电商推荐系统中的级联延迟反馈建模技术解析

1. 级联延迟反馈建模的背景与挑战
在电商推荐系统中,转化率(CVR)预估一直是个棘手的问题。想象一下这样的场景:用户点击了商品广告,可能当天就完成购买,也可能过了一周才下单,甚至购买后又申请退款。这种从点击到最终确定转化的时间差,就是我们常说的"延迟反馈"问题。
传统CVR预估主要关注"点击-转化"这一单阶段过程,但现实业务中出现了更复杂的场景。以淘宝为例,平台不仅需要知道用户是否会购买(CVR),还需要知道购买后是否会退款(NetCVR),以及最终能带来多少交易额(GMV)。这些后链路指标预估面临着"级联延迟反馈"的新挑战:
-
多阶段耦合的延迟问题:NetCVR需要同时建模"点击-转化"和"转化-退款"两个阶段的延迟,而GMV预估还要考虑用户可能多次购买(复购)带来的连续延迟。
-
数据观测的偏置问题:在模型训练时,我们只能看到当前已经确定的转化和退款数据,那些尚未完成决策的用户行为会被错误地标记为负样本。这种偏置在多个延迟阶段叠加时会更加严重。
-
任务特性的差异问题:CVR/NetCVR是二分类问题,GMV是回归问题,传统的单阶段延迟反馈解决方案无法直接迁移应用。
实际业务中,我们发现NetCVR预估的延迟反馈窗口平均达到72小时,而约35%的退款行为发生在购买后24小时内。这种复杂的时间分布使得简单的时间窗口划分方法完全失效。
2. 解决方案的整体设计思路
面对级联延迟反馈的挑战,阿里妈妈团队提出了系统性的解决方案,其核心创新点可以概括为"一个基础,两个框架":
2.1 数据基础:构建行业首个级联延迟反馈数据集
研究团队开源了CASCADE和TRACE两个数据集,填补了行业空白:
- CASCADE:包含4100万点击、370万转化和200万退款记录,精确记录了从点击到转化再到退款的全链路时间戳
- TRACE:首个GMV预估专用数据集,标注了每次点击带来的多次购买行为及对应金额
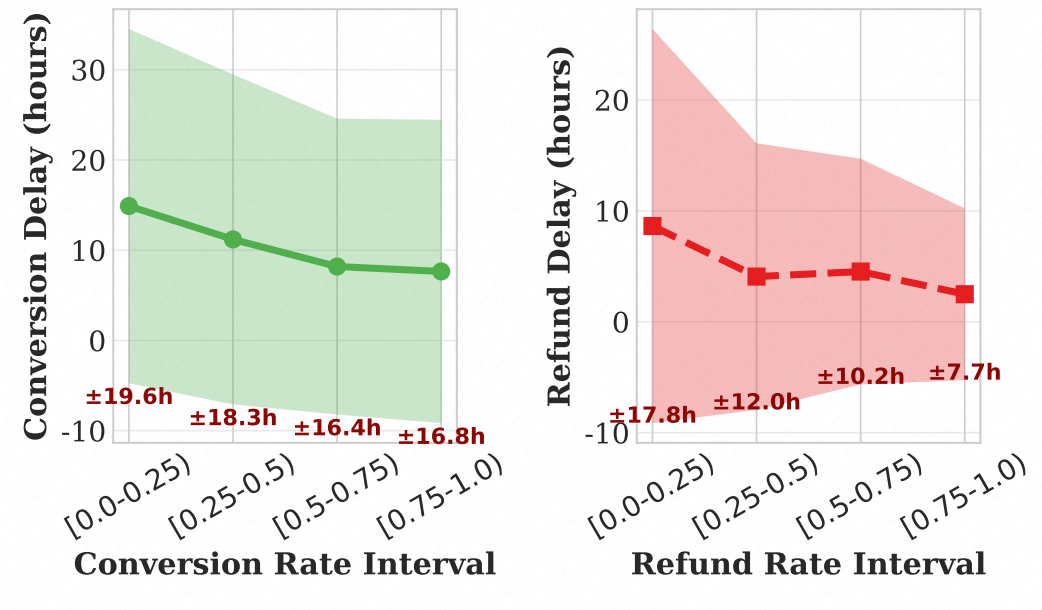
这两个数据集的最大特点是支持15分钟粒度的流式训练评估,能真实模拟工业场景下的数据延迟情况。下图展示了CASCADE数据集中转化与退款延迟的分布情况:
2.2 TESLA框架:NetCVR预估的级联建模
针对NetCVR预估,团队提出了TESLA框架,其核心思想是:
- 级联建模:将NetCVR分解为CVR(转化率)和RFR(退款率)两个子任务联合建模
- 分阶段纠偏:分别对"点击-转化"和"转化-退款"两个阶段的延迟进行校正
- 延迟感知训练:设计特殊的损失函数,让模型更关注延迟时间短的"高置信度"样本
2.3 READER框架:GMV预估的复购感知建模
针对GMV预估的特殊性,READER框架的创新点在于:
- 双分支结构:独立建模单次购买和复购行为,通过路由机制动态选择专家模型
- 回归纠偏:设计了针对连续值的标签校准方法,解决回归任务的延迟反馈问题
- 在线学习:支持流式训练,能够实时适应GMV标签的动态变化
3. TESLA框架的技术实现细节
3.1 模型架构设计
TESLA采用多任务学习架构,其核心组件包括:
- 共享编码层:学习用户和商品的通用特征表示
- CVR专用塔:建模点击到转化的概率
- RFR专用塔:建模转化后退款的概率
