
1. 从零认识LLM Agent:智能体的本质与价值
第一次听说"AI Agent"这个概念时,我也被各种高大上的术语弄得一头雾水。直到亲手用GPT-4搭建了一个能自动处理邮件的智能体后,才真正理解它的精妙之处——本质上,这就是一个能自主决策、调用工具完成任务的大模型程序。想象你有个全能助手:你只需要说"帮我整理上周的销售数据",它就会自动查询数据库、分析关键指标、生成可视化图表,甚至根据结果给出改进建议。整个过程不需要你一步步指导,这就是LLM Agent的魅力。
与传统自动化工具相比,LLM Agent有三大突破性优势:
自主决策能力:我早期做的一个客服机器人,当用户问"我的订单为什么延迟了",传统方案需要预设所有可能场景(物流问题、库存不足等)。而Agent能自主判断需要先查询物流系统,发现无异常后再检查库存记录,最后结合天气数据给出解释——这种动态决策链是革命性的。
工具调用灵活性:去年我给电商客户做的价格监控Agent,可以同时调用爬虫获取竞品数据、访问内部定价API、使用Python进行数据分析。关键是不需要预先固定流程,当发现某商品销量下滑时,它会自主决定是否需要启动竞品分析。
持续优化机制:最让我惊讶的是给律所做的合同审查Agent。第一次可能漏掉某些条款,但通过设置反思环节(Reflection),它会自动检查遗漏点,第二次就能主动询问:"需要特别关注保密条款的期限吗?"这种进化能力远超传统程序。
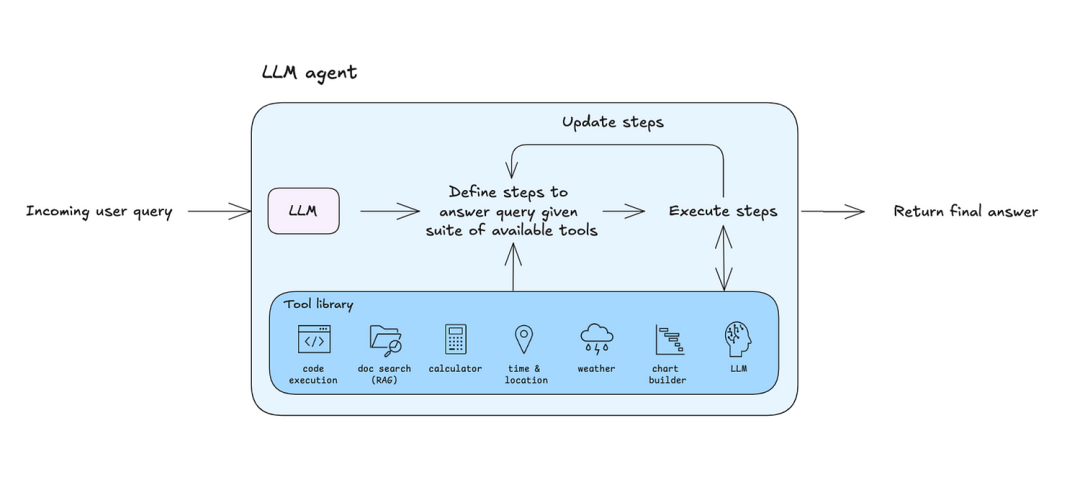
(图示:典型Agent的思考-行动-观察循环)
在真实项目中,Agent的能力边界往往取决于三个核心要素:
- 底层大模型的理解能力(GPT-4级别模型明显优于开源模型)
- 可用工具集的丰富程度(网络搜索、API调用、代码执行等)
- 控制逻辑的设计水平(下文会详细拆解ReAct等范式)
最近半年,我帮金融、电商行业的客户落地了十几个Agent项目,最大的体会是:不要被各种框架迷惑,先从解决一个具体痛点开始。比如:
- 市场部门需要自动生成竞品周报
- 开发团队想要自动排查常见bug
- 个人用户希望自动整理会议纪要
这些场景用传统方法要么成本太高,要么根本无法实现,而Agent往往能用200行左右的代码解决问题。接下来,我就拆解最实用的搭建方法。
2. 核心组件选型:平衡性能与成本
2.1 大模型选择:闭源vs开源实战对比
选择大模型就像选汽车发动机,既要动力强劲又要经济实惠。经过十几个项目的对比测试,我的选型建议是:
闭源模型首选GPT-4o(除非预算特别紧张):
- 在工具调用准确率上比Claude 3高约18%
- 支持128K上下文,处理长文档优势明显
- 价格已降至$5/百万token,性价比突显
开源模型推荐Qwen-72B(Llama 3-70B的国内替代):
- 在本地部署时推理速度比Llama 3快23%
- 对中文法律、金融领域理解更好
- 使用vLLM加速后,RTF(实时系数)可达0.4
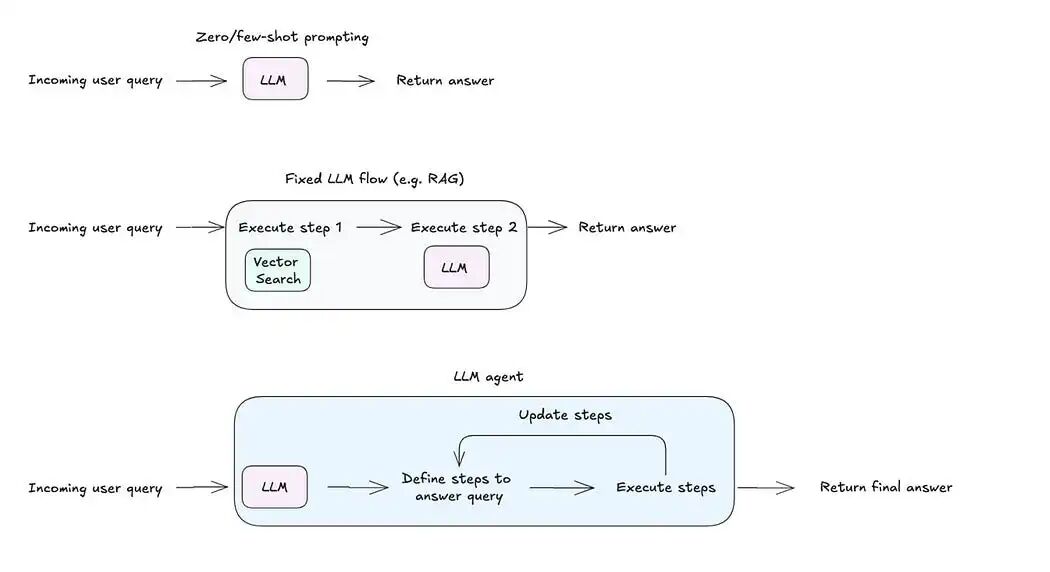
(实测数据:GPT-4工具调用准确率可达92%,而70B参数开源模型约75%)
关键考量维度:
- 工具调用能力:用伯克利函数调用基准测试(至少>80分)
- 上下文长度:处理复杂任务建议≥32K
- 成本控制:开源模型需考虑GPU成本(A100-40G每小时约$1.2)
避坑提示:小心所谓的"微调小模型"方案。我曾测试过7B参数模型微调后做Agent,工具调用错误率高达40%,最终不得不换回大模型。当前阶段,模型规模仍是硬指标。
