
1. 从零理解Engram条件内存技术
作为一名长期从事AI模型优化的工程师,我最近深入研究了DeepSeek团队提出的Engram条件内存技术。这项技术通过创新的架构设计,成功解决了当前大语言模型在知识检索效率上的核心痛点。下面我将用最通俗的语言,带大家彻底理解这项技术的原理和价值。
1.1 为什么需要条件内存?
现代大语言模型主要依赖两种计算范式:
- 动态计算:通过注意力机制和前馈网络进行复杂推理
- 静态检索:从模型参数中提取存储的知识
传统Transformer架构存在一个根本性缺陷:它没有原生的知识检索机制。这意味着即使是简单的知识查询(比如"法国的首都是什么"),模型也不得不通过多层神经网络计算来"重建"答案,而不是直接"查找"。
这就好比你要查字典时,不能直接翻到对应页码,而必须从第一页开始逐页阅读直到找到目标词。这种设计显然效率低下,尤其当模型规模增长到数百亿参数时。
1.2 Engram的核心创新
Engram模块的突破在于引入了条件内存这一新维度。其核心思想是将:
- 静态知识存储(通过N-gram嵌入表实现)
- 动态神经计算(通过MoE专家实现)
解耦为两个独立的子系统。这种分离带来了三大优势:
- 效率提升:知识检索变为O(1)时间复杂度的查找操作
- 容量扩展:内存规模可以独立于计算资源进行扩展
- 专注分工:MoE专家可以专注于真正的推理任务
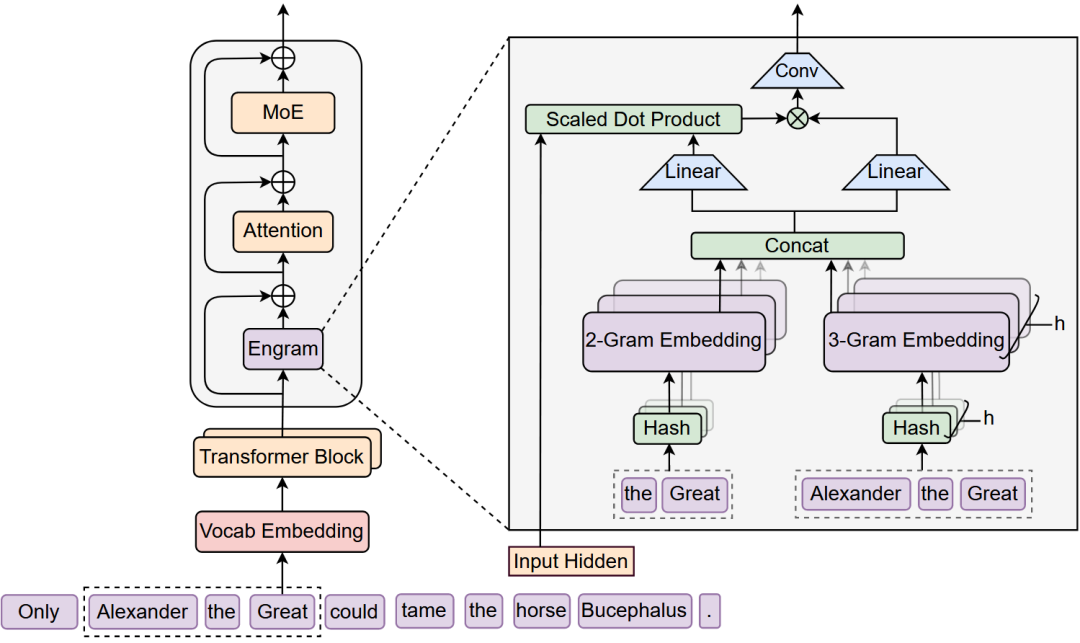
2. Engram技术细节深入解析
2.1 模块架构设计
Engram模块包含三个关键组件:
2.1.1 哈希N-gram检索
这部分实现了高效的知识查找:
- 分词器压缩:通过NFKC归一化等技术,将原始token ID空间压缩23%
- 多头哈希:使用K个不同的哈希函数减少冲突
- N-gram组合:主要处理2-3元的常见短语模式
python复制# 伪代码示例:Engram的哈希查找过程
def engram_lookup(token_sequence):
compressed_ids = [vocab_compress(t) for t in token_sequence]
ngrams = generate_ngrams(compressed_ids) # 生成2-3元组
embeddings = []
for ngram in ngrams:
for hash_head in range(K): # K个哈希头
index = hash_function(ngram, hash_head)
emb = embedding_table[index]
embeddings.append(emb)
return concatenate(embeddings)
2.1.2 上下文感知门控
这个机制解决了静态嵌入的适应性问题:
- 用当前隐藏状态作为查询(Query)
- 用检索到的内存作为键(Key)和值(Value)
- 计算门控系数α∈(0,1)动态调节内存贡献
关键点:当检索内容与当前上下文不符时,门控会自动降低该内存的贡献,有效抑制噪声。
2.1.3 多分支集成
为适配现代多分支架构(如DeepSeek-MoE),Engram采用:
- 共享Value投影矩阵
- 独立Key投影矩阵
- FP8矩阵乘法优化
这种设计既保持了各分支的特性,又最大化利用了GPU计算资源。
2.2 系统级优化
Engram在系统实现上做了两项关键创新:
-
训练阶段:
- 嵌入表分片存储在多个GPU上
- 使用All-to-All通信收集激活行
-
推理阶段:
- 将大内存表卸载到主机内存
- 利用确定性索引预取数据
- 计算与通信重叠
