
1. AgentScope框架概述
AgentScope是一款面向企业级应用的开源智能体框架,由阿里巴巴团队研发并维护。作为当前最先进的智能体开发平台之一,它提供了完整的工具链和抽象层,使开发者能够快速构建、部署和管理复杂的智能体系统。
1.1 框架定位与核心价值
AgentScope的核心理念是"开箱即用"与"灵活扩展"的平衡。不同于其他智能体框架,它既提供了高度封装的基础组件,又保留了足够的扩展接口。这种设计使得:
- 企业用户 可以直接使用预构建的模块快速搭建生产环境应用
- 研究团队 能够基于底层API进行深度定制和算法创新
- 个人开发者 可以轻松入门智能体开发,同时随着需求复杂度的提升保持技术栈的一致性
1.2 版本演进与架构革新
AgentScope经历了两次重大版本迭代:
0.x版本(基础版):
- 仅包含最基础的模型调用封装
- 提供简单的对话管理功能
- 适合单一智能体的简单场景
1.0版本(当前稳定版):
- 引入完整的四层架构(消息、记忆、模型、工具)
- 支持多智能体协作系统
- 内置企业级功能(监控、追踪、容错)
- 提供丰富的预集成第三方服务接口
这种架构演进反映了智能体技术从单一对话到复杂系统的转变趋势。最新版本特别强化了以下能力:
- 多模态数据处理
- 长期记忆管理
- 工具动态编排
- 分布式执行支持
2. 核心架构深度解析
AgentScope采用模块化设计,其基础层包含四个相互协作的核心模块,构成了完整的智能体运行环境。
2.1 架构全景图
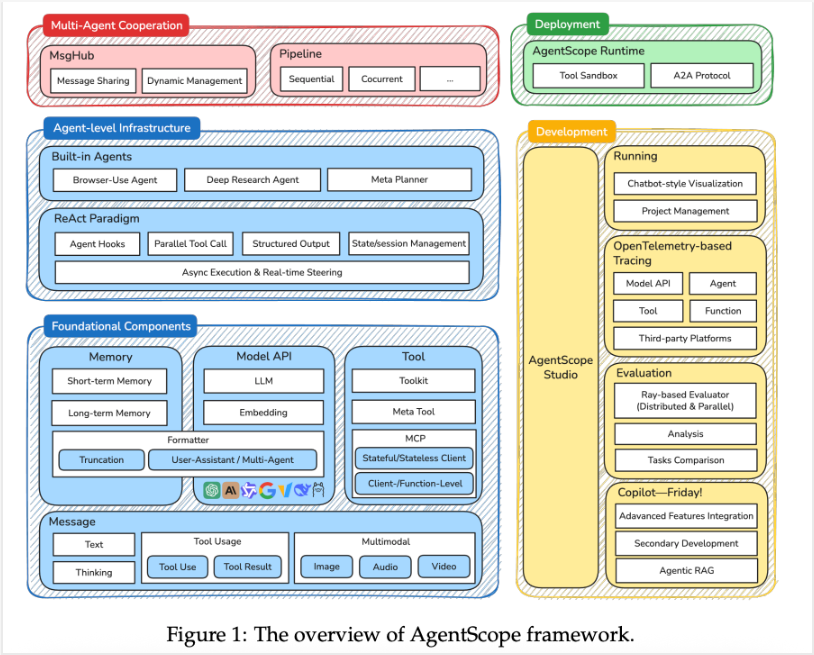
2.1.1 模块交互关系
四个核心模块通过明确的接口规范进行通信:
- Message模块:作为数据总线,负责所有模块间的信息传递
- Memory模块:提供状态持久化能力,支持短期上下文和长期知识存储
- Model模块:封装各类AI模型的调用逻辑,统一输入输出格式
- Tool模块:扩展智能体能力边界,将外部服务转化为可调用函数
这种设计实现了高内聚低耦合,开发者可以单独替换任一模块而不影响整体系统稳定性。
2.1.2 数据流设计
典型的工作流程如下:
- 用户输入通过Message模块标准化
- Memory模块检索相关上下文
- Model模块处理增强后的输入
- 需要工具调用时,Tool模块介入执行
- 结果再次通过Message模块传递,形成闭环
3. Message模块详解
作为框架的神经中枢,Message模块承担着信息标准化和路由的关键角色。
3.1 消息数据结构
Msg类是消息系统的核心载体,其设计具有以下特点:
python复制class Msg:
def __init__(
self,
name: str, # 消息发送者标识
role: str, # 系统角色(user/assistant/system)
content: list, # 内容块列表
**kwargs # 扩展元数据
):
self.name = name
self.role = role
self.content = content
self.metadata = kwargs
3.1.1 内容块类型系统
内容块采用插件式设计,主要类型包括:
| 类型 | 描述 | 典型应用场景 |
|---|---|---|
| TextBlock | 纯文本内容 | 常规对话、系统消息 |
| ImageBlock | 图像数据 | 视觉问答、图像生成 |
| AudioBlock | 音频数据 | 语音交互、音频处理 |
| VideoBlock | 视频数据 | 视频理解、多模态分析 |
| ToolUseBlock | 工具调用记录 | 功能扩展、API调用 |
| ToolResultBlock | 工具执行结果 | 结果反馈、流程继续 |
| ThinkingBlock | 推理过程 | 思维链展示、调试 |
3.2 多模态消息处理
AgentScope创新性地实现了真正的多模态统一处理。以下示例展示了如何构建包含多种媒体类型的复合消息:
python复制# 创建包含多模态数据的消息
multimodal_msg = Msg(
name="vision_agent",
role="assistant",
