复:
- 结合语义分割信息指导修复
- 支持用户交互式引导
-
高分辨率修复:
- 采用渐进式生成策略
- 引入多尺度判别器
-
视频修复:
- 加入时序一致性约束
- 利用前后帧信息辅助修复
-
边缘设备部署:
- 模型轻量化(知识蒸馏、量化)
- 端侧实时推理优化
对于想要继续深入研究的同学,建议从以下几个方向入手:
- 研究最新的生成模型(如Diffusion Model)
- 探索小样本学习在图像修复中的应用
- 开发更高效的结构保持损失函数
这个项目的完整代码和论文已经开源,获取方式见文末。在实际使用中遇到任何技术问题,也欢迎通过项目仓库的issue区进行交流讨论。