大模型核心概念与工程实践全解析

1. 大模型基础概念解析:从零开始理解AI核心组件
作为一名长期奋战在AI研发一线的工程师,我经常遇到刚入行的同事对大模型领域各种术语感到困惑。今天我就用最直白的语言,带大家彻底搞懂这些核心概念。
1.1 LLM:大语言模型的本质
LLM(Large Language Model)即大语言模型,是当前AI技术的核心引擎。很多人把它想象成"电子大脑",但实际上它就是一个超大规模的概率预测系统。
举个例子,当你输入"今天天气"时,模型并不是"理解"了天气这个概念,而是在计算"今天天气"后面最可能出现的词是什么。可能是"很好"、"不错"或是"很糟糕",这取决于它训练时见过的数据分布。
关键理解:LLM的本质是下一个token预测器,不是真正的理解
1.2 Transformer架构:大模型的基石
2017年Google提出的Transformer架构彻底改变了NLP领域。其核心创新是自注意力机制(Self-Attention),它允许模型在处理每个词时都能考虑到输入序列中的所有其他词。
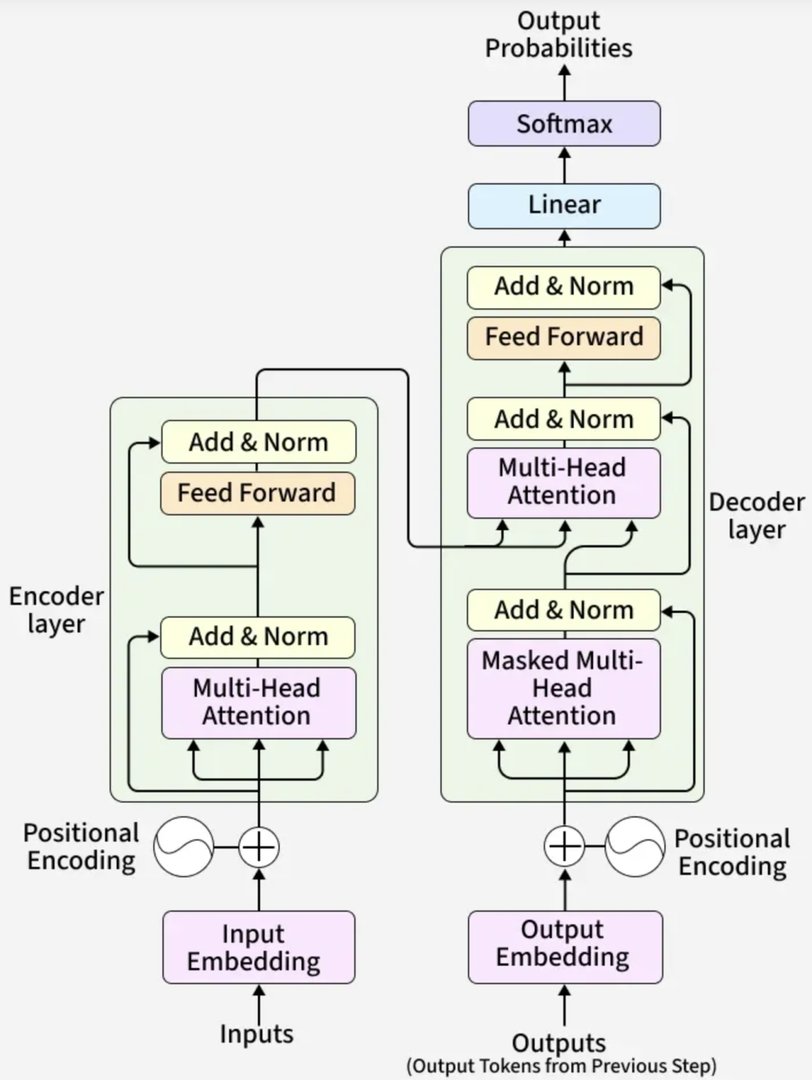
实际工程中,我们主要关注三个关键点:
- 多头注意力机制如何并行处理信息
- 位置编码如何保留序列顺序
- 残差连接如何解决梯度消失问题
1.3 Token:模型处理的最小单位
Token是模型实际处理的基本单元,不是我们理解的"词语"。中文的tokenization(分词)尤其复杂:
- "工程师"可能被分成"工程"+"师"
- "智能工作室"可能被分成"智能"+"工作"+"室"
python复制# 使用HuggingFace的tokenizer示例
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
print(tokenizer.tokenize("智能工作室")) # 输出:['智', '能', '工', '作', '室']
这种切分方式会导致:
- 中文文本的token数量通常比肉眼看到的"词"多30-50%
- 长文本的成本计算需要特别注意
1.4 Context Window:模型的"工作记忆"
Context Window(上下文窗口)决定了模型一次能处理多少信息。就像人的短期记忆有限一样,模型也有这个限制。
常见模型的上下文窗口大小:
- GPT-3.5: 4k tokens
- GPT-4: 32k tokens
- Claude 3: 200k tokens
- 一些开源模型: 4k-128k不等
在实际应用中,我们需要:
- 估算输入输出的token总量
- 设计系统时考虑长文本处理策略
- 对超长文档采用分块处理等技巧
2. 大模型工作原理深度剖析
2.1 文本生成机制:逐token预测
大模型的文本生成是典型的自回归过程:
- 接收输入文本
- 预测下一个最可能的token
- 将预测的token追加到输入
- 重复直到生成结束标记
mermaid复制graph LR
A[输入文本] --> B[编码为token]
B --> C[模型计算]
C --> D[预测概率分布]
D --> E[采样下一个token]
E --> F[追加到输入]
F --> C
这个机制解释了为什么AI回答是一个词一个词"蹦"出来的——因为这就是它真实的工作方式。
2.2 温度参数(Temperature)控制
温度参数影响生成多样性:
- 低温度(0.1-0.5):确定性高,适合事实性回答
- 中温度(0.7-1.0):平衡创意和准确
- 高温度(1.0以上):高度随机,适合创意写作
python复制# 生成文本时的温度设置示例
output = model.generate(
input_ids,
temperature=0.7,
max_length=100
)
2.3 停止条件设计
实际工程中需要设置合理的停止条件:
- 最大长度限制(max_length)
- 结束标记(eos_token_id)
- 重复检测(repetition_penalty)
- 质量阈值(top_p/top_k)
3. Prompt工程实战技巧
3.1 System Prompt设计原则
System Prompt是控制模型行为的核心手段。好的系统提示应该:
- 明确角色定位
- 规定回答格式
- 设定安全边界
- 提供示例(可选)