content=[
TextBlock(text="这张图片中的主要物体是:"),
ImageBlock(
source=Base64Source(
media_type="image/jpeg",
data="/9j/4AAQSkZ...", # 实际使用中替换为真实base64数据
)
),
AudioBlock(
source=UrlSource(
media_type="audio/mp3",
url="https://example.com/audio.mp3"
)
)
]
)
3.2.1 媒体源类型
AgentScope支持多种媒体来源格式:
-
Base64编码:适合小体积数据内联
python复制Base64Source( type="base64", media_type="image/png", data="iVBORw0KGgoAAAANSUhEUgAA..." ) -
URL引用:适合大文件远程访问
python复制UrlSource( type="url", media_type="video/mp4", url="https://example.com/video.mp4" ) -
文件指针:适合本地文件处理
python复制FileSource( type="file", media_type="application/pdf", path="/path/to/file.pdf" )
3.3 工具调用消息规范
当智能体决定使用工具时,会生成特定的工具调用消息。这类消息有严格的格式要求:
python复制tool_call = Msg(
name="system",
role="system",
content=[
ToolUseBlock(
id="req_123", # 唯一调用ID
name="get_weather", # 工具名称
input={"city": "北京"} # 输入参数
)
]
)
工具执行结果同样需要标准化:
python复制tool_result = Msg(
name="system",
role="system",
content=[
ToolResultBlock(
id="req_123", # 对应调用ID
name="get_weather", # 工具名称
output="北京:晴,25°C" # 执行结果
)
]
)
3.3.1 工具调用生命周期
完整的工具交互包含三个阶段:
- 决策阶段:模型生成ToolUseBlock
- 执行阶段:框架调用实际工具
- 反馈阶段:返回ToolResultBlock
这种设计确保了工具使用的可追踪性和调试便利性。
4. Memory模块实现原理
记忆系统是智能体保持连续性的关键,AgentScope采用分层存储架构,兼顾性能与持久性。
4.1 短期记忆(InMemoryMemory)
短期记忆模块维护对话的即时上下文,其实现具有以下特点:
4.1.1 核心数据结构
python复制class InMemoryMemory:
def __init__(self, max_size=20):
self.buffer = [] # 实际存储的消息列表
self.max_size = max_size # 容量限制
def add(self, msg: Msg):
"""添加新消息"""
self.buffer.append(msg)
if len(self.buffer) > self.max_size:
self.buffer.pop(0) # 移除最旧消息
def get(self, index=-1):
"""获取特定索引的消息"""
return self.buffer[index]
def clear(self):
"""清空缓冲区"""
self.buffer.clear()
4.1.2 智能体集成方式
短期记忆通常作为智能体的成员变量存在:
python复制class Agent:
def __init__(self):
self.short_term_memory = InMemoryMemory()
def process(self, msg: Msg):
# 处理前存入输入
self.short_term_memory.add(msg)