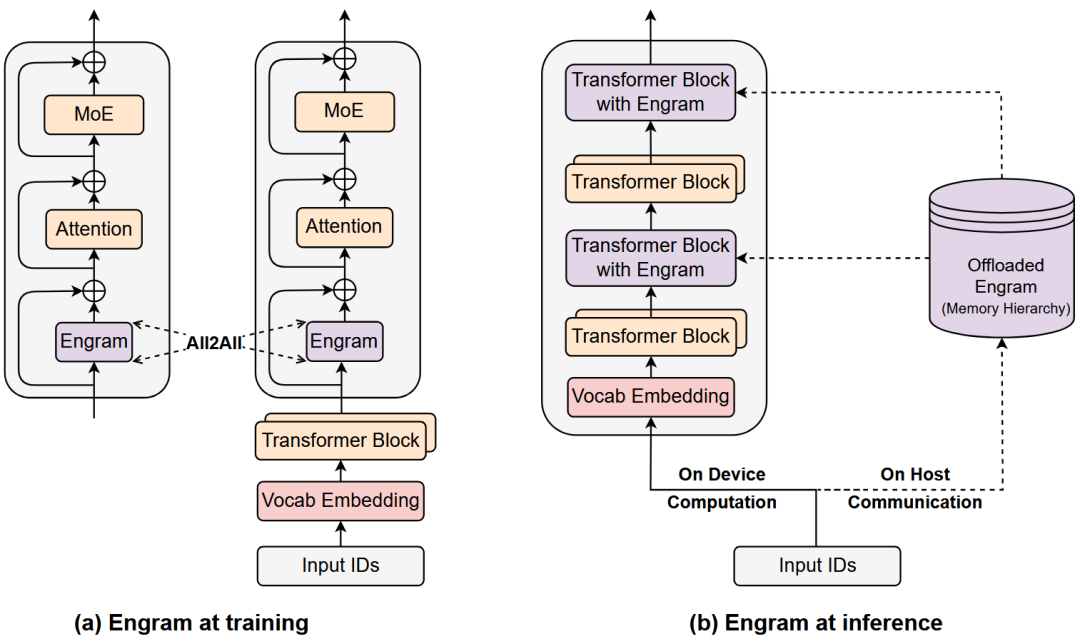
实测表明,即使将1000亿参数的Engram表放在主机内存,对8B骨干模型的推理吞吐量影响也不到3%。
3. 性能表现与实战价值
3.1 基准测试结果
在270亿参数规模下,Engram相比纯MoE模型展现出全面优势:
| 任务类型 | 测试基准 | 准确率提升 |
|---|---|---|
| 知识任务 | MMLU (5-shot) | +3.0% |
| 推理任务 | BBH (3-shot) | +5.0% |
| 代码/数学 | HumanEval | +3.0% |
| 长上下文 | MultiQuery NIAH | +12.8% |
特别值得注意的是,Engram在推理和代码任务上的提升反而比知识任务更显著,这颠覆了"内存模块只利好知识检索"的传统认知。
3.2 实际应用建议
根据论文中的U形缩放律,在实际应用中建议:
- 将75-80%的稀疏参数分配给MoE专家
- 剩余20-25%分配给Engram内存
- 在模型第2层和第15层插入Engram模块
这种配置在多个规模下都显示出最优性能。
4. 技术原理深度解读
4.1 为什么Engram能提升有效深度?
通过LogitLens和CKA分析发现:
- Engram模型的第5层表征 ≈ MoE模型的第12层表征
- 早期层不再需要重建静态模式
- 更多网络深度可用于真实推理
这就好比在高速公路上设置了服务区,让车辆可以快速补给,而不必绕道下高速。
4.2 长上下文性能提升的奥秘
Engram通过两种机制增强长上下文处理:
- 注意力容量释放:将局部依赖委托给查找,注意力头可以专注全局关系
- 内存分级缓存:利用N-gram的齐夫分布特性,实现高效缓存
在32k长度的MultiQuery NIAH任务中,准确率从84.2%飙升至97.0%。
5. 实践指南与经验分享
5.1 训练调优技巧
-
学习率策略:
- 嵌入参数使用5倍大的学习率
- 无权重衰减
-
初始化技巧:
- 卷积层初始化为零
- 确保训练初期保持恒等映射
-
批次配置:
- 使用较大批次训练内存表
- 逐步增加N-gram阶数
5.2 推理优化实践
-
内存部署:
- 高频N-gram缓存于GPU HBM
- 中频存放于主机DRAM
- 低频存储在NVMe SSD
-
预取策略:
- 利用确定性索引提前加载
- 与前一层的计算重叠
-
量化方案:
- 嵌入表使用FP8格式
- 门控计算保持FP16
6. 常见问题与解决方案
6.1 哈希冲突处理
问题:不同N-gram可能哈希到同一位置
解决方案:
- 使用多头哈希(K=8)
- 增加嵌入维度(d=1280)
- 上下文门控自动抑制冲突噪声
6.2 内存与计算平衡
问题:如何分配MoE和Engram的参数预算
解决方案:
- 遵循U形缩放律
- 基准测试建议ρ=75-80%
- 使用网格搜索微调
6.3 长尾N-gram处理
问题:低频N-gram得不到充分训练
解决方案:
- 采用课程学习策略
- 初期仅训练2-gram
- 逐步引入3-gram
7. 技术展望与延伸思考
Engram技术为大模型架构开辟了新方向,我认为未来可能的发展包括:
-
多模态扩展:
- 将图像patch视为视觉"token"
- 构建跨模态N-gram内存
-
动态内存更新:
- 在推理阶段增量更新内存
- 实现知识实时更新
-
专用硬件优化:
- 设计N-gram查找专用指令
- 近内存计算架构
这项技术已经开源,代码库位于:https://github.com/deepseek-ai/Engram。对于想要深入研究的开发者,我建议从论文中的3B参数实验配置开始,逐步扩展到更大规模。