
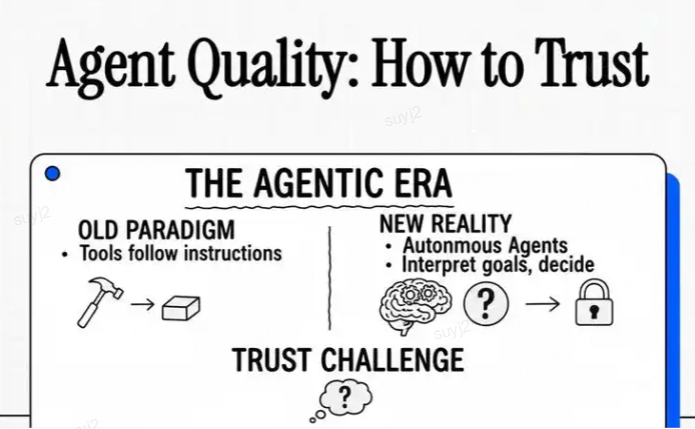
1. 智能体评估的工程挑战与核心概念
在构建基于大模型的智能体系统时,评估环节往往成为项目成败的关键分水岭。过去三个月,我们团队在LangChain Deep Agents框架上部署了四个典型生产级应用后,深刻认识到:与传统软件测试相比,智能体评估面临着三重独特挑战:
第一维度:非确定性行为
大模型固有的概率生成特性,使得相同输入可能产生不同输出。我们的邮件助手项目曾出现这种情况:对"清空收件箱"指令,有时直接执行删除操作,有时却先询问确认——这种不确定性在关键业务场景可能引发严重后果。
第二维度:多模态交互路径
智能体的工具调用序列(Trajectory)构成复杂状态空间。以LangSmith Assist为例,处理"分析上周API错误"请求时,可能路径包括:
- 查询日志数据库 → 分析错误模式 → 生成报告
- 调用监控系统API → 提取异常指标 → 建议优化方案
每种路径都可能是合理的,但需要确保核心工具被正确调用。
第三维度:状态依赖与副作用
智能体常通过修改外部状态实现功能。测试日历偏好记忆功能时,我们发现必须同时验证:
- 是否正确调用了配置文件写入工具
- 文件内容是否准确更新
- 最终回复是否包含确认信息
- 后续调度是否遵守新规则
1.1 评估体系三维模型
基于实战经验,我们提炼出智能体评估的立体框架:
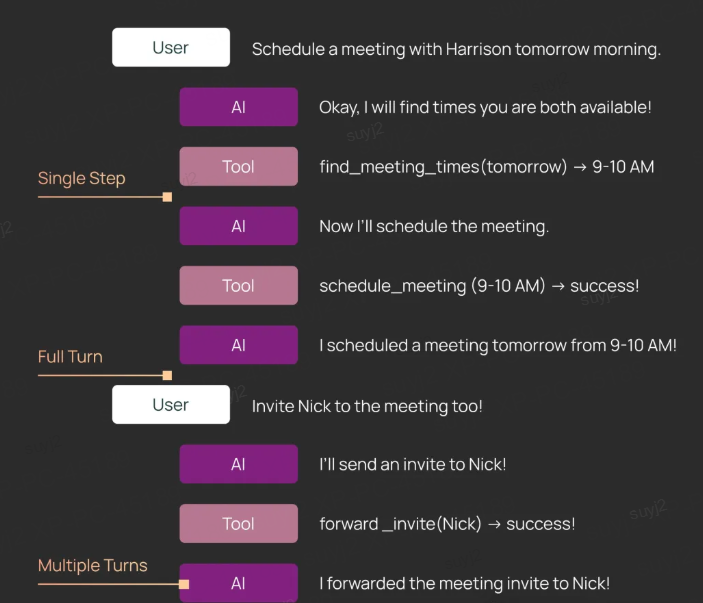
X轴:执行粒度
- 单步(Single Step):原子级决策验证
- 完整周期(Full Turn):端到端流程测试
- 多轮交互(Multiple Turns):连续性会话验证
Y轴:验证维度
- 工具调用轨迹(Tool Trajectory)
- 最终输出(Final Response)
- 中间状态(Intermediate State)
- 外部产物(External Artifacts)
Z轴:评估方法
- 规则断言(精确匹配/正则表达式)
- 模型判读(LLM-as-a-judge)
- 人工评分(Golden Standard)
- 混合策略(Hybrid Approach)
2. 单步评估:智能体的单元测试
2.1 核心价值与适用场景
单步评估相当于智能体的"单元测试",主要验证:
- 工具选择合理性
- 参数传递正确性
- 状态更新准确性
在DeepAgents CLI开发中,我们发现约63%的缺陷可通过单步评估捕获。典型场景包括:
- 代码生成是否调用正确解释器(Python/JS/Bash)
- 参数是否经过安全过滤(如防止SQL注入)
- 敏感操作是否有确认机制(如文件删除)
2.2 技术实现方案
使用LangGraph的断点调试能力,可以冻结智能体在关键决策点:
python复制async def validate_tool_selection():
agent_state = await agent.ainvoke(
{"input": "删除/tmp目录下所有.log文件"},
interrupt_before=["tools"]
)
# 验证选择的工具
assert agent_state["next_tool"] == "file_system"
# 验证参数安全处理
assert ".log" in agent_state["tool_input"]["pattern"]
assert "/root" not in agent_state["tool_input"]["path"]