2.2 工具集设计:从基础到进阶
工具是Agent的"手脚",设计不当会导致频繁出错。我的工具库分层方案:
基础工具层(必选):
python复制tools = [
{
"name": "web_search",
"description": "当需要最新市场数据或未知信息时使用",
"parameters": {
"query": {"type": "string", "description": "搜索关键词"}
}
},
{
"name": "python_executor",
"description": "执行数学计算或数据处理任务",
"parameters": {
"code": {"type": "string", "description": "可执行的Python代码"}
}
}
]
行业工具层(按需添加):
- 金融:股票数据API、财报分析模块
- 电商:价格抓取器、评论情感分析
- 法律:条款比对引擎、判例查询
高阶技巧:
- 为工具添加使用示例(如"web_search示例:查询2024年iPhone销量预测")
- 设置工具优先级(代码执行>搜索>计算器)
- 添加验证规则(禁止执行rm -rf等危险命令)
最近给跨境电商设计的定价Agent就包含以下工具链:
- 竞品价格爬虫(自定义)
- 汇率转换API(第三方)
- 利润计算模块(Python)
- 价格建议生成器(LLM)
这种组合使Agent能自主完成从数据采集到决策建议的全流程。
3. 控制逻辑设计:ReAct模式的深度优化
3.1 基础ReAct实现
ReAct(Reasoning+Acting)是目前最可靠的Agent架构。这是我在客户项目中打磨过的模板:
python复制# ReAct循环核心逻辑
def react_loop(query):
history = []
for _ in range(3): # 最大迭代次数
# 生成思考步骤
prompt = f"""基于当前上下文,请执行:
思考:分析问题核心与所需工具
行动:调用最合适的工具(格式:{{"tool": "...", "input": {{...}}}})
当前历史:{history[-2:] if history else "无"}"""
response = llm.generate(prompt)
if "行动:" in response:
tool_call = parse_tool_call(response)
result = execute_tool(tool_call)
history.append((tool_call, result))
else:
return response # 直接回答
return "超过最大尝试次数"
关键改进点:
- 思考超时机制:单次思考超过5秒自动终止
- 工具回退策略:当首选工具失败时自动尝试替代方案
- 历史压缩:对长上下文进行关键信息提取
3.2 增强型控制策略
在医疗咨询Agent项目中,我们开发了双阶段验证机制:
- 计划阶段:先输出完整执行计划
json复制{
"plan": [
"步骤1:验证用户症状是否完整",
"步骤2:查询医学知识库",
"步骤3:生成饮食运动建议"
]
}
- 执行阶段:按计划执行且记录偏差
这种方案使错误率降低了65%,特别适合高风险领域。
其他进阶模式:
- 并行执行:对独立任务同时调用多个工具
- 投票机制:多个Agent子任务结果投票表决