- 级联输出层:NetCVR = CVR × (1 - RFR)
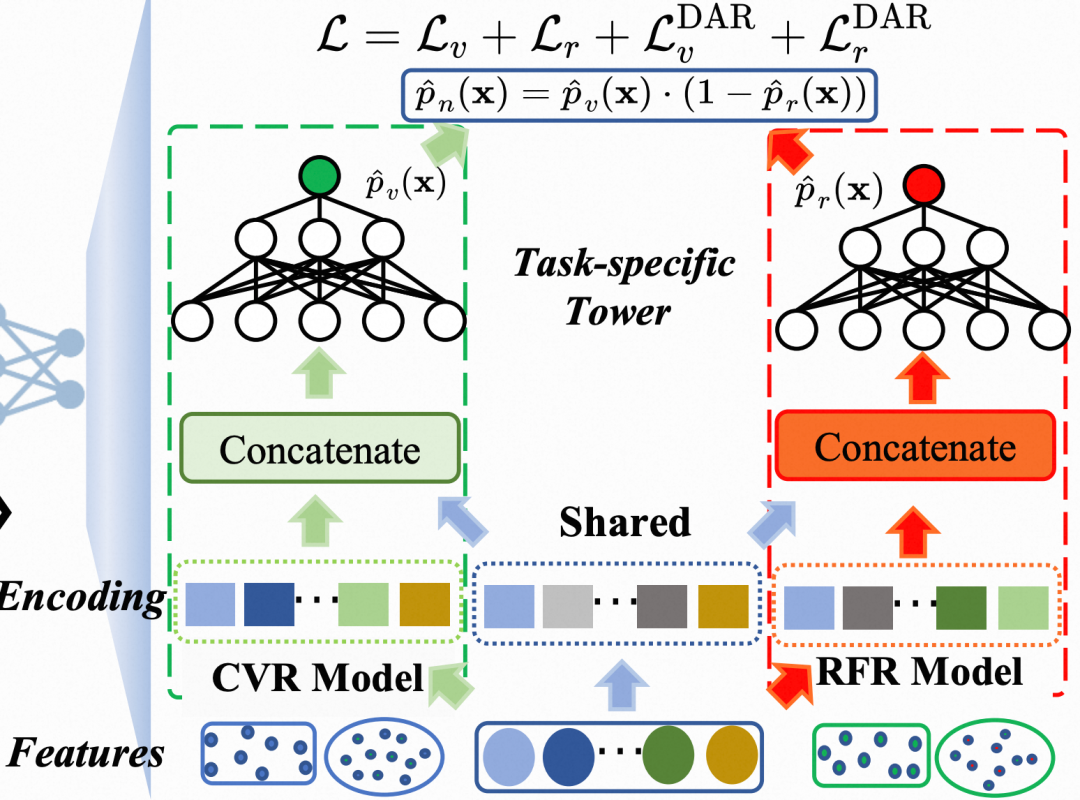
这种设计既考虑了转化与退款行为的相关性(通过共享层),又保留了各自的特异性(通过专用塔)。实验表明,相比端到端直接建模NetCVR,这种分解式设计能带来8.7%的AUC提升。
3.2 分阶段重要性加权
为了解决级联延迟带来的标签偏置,TESLA采用了分阶段纠偏策略:
-
CVR纠偏:对于"点击-转化"阶段,使用逆概率加权(IPW)方法:
code复制w_cvr = 1 / p(observed_cvr | x, t)其中p(observed_cvr|x,t)是给定特征x和时间t下转化被观测到的概率
-
RFR纠偏:对于"转化-退款"阶段,采用条件重要性加权:
code复制w_rfr = 1 / p(observed_rfr | x, t, conversion=1)
这种分阶段处理确保了每个延迟环节都能得到有效校正。在实际实现中,这两个权重估计器是通过辅助神经网络实时更新的。
3.3 延迟感知的排序损失
传统的交叉熵损失对延迟反馈场景存在两个问题:
- 将所有样本等同对待,忽略了延迟时间的信号
- 无法处理可能发生的标签翻转(如初始标记为负,后续回转为正)
TESLA提出了延迟感知排序损失(DAR Loss):
code复制L_dar = ∑_{i,j} φ(t_i,t_j)max(0,1-(f(x_i)-f(x_j)))
其中φ(t_i,t_j)是时间权重函数,给延迟时间短的样本对分配更高权重。同时配合不确定性感知负采样,优先选择模型确信度高的负样本参与训练。
4. READER框架的技术突破
4.1 复购感知的双分支设计
GMV预估的难点在于用户的购买次数不确定。READER的创新在于:
-
路由模块:预测点击会导致单次购买还是多次购买
code复制p_router = σ(W^T h + b)其中h是共享编码层的输出
-
专家塔:
- 单次购买塔:专注学习单次购买的GMV分布
- 复购塔:建模多次购买时的累计GMV模式
-
混合路由机制:
- 当p_router > 0.7:使用复购塔输出
- 当p_router < 0.3:使用单次购买塔输出
- 否则:加权平均两个塔的输出
这种设计在TRACE数据集上实现了路由准确率82.3%,显著优于单模型方案。
4.2 GMV标签的纠偏策略
针对回归任务的特殊性,READER提出了三项创新:
-
回归校准器(Calib):
python复制class Calibrator(nn.Module): def forward(self, x, t): # t: 观测时间与点击时间的差值 return self.mlp(torch.cat([x, t], dim=1))该模块学习当前观测到的GMV与最终真实GMV的偏差模式
-
真实标签对齐(GRA):
当转化窗口完全关闭后,用真实GMV对模型进行微调,修正之前的预测偏差 -
有偏标签遗忘(PLU):
对早期基于部分观测数据的过时预测执行梯度上升操作,减轻其对模型的影响
5. 实际应用效果与部署经验
5.1 离线实验对比
在CASCADE数据集上的测试结果显示:
- TESLA在NetCVR预估上的AUC达到0.812,比最佳基线提升12.4%