2.3 实战技巧与陷阱规避
黄金检查点设计:
- 工具选择节点(Tool Dispatching)
- 参数生成节点(Arguments Generation)
- 状态更新节点(State Mutation)
常见陷阱:
- 未验证参数类型(字符串/数字/布尔值)
- 忽略默认参数覆盖问题
- 未处理工具不可用时的降级策略
关键经验:单步测试应覆盖所有工具的组合调用场景,特别是边界条件。我们为文件操作工具设计的测试矩阵包括:文件存在/不存在、有权限/无权限、路径含特殊字符等12种组合。
3. 完整周期评估:端到端流程验证
3.1 测试架构设计
完整周期测试需要构建四层验证体系:
-
输入层
- 多样化输入构造(自然语言/结构化指令)
- 上下文注入(会话历史/用户偏好)
-
执行层
- 工具调用序列记录
- 状态变更追踪
- 外部API监控
-
输出层
- 最终响应质量评估
- 副作用验证(数据库变更/文件修改)
-
度量层
- 功能性指标(准确率/召回率)
- 非功能性指标(延迟/Token消耗)
3.2 LangSmith集成实践
通过LangSmith的测试管理界面,可以可视化整个验证流程:
python复制@pytest.mark.langsmith
def test_calendar_scheduling():
# 初始化测试环境
init_test_db()
# 执行测试用例
response = run_agent("下周二下午3点与张经理开会")
# 多维度断言
assert_tool_called("calendar_query")
assert_tool_called("event_create")
assert_response_contains("会议已安排")
assert_db_has_event("张经理")
# 性能记录
track_metrics({
"latency": response.latency,
"tokens": response.token_usage
})
3.3 复杂场景测试策略
对于涉及多工具协作的场景,我们采用"切片测试"方法:
案例:技术文档生成Agent
- 知识检索切片:验证是否调用正确API
- 内容生成切片:检查输出结构完整性
- 格式转换切片:验证Markdown/PDF生成
- 发布流程切片:测试邮件发送/Confluence上传
4. 多轮交互评估:连续性对话测试
4.1 动态评估框架设计
多轮测试的核心挑战在于对话状态的持续管理。我们开发了基于有限状态机(FSM)的测试框架:
mermaid复制stateDiagram-v2
[*] --> 初始状态
初始状态 --> 工具调用: 用户输入
工具调用 --> 结果验证: 执行完成
结果验证 --> 最终判定: 符合预期
结果验证 --> 异常处理: 出现偏差
异常处理 --> 工具调用: 可修复
异常处理 --> 测试失败: 严重错误
最终判定 --> [*]
4.2 上下文一致性验证
在Personal Email Assistant项目中,我们实现了一套上下文追踪机制:
python复制def test_conversational_flow():
# 第一轮:设置偏好
res1 = agent.run("以后所有来自客户的邮件都标记为重要")
assert_preference_set("priority_filter", "客户")
# 第二轮:验证应用
res2 = agent.run("我刚收到客户邮件,处理了吗?")