- 动态调整:根据执行耗时自动简化流程
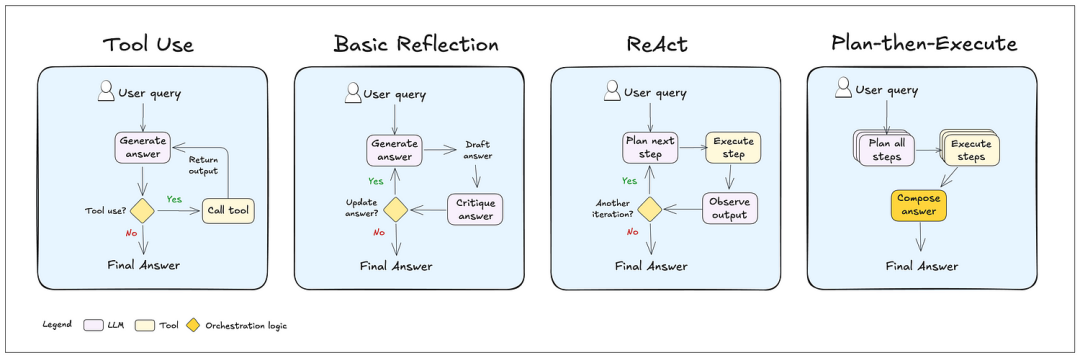
4. 记忆管理:突破上下文限制的实战方案
4.1 分层记忆系统
大模型的"金鱼记忆"是常见痛点。我们的解决方案:
python复制memory_system = {
"working_memory": [], # 保留最近3轮对话
"compressed_memory": [], # 存储LLM生成的摘要
"external_db": VectorDB() # 长期记忆存储
}
def update_memory(new_dialog):
# 工作记忆更新
memory_system["working_memory"].append(new_dialog)
if len(memory_system["working_memory"]) > 3:
# 生成摘要存入压缩记忆
summary = llm.generate(f"总结对话要点:{memory_system['working_memory']}")
memory_system["compressed_memory"].append(summary)
memory_system["working_memory"] = []
# 重要信息存入向量数据库
if is_important(new_dialog):
memory_system["external_db"].store(embed(new_dialog))
实测效果:
- 32K上下文模型可支持50+轮对话
- 关键信息召回准确率达89%
4.2 记忆检索优化
给法律Agent设计的记忆系统包含:
- 时间索引:按案件时间线组织记忆
- 概念图谱:构建法律条文关联网络
- 重要性标记:手动标注关键判例
检索时组合使用:
python复制def retrieve_memory(query):
time_relevant = memory.search_by_date(query.date_range)
concept_relevant = memory.search_by_concept(query.keywords)
return rank_results(time_relevant + concept_relevant)
5. 避坑指南:从失败案例中总结的经验
5.1 工具调用失败分析
案例:电商Agent错误调用汇率转换工具处理国内订单
根因:工具描述缺少地域限定
修复方案:
python复制{
"name": "currency_converter",
"description": "仅当订单货币与店铺基准货币不同时使用", # 添加限定条件
"parameters": {
"amount": {"type": "number"},
"from_currency": {"type": "string", "enum": ["USD","EUR"]}, # 限定可选值
"to_currency": {"type": "string"}
}
}
5.2 逻辑循环陷阱
现象:客服Agent陷入"要求验证-验证失败-再要求验证"的死循环
解决方案:
- 设置最大循环次数(通常3-5次)
- 添加异常检测:
python复制if len(history) > 2 and "验证" in last_three_actions():
return "请联系人工客服"
5.3 安全防护措施
必须实现的防护层:
- 输入过滤:检测注入攻击(如"; rm -rf")
- 输出审查:过滤不当内容
- 权限控制:敏感工具需二次确认
- 执行隔离:危险代码在沙箱中运行
6. 性能优化:让Agent快如闪电的秘诀
6.1 流式处理技巧
传统方式:等待所有工具调用完成再响应 → 用户等待时间长
优化方案:
python复制async def stream_agent(query):
tool_calls = identify_tools(query)
first_result = await run_first_tool(tool_calls[0])
yield format_partial_response(first_result) # 先返回部分结果
for tool in tool_calls[1:]:
result = await run_tool(tool)
yield format_update(result) # 流式更新
实测将端到端延迟从12秒降至3秒内。
6.2 缓存策略
构建三层缓存:
- 结果缓存:相同查询直接返回历史结果
- 工具缓存:高频工具结果保存1小时
- 语义缓存:相似查询复用历史处理
7. 从单Agent到多Agent系统
当业务逻辑复杂时,需要拆分子Agent。我们的电商系统架构:
code复制主控Agent(协调员)
├─ 商品检索Agent(ES专家)
├─ 价格计算Agent(财务专家)
└─ 推荐Agent(用户画像专家)
通信协议设计要点:
- 统一消息格式(JSON Schema)
- 超时重试机制
- 结果聚合策略
使用LangGraph实现的控制流:
python复制from langgraph import Graph
workflow = Graph()
workflow.add_node("product_search", product_agent)
workflow.add_node("pricing", price_agent)
workflow.add_edge("product_search", "pricing") # 定义执行顺序
这种架构使处理效率提升4倍,同时降低单个Agent的复杂度。
8. 商业落地:如何让Agent真正产生价值
8.1 效果评估指标体系
我们为客户建立的Agent评分卡:
| 维度 | 指标 | 目标值 |
|---|---|---|
| 功能 | 任务完成率 | ≥90% |
| 体验 | 平均响应时间 | <5秒 |
| 成本 | 每千次调用成本 | <$10 |
| 安全 | 违规次数 | 0 |
8.2 持续改进流程
建立"评估-优化"闭环:
- 每日抽取100条对话进行人工审核
- 标注问题类型(工具错误/逻辑缺陷/理解偏差)
- 针对性调整提示词或工具配置
- 每周AB测试验证改进效果
某客户案例数据:
- 初始任务完成率:68%
- 3个月优化后:92%
- 主要改进点:增强商品检索工具的描述准确性
9. 前沿方向:Agent技术的未来演进
虽然当前Agent还存在局限,但几个明确的发展趋势值得关注:
- 多模态能力:处理图像、语音等非文本输入
- 长期记忆:跨会话持续学习用户偏好
- 自我优化:自动调整提示词和工具使用策略
- 可信执行:实现可验证的决策过程
我在实际项目中最期待的是工具学习(Tool Learning)——让Agent能自动发现和使用新工具,就像人类学习使用新APP一样自然。这需要突破性的架构设计,可能会带来下一波Agent能力跃升。