markdown复制你是一个专业的AI助手,遵守以下规则:
- 用中文回答
- 保持专业但友好的语气
- 不确定时明确告知
- 拒绝任何违法请求
回答格式:
【总结】用一句话概括
【详情】分点说明
【注意】重要提醒
3.2 用户Prompt优化技巧
根据我的实战经验,有效的用户Prompt应该:
- 明确任务目标
- 指定输出格式
- 提供背景信息
- 给出示例(复杂任务时)
对比示例:
❌ "写篇关于AI的文章"
✅ "写一篇800字的技术科普,面向大学生解释Transformer架构,包含:1)核心思想 2)关键组件 3)应用示例"
3.3 多轮对话管理
在实际对话系统中,需要精心设计:
- 对话历史管理策略
- 上下文窗口优化
- 记忆机制实现
- 话题切换检测
python复制# 简化的对话历史管理
def manage_context(messages, new_message, max_tokens=4000):
messages.append(new_message)
while calculate_tokens(messages) > max_tokens:
messages.pop(0) # 移除最早的消息
return messages
4. 工具调用与Agent系统
4.1 工具(Tool)集成模式
工具调用使模型突破纯文本限制。典型集成方式:
- 描述工具功能(名称、参数、返回值)
- 让模型决定何时调用
- 执行工具并返回结果
- 模型整合结果生成回答
json复制// 工具定义示例
{
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"city": {"type": "string", "description": "城市名称"},
"date": {"type": "string", "description": "日期"}
}
}
4.2 Agent系统架构
现代Agent系统通常包含:
- 规划模块(Plan):分解任务
- 记忆模块(Memory):存储状态
- 工具模块(Tools):执行动作
- 反思模块(Reflect):评估改进
mermaid复制graph TB
User[用户输入] --> Agent
Agent --> Plan[任务规划]
Plan --> Action[工具调用]
Action --> Observe[观察结果]
Observe --> Reflect[反思评估]
Reflect --> Agent
Agent --> User[输出结果]
4.3 实际开发中的挑战
根据我的项目经验,构建可靠Agent需要解决:
- 长程依赖问题
- 错误传播控制
- 工具调用可靠性
- 成本与延迟平衡
5. 大模型应用开发实战
5.1 典型技术栈选择
现代大模型开发生态:
| 类别 | 常用工具 |
|---|---|
| 开发框架 | LangChain, LlamaIndex, SemanticKernel |
| 本地模型 | LLaMA, ChatGLM, Qwen |
| 云服务 | OpenAI, Anthropic, 文心一言 |
| 向量数据库 | Pinecone, Milvus, Chroma |
5.2 RAG系统实现要点
检索增强生成(RAG)的关键组件:
- 文档分块策略
- 向量嵌入模型
- 检索算法优化
- 结果重排序
python复制# 简化的RAG流程
def rag_query(question, docs):
query_embedding = embed(question)
doc_embeddings = [embed(doc) for doc in docs]
scores = cosine_similarity(query_embedding, doc_embeddings)
best_doc = docs[scores.argmax()]
return generate_answer(question, best_doc)
5.3 性能优化技巧
经过多个项目验证的有效方法:
- 缓存常用查询结果
- 预计算文档嵌入
- 分层检索策略
- 异步处理机制
6. 大模型学习路径建议
6.1 分阶段学习计划
根据我带团队的经验,建议学习路径:
| 阶段 | 内容 | 时长 |
|---|---|---|
| 基础 | Transformer原理/Prompt工程 | 2-4周 |