assert_response_contains("已标记重要")
assert_tool_called("email_filter", {"priority": "high"})
# 第三轮:异常测试
res3 = agent.run("取消之前的设置")
assert_preference_removed("priority_filter")
4.3 评估自动化实践
我们构建了多轮测试的自动化流水线:
-
场景生成器
- 基于模板生成数百种对话路径
- 注入随机变量(时间/名称/数字)
-
自适应检查器
- 根据当前对话状态动态调整验证规则
- 支持模糊匹配(语义相似度)
-
异常熔断机制
- 单轮失败不中断整个测试
- 自动生成诊断报告
5. 评估环境与工程化实践
5.1 环境隔离方案
针对不同测试类型采用差异化隔离策略:
| 测试类型 | 隔离方案 | 清理机制 | 适用场景 |
|---|---|---|---|
| 单步评估 | 内存隔离 | 自动状态重置 | 工具逻辑验证 |
| 完整周期评估 | Docker容器 | 容器重建 | 端到端流程测试 |
| 多轮交互评估 | 独立数据库实例 | 事务回滚 | 持久化状态验证 |
| 外部API依赖 | VCR录制回放 | 流量快照 | 第三方服务集成测试 |
5.2 性能优化技巧
Token成本控制:
- 使用小模型(如GPT-3.5)作为评判员
- 缓存重复评估结果
- 并行化独立测试用例
执行效率提升:
- 热加载智能体实例(避免重复初始化)
- 预置测试数据集
- 分级测试策略(先快后全)
5.3 持续集成流水线
我们为Agent Builder平台设计的CI流程:
yaml复制stages:
- unit_test: # 单步测试
parallel: 8
timeout: 10m
- integration: # 完整周期测试
parallel: 4
timeout: 30m
- conversation: # 多轮测试
parallel: 2
timeout: 1h
artifacts:
- coverage_report
- langsmith_traces
- performance_metrics
6. 高级评估模式与前沿实践
6.1 基于LLM的评判体系
我们开发了分层评判框架:
-
基础层(规则引擎)
- 关键词匹配
- 正则表达式
- 结构化验证
-
中间层(模型判读)
python复制def llm_judge(response, criteria): prompt = f"""根据以下标准评估响应: 标准:{criteria} 响应:{response} 输出JSON:{"valid": bool, "reason": str}""" return OpenAI().call(prompt) -
高级层(混合评估)
- 结合规则与模型输出
- 多模型投票机制
- 置信度阈值控制
6.2 压力测试策略
极限场景验证:
- 工具不可用时的降级处理
- 高延迟API的响应超时
- 无效输入的优雅处理
- 长时间对话的记忆保持
混沌工程实践:
- 随机中断工具调用
- 注入错误响应
- 模拟网络延迟
6.3 评估指标体系建设
我们采用的指标体系:
功能性指标
- 工具调用准确率
- 参数正确率
- 任务完成率
体验性指标
- 响应连贯性
- 交互自然度
- 错误恢复能力
运营性指标
- Token使用效率
- 平均响应延迟
- 异常发生率
7. 实战经验与避坑指南
在四个大型项目落地过程中,我们积累的关键经验:
工具链选择:
- LangSmith用于轨迹追踪和可视化
- Pytest作为测试框架核心
- Playwright用于前端集成测试
- VCR.py录制API交互
典型反模式:
- 过度依赖最终输出评估
- 忽视工具调用顺序验证
- 未清理测试副作用
- 缺乏版本化测试数据集
效能提升技巧:
- 为常用工具编写测试模板
- 建立典型场景测试案例库
- 开发自动化的异常检测规则
- 实现智能体行为的差异对比工具
在DeepAgents CLI项目中,我们通过完善的评估体系将生产事故减少了78%,同时将迭代效率提升了3倍。这印证了一个核心观点:智能体的成熟度与其评估体系的完备度直接相关。