# ...处理逻辑...
# 处理后存入输出
self.short_term_memory.add(response)
4.1.3 高级功能
- 自动修剪:当达到max_size时自动移除最早的消息
- 权重衰减:可根据时间衰减旧消息的重要性分数
- 话题分割:自动检测对话话题变化并创建新上下文窗口
4.2 长期记忆(LongTermMemoryBase)
长期记忆抽象类定义了持久化存储的标准接口:
python复制class LongTermMemoryBase(ABC):
@abstractmethod
def record(self, key: str, value: Any):
"""记录结构化数据"""
@abstractmethod
def retrieve(self, query: str, top_k=3) -> list:
"""语义检索相关记忆"""
@abstractmethod
def record_to_memory(self, agent: Agent, msg: Msg):
"""由智能体决定的关键信息存储"""
@abstractmethod
def retrieve_from_memory(self, agent: Agent, query: str):
"""智能体发起的记忆检索"""
4.2.1 开发者API与智能体API的区别
| 特性 | 开发者API | 智能体API |
|---|---|---|
| 调用时机 | 任意时刻 | 仅在智能体运行时 |
| 控制粒度 | 精确控制 | 自动触发 |
| 使用场景 | 系统初始化、数据导入导出 | 运行时动态记忆存取 |
| 典型应用 | 知识库预加载 | 对话上下文增强 |
4.3 Mem0LongTermMemory实现
Mem0是AgentScope官方推荐的长期记忆实现,基于先进的向量检索技术。
4.3.1 初始化配置
python复制# 基础配置方式
memory = Mem0LongTermMemory(
model="text-embedding-3-small", # 嵌入模型
dimension=1536, # 向量维度
top_k=5 # 检索返回数量
)
# 高级配置方式
from mem0 import Mem0Config
config = Mem0Config(
embedding_endpoint="https://your-embedding-service",
cache_size=1000,
hybrid_search=True
)
memory = Mem0LongTermMemory(mem0_config=config)
4.3.2 核心能力
- 语义索引:自动将文本转换为向量并建立索引
- 混合检索:支持关键字与向量联合搜索
- 记忆演化:自动合并相似记忆,消除冗余
- 时效管理:为记忆添加时间衰减因子
4.3.3 典型工作流程
python复制# 记录关键信息
memory.record(
key="user_preference",
value={"theme": "dark", "language": "zh"}
)
# 语义检索
results = memory.retrieve("用户喜欢的界面风格")
# 返回:[{"theme": "dark", ...}]
5. Model模块架构设计
Model模块统一了各类AI模型的调用方式,大幅降低集成成本。
5.1 模型格式化器(Formatters)
5.1.1 格式化器工作原理
mermaid复制graph LR
A[原始Msg列表] --> B[ChatFormatter]
B --> C[供应商特定格式]
C --> D[API调用]
D --> E[标准化ChatResponse]
5.1.2 内置格式化器示例
| 供应商 | 格式化器类 | 特点 |
|---|---|---|
| OpenAI | OpenAIChatFormatter | 支持function calling |
| Anthropic | AnthropicFormatter | 强化XML标签处理 |
| 阿里云 | DashScopeChatFormatter | 优化多模态支持 |
| Gemini | GeminiFormatter | 简化嵌套结构 |
5.2 异步调用与流式响应
AgentScope的异步设计显著提升了系统吞吐量:
python复制# 同步调用
response = model.call(messages)
# 异步调用
async def process():
response = await model.call(messages)
# 流式响应处理
async for chunk in model.stream(messages):
print(chunk.content)
5.2.1 流式处理实现原理
python复制class ChatModelBase:
async def stream(self, messages):
# 建立连接
async with self._create_stream() as stream:
buffer = ""
async for partial in stream:
buffer += partial
yield ChatResponse(
content=[TextBlock(text=buffer)],
stream=True,
is_last=False
)
yield ChatResponse(
content=[TextBlock(text=buffer)],
stream=True,
is_last=True
)
5.3 统一响应结构(ChatResponse)
所有模型输出都归一化为ChatResponse对象:
python复制@dataclass
class ChatResponse:
id: str # 唯一ID
created: int # 时间戳
content: list # 内容块列表
usage: ChatUsage # token统计
model: str # 模型标识
stream: bool = False # 是否流式
is_last: bool = True # 是否最终块
5.3.1 用量统计对象
python复制@dataclass
class ChatUsage:
prompt_tokens: int # 输入token数
completion_tokens: int # 输出token数
total_tokens: int # 总token数
cost: float # 估算成本
latency: float # 响应延迟(秒)
5.4 DashScopeChatModel深度解析
阿里云模型集成的完整调用流程:
python复制class DashScopeChatModel(ChatModelBase):
async def __call__(self, messages, **kwargs):
# 1. 参数合并
kwargs = {**self.defaults, **kwargs}