| 中级 | 工具调用/Agent开发 | 4-8周 |
| 高级 | 模型微调/系统优化 | 8-12周 |
| 专家 | 分布式训练/架构设计 | 12周+ |
6.2 推荐实践项目
从易到难的练手项目:
- 智能客服对话系统
- 文档问答助手
- 自动化数据分析工具
- 多Agent协作系统
6.3 常见陷阱与解决方案
我踩过的坑及应对方法:
- 上下文溢出:实现动态上下文管理
- 工具调用失败:添加重试和后备机制
- 生成质量不稳定:调整温度参数和采样策略
- 成本失控:实施用量监控和限流
7. 行业应用与未来展望
7.1 典型应用场景
已验证的商业化方向:
- 客户服务自动化
- 内容生成与优化
- 代码辅助开发
- 数据分析与洞察
7.2 技术发展趋势
从工程角度看未来方向:
- 多模态能力融合
- 小模型+大模型协同
- 边缘计算部署
- 自主Agent生态系统
7.3 负责任AI实践
必须重视的伦理问题:
- 偏见检测与缓解
- 事实核查机制
- 隐私保护设计
- 透明可解释性
在实际项目中,我们建立了完整的AI治理流程:
- 数据来源审查
- 输出内容过滤
- 人工审核通道
- 持续监控迭代
8. 开发者成长建议
8.1 核心能力培养
根据行业需求,建议重点发展:
- 系统工程思维
- 问题分解能力
- API设计能力
- 性能调优经验
8.2 学习资源推荐
我亲自验证过的优质资源:
- 理论:《Attention Is All You Need》原论文
- 实践:HuggingFace Transformers文档
- 工程:LangChain官方教程
- 前沿:arXiv上的最新论文
8.3 职业发展路径
典型的大模型工程师成长轨迹:
- 初级:API调用/Prompt工程
- 中级:系统集成/性能优化
- 高级:架构设计/模型调优
- 专家:技术战略/团队管理
在团队建设中,我们发现最稀缺的是既懂AI原理又能解决实际工程问题的复合型人才。建议开发者保持:
- 每周至少20%时间学习新技术
- 每月完成1个实践项目
- 每季度深入钻研1个专业领域
9. 技术疑难解答
9.1 常见问题排查
高频问题及解决方法:
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 生成内容无关 | Prompt不清晰 | 优化Prompt结构 |
| 回答突然变差 | 上下文污染 | 清理对话历史 |
| 工具调用失败 | 参数格式错误 | 添加参数验证 |
| 响应时间过长 | 模型过大/网络延迟 | 启用流式响应/缓存 |
9.2 性能优化检查表
系统调优的黄金法则:
- [ ] 上下文长度优化
- [ ] 缓存策略评估
- [ ] 异步处理实现
- [ ] 批量请求处理
- [ ] 硬件加速利用
9.3 安全防护措施
必须实施的安全机制:
- 输入过滤(防注入攻击)
- 输出审查(防有害内容)
- 用量限制(防滥用)
- 审计日志(可追溯性)
10. 实战案例解析
10.1 智能客服系统构建
某电商平台的实现方案:
-
架构:
- 前端:Web/App接口
- 中间层:对话管理
- 后端:大模型+业务API
-
关键创新:
- 动态上下文窗口
- 多轮对话状态跟踪
- 业务工具无缝集成
-
效果:
- 客服人力成本降低60%
- 响应速度提升5倍
- 满意度提高20%
10.2 技术文档助手开发
为IT公司打造的内部工具:
-
功能:
- 代码库搜索
- API文档问答
- 错误解决方案推荐
-
技术栈:
- LLaMA2 13B本地部署
- Milvus向量数据库
- 自定义检索排序算法
-
挑战解决:
- 长文档处理:分块+摘要
- 专业术语:领域微调
- 权限控制:RBAC集成
11. 进阶技术探索
11.1 模型微调实战
定制化模型的典型流程:
- 数据准备(1k-100k样本)
- 环境配置(GPU集群)
- 训练参数调整(LR, BS等)
- 评估指标设定
- 部署优化
python复制# 使用HuggingFace微调示例
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
learning_rate=5e-5,
evaluation_strategy="epoch"
)
11.2 量化与压缩技术
模型优化的关键手段:
-
