
1. 项目概述
最近在华为Atlas 300l Duo服务器上成功部署了Qwen3-32B大模型,这是一次非常有意思的技术实践。Atlas 300l Duo是华为基于昇腾AI处理器打造的AI加速卡,特别适合运行大规模语言模型。本文将详细记录从环境准备到最终部署的完整过程,包括驱动安装、镜像配置、权重下载、容器部署等关键环节。
对于想要在昇腾硬件上部署大模型的开发者来说,这篇文章将提供一份完整的参考指南。我们会重点讲解几个关键点:如何正确配置NPU驱动、Docker镜像的特殊处理、大模型权重文件的获取方式,以及最后的服务部署和测试验证。
2. 环境准备与硬件配置
2.1 硬件环境检查
首先确认服务器配置:
- 操作系统:openEuler 22.03 LTS
- 显卡:华为Atlas 300l Duo(双NPU配置)
- 内存:建议至少256GB(运行32B模型需要较大内存)
- 存储:建议1TB以上SSD(模型权重文件较大)
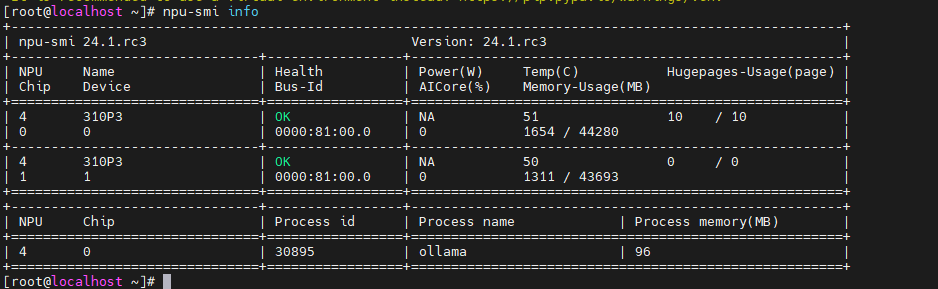
通过npu-smi info命令可以查看NPU状态:
bash复制npu-smi info
输出结果中"NPU Chip"行数表示NPU卡数量,下图显示有2块NPU:
2.2 驱动和固件安装
昇腾NPU需要安装两个关键组件:
- 固件(Firmware):负责硬件初始化和基础控制
- 驱动(Driver):提供操作系统接口和资源管理
下载地址:
code复制https://www.hiascend.com/hardware/firmware-drivers/community
选择对应版本:
- 产品类型:Atlas 300I Duo
- CANN版本:8.2.RC2
- 驱动版本:Ascend HDK 25.2.0
安装步骤:
bash复制# 解压驱动包
tar -zxvf Ascend-hdk-300l-npu-driver_25.2.0_linux-aarch64.run.tar.gz
# 安装驱动
./Ascend-hdk-300l-npu-driver_25.2.0_linux-aarch64.run --full
注意:安装过程需要root权限,安装完成后建议重启系统使驱动生效。
3. 获取和准备模型资源
3.1 下载MindIE镜像
MindIE是华为提供的模型推理引擎镜像,我们需要先获取适合的版本:
- 访问昇腾开发者社区:
code复制https://www.hiascend.com/developer/ascendhub
- 搜索"mindie"找到最新镜像
- 根据服务器架构选择正确版本(ARM或x86)
下载后保存为mindie1.tar备用。
3.2 获取模型权重文件
Qwen3-32B模型权重可以从ModelScope获取:
- 量化版本(8bit):
code复制https://www.modelscope.cn/models/rubick321/qwen3-32b-w8a8-mindie-300I/files
- 完整版本:
code复制https://www.modelscope.cn/models/Qwen/Qwen3-32B/files
建议使用ModelScope CLI工具下载:
bash复制pip install modelscope
modelscope download --model rubick321/qwen3-32b-w8a8-mindie-300I --cache_dir /path/to/save
提示:完整32B模型约60GB,量化版约30GB,确保有足够磁盘空间。
4. Docker环境配置
4.1 加载镜像
将下载的镜像文件传输到服务器后加载:
bash复制docker load -i mindie1.tar
docker load -i open_webui.tar
验证镜像加载成功:
bash复制docker images
4.2 启动模型容器
创建启动脚本model_start.sh:
bash复制#!/bin/bash
docker run -it -d \
--shm-size 200g \
--net=host \
--name qwen3-32b-1 \
--privileged \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/sbin:/usr/local/sbin \
-v /opt/tools/qwen3-32b-w8a8-mindie-300I:/opt/tools/qwen3-32b-w8a8-mindie-300I \