# 2. 工具参数处理
if tools:
kwargs["tools"] = self._format_tools(tools)
# 3. 思考模式配置
if self.enable_thinking:
kwargs["enable_thinking"] = True
# 4. 结构化输出支持
if structured_model:
tool = self._create_tool(structured_model)
kwargs["tools"] = [tool]
kwargs["tool_choice"] = tool["name"]
# 5. 实际调用
if self.multimodality:
response = dashscope.MultiModalConversation.call(
api_key=self.api_key,
**kwargs
)
else:
response = await dashscope.aigc.generation.call(
api_key=self.api_key,
**kwargs
)
# 6. 标准化响应
return self._format_response(response)
5.4.1 关键设计决策
- 参数合并策略:明确规定了默认参数、实例参数和调用参数的优先级
- 工具处理逻辑:统一了普通工具和结构化输出的处理路径
- 错误处理机制:对阿里云特定错误码进行转换和标准化
- 性能优化:连接池管理和请求批处理
6. Tool模块实现机制
Tool模块是AgentScope最复杂的组件之一,实现了智能体能力的无限扩展。
6.1 工具生命周期管理
6.1.1 注册阶段
python复制def search(query: str, limit: int = 3):
"""执行网络搜索
Args:
query: 搜索关键词
limit: 返回结果数量
Returns:
list[str]: 搜索结果列表
"""
# 实际实现
return results
# 注册工具
toolkit.register_tool_function(
search,
group_name="web_services",
description="通用搜索引擎接口"
)
6.1.2 转换过程
注册时自动生成的JSON Schema示例:
json复制{
"name": "search",
"description": "执行网络搜索",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"limit": {"type": "integer", "default": 3}
},
"required": ["query"]
}
}
6.1.3 执行阶段
python复制# 工具调用消息示例
tool_call = {
"name": "search",
"input": {"query": "AgentScope最新版本"}
}
# 执行工具
async for result in toolkit.call_tool_function(tool_call):
print(result.content)
6.2 MCP管理架构
MCP(模型上下文协议)是AgentScope的远程服务集成方案。
6.2.1 双模式客户端对比
| 特性 | 有状态客户端 | 无状态客户端 |
|---|---|---|
| 连接方式 | 持久连接 | 按需连接 |
| 适用场景 | 需要会话保持的服务 | 简单查询服务 |
| 资源消耗 | 较高 | 较低 |
| 典型应用 | 网页自动化 | REST API调用 |
| 超时处理 | 自动重连 | 直接失败 |
6.2.2 本地代理示例
python复制@mcp_client(
endpoint="https://api.example.com/browser",
client_type="stateful"
)
class BrowserClient:
@mcp_method
def navigate(self, url: str):
"""访问指定URL"""
@mcp_method
def click(self, xpath: str):
"""点击页面元素"""
6.3 工具分组策略
分组管理解决了"工具过载"问题,其核心优势包括:
- 降低模型困惑度:缩小选择范围
- 节省上下文窗口:减少prompt长度
- 提升准确率:相关工具集中管理
- 动态能力调整:运行时激活/停用组
6.3.1 分组配置示例
python复制# 创建工具组
toolkit.create_tool_group(
name="data_analysis",
description="数据分析相关工具",
active=True,
notes="使用前需加载数据集"
)
# 注册工具到组
toolkit.register_tool_function(
plot_chart,
group_name="data_analysis"
)
# 动态切换组状态
toolkit.set_group_active("data_analysis", False)
6.4 核心方法实现
6.4.1 register_tool_function
该方法的关键处理逻辑:
python复制def register_tool_function(self, func, **kwargs):
# 1. 解析函数签名
sig = inspect.signature(func)
# 2. 从docstring提取描述
desc = parse_docstring(func.__doc__)
# 3. 构建参数schema
params = {
"type": "object",
"properties": {},
"required": []
}
for name, param in sig.parameters.items():
if name in ["self", "kwargs"]:
continue
param_schema = self._map_type(param.annotation)
params["properties"][name] = param_schema
if param.default == param.empty:
params["required"].append(name)
# 4. 注册到工具库
self.tools[func.__name__] = ToolDef(
name=func.__name__,
description=desc,
parameters=params,
original_func=func,
group=kwargs.get("group", "basic")
)
6.4.2 call_tool_function
工具执行的核心流程:
python复制async def call_tool_function(self, tool_call):
# 1. 查找工具
if tool_call.name not in self.tools:
return error_response("Tool not found")
tool = self.tools[tool_call.name]
# 2. 检查组状态
if not self.groups[tool.group].active:
return error_response("Tool group inactive")
# 3. 准备参数
kwargs = tool_call.input or {}
try:
# 4. 执行调用
if inspect.iscoroutinefunction(tool.original_func):
result = await tool.original_func(**kwargs)
else:
result = tool.original_func(**kwargs)
# 5. 后处理
if tool.postprocess:
result = tool.postprocess(result)
return success_response(result)
except Exception as e:
return error_response(str(e))
7. 实战经验与优化建议
在实际项目中使用AgentScope时,以下几个方面的经验值得特别关注:
7.1 性能优化技巧
-
记忆管理优化:
- 对短期记忆设置合理的大小限制(通常15-20条消息)
- 对长期记忆实现分层存储(热点数据内存缓存+冷数据持久化)
- 使用Mem0的批量操作接口减少IO开销
-
模型调用优化:
- 开启流式响应以降低端到端延迟
- 对多个独立请求使用asyncio.gather并行处理
- 合理设置超时参数避免长时间阻塞
-
工具执行优化:
- 对耗时工具实现异步版本
- 使用工具分组减少不必要的初始化
- 实现工具结果缓存(特别是对幂等操作)
7.2 调试与问题排查
-
消息流追踪:
python复制# 启用详细日志 import logging logging.basicConfig(level=logging.DEBUG) # 或在框架配置中设置 agentscope.set_log_level("DEBUG") -
记忆检查工具:
python复制def print_memory(agent): print("短期记忆:") for msg in agent.short_term_memory.buffer: print(f"- {msg.name}: {msg.content[:50]}...") if hasattr(agent, "long_term_memory"): print("长期记忆摘要:") print(agent.long_term_memory.stats()) -
工具调用验证:
python复制# 直接测试工具而不通过智能体 test_input = {"query": "test"} async for result in toolkit.call_tool_function( ToolUseBlock(name="search", input=test_input) ): print(result)
7.3 扩展开发建议
-
自定义记忆后端:
python复制class CustomMemory(LongTermMemoryBase): def __init__(self, db_connection): self.db = db_connection def record(self, key, value): self.db.insert("memories", {"key": key, "value": value}) def retrieve(self, query): return self.db.search( "memories", where("key").matches(query) ) -
集成新模型:
python复制class CustomModel(ChatModelBase): def __init__(self, api_key): self.client = CustomClient(api_key) async def call(self, messages, **kwargs): response = await self.client.chat( messages=self.formatter.format(messages), **kwargs ) return self.formatter.parse(response) -
开发高级工具:
python复制@tool class DatabaseQuery: def __init__(self, connection_string): self.conn = create_engine(connection_string) def __call__(self, query: str): """执行SQL查询 Args: query: 有效的SQL SELECT语句 """ return pd.read_sql(query, self.conn)
8. 典型应用场景分析
AgentScope的灵活架构使其适用于多种复杂场景,以下是几个典型案例:
8.1 智能客服系统
架构组成:
- 对话管理:处理多轮对话流程
- 知识检索:从长期记忆中获取产品信息
- 工单创建:通过工具集成CRM系统
- 情感分析:调用模型分析用户情绪
优势体现:
- 多技能无缝切换
- 保持对话一致性
- 复杂业务流处理
8.2 数据分析助手
工作流程:
- 用户提出分析需求
- 智能体检索相关数据集
- 选择适当的分析工具(统计/可视化)
- 生成解释性报告
关键技术点:
- 工具动态组合
- 大结果分块返回
- 自动代码生成与执行
8.3 多智能体协作系统
典型配置:
- 规划Agent:负责任务分解
- 执行Agent:专精特定工具
- 审核Agent:质量控制
- 协调Agent:解决冲突
通信机制:
- 通过Message模块路由
- 共享记忆空间
- 工具调用链式传递
9. 总结与展望
AgentScope作为新一代智能体框架,通过其精心设计的四大核心模块,为开发者提供了构建复杂智能体系统所需的全部基础设施。在实际项目中,我们特别体会到:
- 消息标准化的重要性:统一的数据格式是复杂系统可维护性的基础
- 记忆分层的实用价值:不同时间尺度的记忆需要不同的管理策略
- 工具抽象的生产力:将任意能力封装为统一接口极大扩展了智能体边界
- 模型无关设计的优势:保持核心逻辑稳定同时兼容技术快速演进
对于希望深入智能体开发的团队,建议:
- 从单一功能智能体开始,逐步增加复杂度
- 充分利用框架的扩展点进行定制
- 建立完善的测试体系(特别是工具集成部分)
- 监控关键指标(如工具调用成功率、记忆检索准确率)
随着AgentScope生态的持续发展,我们可以期待更多优秀实践和扩展组件的出现,进一步降低智能体系统的开发门槛。对于框架本身,以下方向的演进尤其值得关注:
- 更强大的分布式支持
- 可视化编排工具
- 增强的调试能力
- 自动优化组件