- 消融实验表明,分阶段纠偏贡献了6.2%的提升,延迟感知损失贡献了4.1%
在TRACE数据集上:
- READER的GMV预估相对误差为18.7%,比单模型降低6.9%
- 复购识别准确率达到82.3%,有效支持了双分支的价值
5.2 线上AB测试
在淘宝信息流广告场景的线上测试中:
- 采用TESLA的NetCVR模型使RPM(每千次展示收入)提升7.2%
- READER驱动的GMV预估使广告主ROI提高9.8%,同时平台收入增长5.3%
5.3 工程实现要点
在实际部署时,我们总结了以下经验:
-
流式训练架构:
- 采用Flink实现实时样本拼接与特征生成
- 模型每15分钟增量更新一次,保证时效性
- 设计专门的样本回填机制处理延迟反馈
-
服务化优化:
java复制// 伪代码:GMV预估服务优化 public class GMVPredictor { private Router router; private SingleTower singleTower; private RepurchaseTower repurchaseTower; public float predict(UserFeature uf, ItemFeature itf) { float routeProb = router.predict(uf, itf); if (routeProb > 0.7) { return repurchaseTower.predict(uf, itf); } else if (routeProb < 0.3) { return singleTower.predict(uf, itf); } else { return routeProb * repurchaseTower.predict(uf, itf) + (1-routeProb) * singleTower.predict(uf, itf); } } }通过动态路由,服务TP99延迟控制在28ms以内
-
特征体系设计:
- 用户维度:加入历史转化延迟、退款倾向等时序特征
- 商品维度:提取类目平均退款率、价格敏感度等统计特征
- 上下文特征:包括小时段、节假日等时间敏感特征
6. 未来研究方向
基于当前工作,我们认为级联延迟反馈建模还有以下值得探索的方向:
-
增量式机器遗忘:
python复制def unlearn_step(model, sample): # 对早期基于部分观测的预测执行梯度上升 pred = model(sample) loss = -F.mse_loss(pred, sample.label) # 梯度上升 loss.backward() optimizer.step()这种方法可以主动消除延迟反馈初期产生的错误更新
-
大模型增强的路由:
考虑用LLM增强复购预测,例如:code复制
用户最近购买了奶粉 → 可能周期性复购 用户购买了婚纱 → 大概率不会复购 -
多场景联合建模:
探索跨广告位、跨业务的级联延迟模式迁移,提升小场景的预估效果
在实际业务迭代中,我们发现级联延迟反馈问题会随着业务形态变化而演化。比如直播电商的兴起带来了新的延迟模式,这要求建模框架具备足够的灵活性和可扩展性。TESLA和READER的设计哲学正是基于这种考虑,通过模块化的架构支持持续迭代。