量化:FP32 → INT8
- 减少75%内存占用
- 加速2-3倍推理
-
剪枝:移除冗余参数
- 可减少30-50%参数量
- 保持90%+准确率
-
蒸馏:大模型→小模型
- 保留核心知识
- 提升推理效率
11.3 多模态系统设计
结合视觉与语言的最新实践:
- CLIP风格的跨模态编码
- 视觉问答系统架构
- 图文生成技术要点
- 多模态检索优化
12. 工程化部署要点
12.1 生产环境考量
必须提前规划的关键因素:
- 延迟:响应时间SLA
- 吞吐:QPS容量规划
- 成本:推理资源优化
- 可靠:容错降级方案
12.2 监控体系构建
核心监控指标:
- 性能指标:延迟/吞吐/错误率
- 质量指标:回答相关性/事实准确性
- 业务指标:转化率/用户满意度
- 成本指标:Token消耗/GPU利用率
12.3 持续交付流程
AI系统的CI/CD实践:
- 模型版本管理
- 自动化测试套件
- 灰度发布策略
- A/B测试框架
13. 团队协作最佳实践
13.1 开发流程优化
高效协作的关键:
- 统一开发环境
- 模块化设计
- 文档即代码
- 知识共享机制
13.2 技能矩阵建设
理想团队构成:
| 角色 | 技能要求 | 人员配比 |
|---|---|---|
| 算法工程师 | 模型调优/评估 | 20% |
| 后端开发 | 系统架构/API设计 | 30% |
| 数据工程师 | 数据处理/特征工程 | 20% |
| 产品经理 | AI产品设计/用户体验 | 15% |
| 测试工程师 | 质量保障/效果评估 | 15% |
13.3 项目管理经验
从实际项目中总结的要点:
- 迭代周期控制在2-4周
- 每日站立会议保持同步
- 技术债务定期清理
- 风险提前识别应对
14. 成本控制策略
14.1 资源使用分析
典型成本构成:
- 模型API调用费(70-80%)
- 基础设施成本(15-20%)
- 开发运维人力(5-10%)
14.2 优化手段对比
各种方法的性价比分析:
| 方法 | 节省效果 | 实现难度 | 适用场景 |
|---|---|---|---|
| 缓存常用响应 | 30-50% | 低 | 高重复查询 |
| 模型量化 | 40-60% | 中 | 本地部署 |
| 智能流量调度 | 20-40% | 高 | 混合模型环境 |
| 预计算+离线处理 | 50-70% | 中 | 非实时任务 |
14.3 预算规划建议
根据业务规模的建议配置:
- 初创阶段:优先使用云服务API
- 成长阶段:混合部署(云+本地)
- 成熟阶段:自建训练推理集群
15. 法律合规指南
15.1 数据隐私保护
必须遵守的规范:
- GDPR(欧盟)
- CCPA(加州)
- 个人信息保护法(中国)
- 行业特定法规
15.2 内容审核要求
关键控制点:
- 输入过滤
- 输出审查
- 用户举报机制
- 内容溯源能力
15.3 知识产权策略
建议采取的措施:
- 训练数据授权审查
- 生成内容版权声明
- 第三方模型合规使用
- 专利布局规划
16. 新兴技术前瞻
16.1 自主Agent进展
最前沿的探索方向:
- 长期记忆实现
- 自我反思能力
- 多Agent协作
- 现实世界交互
16.2 新型架构突破
值得关注的技术:
- Mixture of Experts
- 递归记忆网络
- 神经符号系统
- 能量基础模型
16.3 硬件加速创新
改变游戏规则的发展:
- 光学计算芯片
- 存内计算架构
- 量子计算应用
- 神经形态硬件
17. 开发者社区建设
17.1 知识体系构建
建议的学习循环:
- 理论学习 → 2. 实践验证 →
- 问题解决 → 4. 经验分享 →
- 反馈改进 → (回到1)
17.2 开源贡献指南
入门级贡献建议:
- 文档改进
- 示例代码
- Bug修复
- 测试用例
17.3 技术影响力打造
个人品牌建设路径:
- 技术博客
- 开源项目
- 会议演讲
- 行业标准参与
18. 终极学习建议
根据我带过上百名开发者的经验,最后给出三条黄金法则:
- 深度优先:选一个细分领域做到极致
- 以用促学:通过实际项目驱动进步
- 教学相长:通过分享巩固自身理解
大模型技术正在以月为单位迭代更新,保持学习的最佳方式是成为生态的积极参与者而非旁观者。从今天开始,选择一个感兴趣的方向深入钻研,三个月后你将会惊讶于自己的成长。