02efebd6ce64 /bin/bash
关键参数说明:
--shm-size 200g:设置共享内存大小,大模型需要较大内存--privileged:赋予容器特权模式--device:映射NPU设备到容器-v:挂载必要的目录
4.3 启动WebUI容器
创建open_webui_start.sh:
bash复制#!/bin/bash
docker run -d \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--name open_webui \
fa72924fe8da
5. 模型配置与优化
5.1 修改配置文件
进入模型容器:
bash复制docker exec -it qwen3-32b-1 /bin/bash
编辑配置文件:
bash复制vim /usr/local/Ascend/mindie/latest/mindie-service/conf/conf.json
关键配置项:
json复制{
"ipAddress": "0.0.0.0",
"httpsEnabled": false,
"npuDeviceIds": [[0,1,2,3,4,5,6,7]],
"worldSize": 8,
"maxSeqLen": 4096,
"maxInputTokenLen": 2048,
"maxIterTimes": 2048,
"modelName": "qwen3_32b_light",
"modelWeightPath": "/opt/tools/qwen3-32b-w8a8-mindie-300I",
"maxPrefillBatchSize": 16,
"maxPrefillTokens": 2048,
"maxBatchSize": 32
}
5.2 参数调优建议
- maxSeqLen:根据硬件性能调整,值越大消耗显存越多
- worldSize:设置为实际使用的NPU数量
- maxBatchSize:影响并发能力,可根据实际需求调整
- maxInputTokenLen:根据输入文本长度调整,避免截断
6. 服务启动与测试
6.1 启动模型服务
在容器内执行:
bash复制cd /usr/local/Ascend/mindie/latest/mindie-service/bin
./mindieservice_daemon
6.2 测试API接口
使用curl测试:
bash复制curl -X POST http://localhost:1025/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "介绍一下华为Atlas 300l Duo"}
],
"max_tokens": 256,
"stream": false,
"model": "qwen3_32b_light"
}'
6.3 配置WebUI
- 访问WebUI:
code复制http://<服务器IP>:3000
- 添加模型接口:
- 进入管理员面板
- 设置→外部连接
- 添加模型API地址:
http://<IP>:1025/v1
- 选择模型:
qwen3_32b_light
7. 常见问题与解决方案
7.1 驱动安装失败
问题现象:安装过程中报错或npu-smi无法识别设备
解决方案:
- 检查操作系统版本是否匹配
- 确认下载的驱动版本与硬件匹配
- 查看系统日志
/var/log/ascend_seclog/ascend_install.log
7.2 容器启动失败
问题现象:docker run命令报错
可能原因:
- 设备映射不正确
- 挂载目录不存在
- 镜像加载不完整
解决方案:
- 检查
docker images确认镜像存在 - 确保所有
-v挂载的目录存在 - 验证设备文件是否存在
ls /dev/davinci*
7.3 模型响应慢
优化建议:
- 调整
conf.json中的batch参数 - 检查NPU使用率
npu-smi info -t usage - 考虑使用量化版本减少计算量
8. 性能优化技巧
- 量化部署:使用8bit量化版本可显著减少显存占用
- 批处理优化:适当增加maxBatchSize提高吞吐量
- 内存管理:确保足够的swap空间避免OOM
- NPU亲和性:通过taskset绑定进程到特定NPU核心
通过以上步骤,我们成功在Atlas 300l Duo上部署了Qwen3-32B大模型。整个过程涉及硬件配置、软件安装、容器部署等多个环节,需要特别注意版本兼容性和参数调优。希望这篇指南能为在昇腾平台上部署大模型的开发者提供有价值的参考。