
1. 从失败到成功的3D建模探索之路
作为一名计算机视觉工程师,我最近花了大量时间研究基于多视角图像的3D重建技术。在这个过程中,我经历了无数次失败,也终于迎来了第一次成功的建模体验。今天想和大家分享一下这段跌宕起伏的技术探索历程,特别是如何从失败的案例中总结经验,最终实现室内静态场景的3D建模。
3D重建是计算机视觉领域的一个重要研究方向,它能够从二维图像中恢复出三维场景信息。这项技术在虚拟现实、增强现实、文物保护、自动驾驶等领域都有广泛应用。然而,在实际操作中,我发现要让算法稳定地输出高质量的3D模型并非易事,特别是在处理复杂场景时,往往会遇到各种意想不到的问题。
2. 前期失败的尝试与原因分析
2.1 动态广场场景的建模失败
我的第一个尝试是在一个动态广场场景中进行3D建模。这个场景的特点是相机位置固定,但场景中有大量移动的行人。我尝试了不同数量的输入图像(6张、10张、50张、100张甚至200张),但无一例外都失败了。
失败的根本原因在于特征匹配环节。由于场景中有大量移动的行人,导致不同图像之间的特征点对应关系极不稳定。我尝试使用黑色遮罩来过滤掉移动物体,但这样处理后每张图像保留的特征点太少,仍然无法建立可靠的特征匹配。
关键教训:在动态场景中,移动物体会严重干扰特征匹配过程。如果必须处理这类场景,可以考虑使用更先进的运动分割算法,或者选择在人群稀少的时间段采集数据。
2.2 静态房间的动态多视角尝试
第二个尝试是在一个静态房间中使用动态多视角图像进行建模。这里的"动态多视角"指的是相机在移动过程中拍摄的一系列图像。理论上,这种设置应该更适合3D重建,因为场景本身是静态的。
然而,这次尝试同样以失败告终。经过分析,主要原因有两个:
- 不同视角之间的重叠区域不足
- 焦点变化导致特征匹配困难
由于可用的图像数量有限,且视角变化较大,算法无法建立足够的特征点对应关系,导致稀疏点云构建失败。
3. 成功的关键:静态多视角室内数据集
3.1 数据集的选择与准备
在经历了多次失败后,我决定改变策略,寻找更适合3D重建的数据集。经过调研,我发现了两个潜在的选择:
-
Panoptic Studio数据集:由斯坦福大学提供,包含120路同步摄像头(54个RGB+66个深度)的环形分布数据,相邻摄像头重叠率超过80%。这个数据集理论上非常理想,但需要申请权限,流程较为复杂。
-
Replay Dataset:由Meta(原Facebook)发布,包含多视角同步视频。我最终选择了这个数据集,因为它可以直接下载使用,且包含静态场景部分。
从Replay Dataset中,我选择了SC-1001_GOPRO-3相机的视频片段。这段视频前64秒是相机围绕静态场景旋转拍摄的,场景中的人物和物体都保持静止。通过每隔1秒截取一帧,我获得了64张不同视角的图像,这些图像具有很高的重叠度,非常适合3D重建。
3.2 数据预处理技巧
在开始正式建模前,我对图像进行了一些必要的预处理:
- 图像筛选:检查所有图像,确保没有模糊或过曝的情况
- 格式统一:将所有图像转换为相同的格式和分辨率
- 文件命名:采用有规律的命名方式,便于后续处理
这些看似简单的步骤实际上非常重要,可以避免很多后续处理中的问题。
4. 基于COLMAP的3D重建流程详解
4.1 稀疏重建:建立基础几何结构
稀疏重建是3D建模的第一步,目的是从图像中提取特征点并建立它们之间的对应关系,从而恢复相机位置和稀疏场景结构。
bash复制# 步骤1:创建COLMAP数据库
colmap database_creator --database_path database.db
# 步骤2:特征提取(使用CPU模式)
export QT_QPA_PLATFORM=offscreen
xvfb-run colmap feature_extractor \
--database_path database.db \
--image_path /path/to/images \
--SiftExtraction.use_gpu 0
# 步骤3:特征匹配
colmap exhaustive_matcher \
--database_path database.db \
--SiftMatching.use_gpu 0 \
--SiftMatching.max_num_matches 4
# 步骤4:三角化生成稀疏点云
colmap point_triangulator \
--database_path database.db \
--image_path /path/to/images \
--input_path colmap_sparse/0 \
--output_path ./colmap_sparse/triangulated
在这个阶段,有几个关键参数需要注意:
SiftExtraction.use_gpu:是否使用GPU加速SiftMatching.max_num_matches:控制特征匹配数量- 图像路径和输出路径需要根据实际情况调整
4.2 稠密重建:生成完整场景几何
稀疏重建完成后,接下来是稠密重建,目的是生成更密集、更完整的场景点云。
bash复制# 步骤1:图像去畸变
colmap image_undistorter \
--image_path /path/to/images \
--input_path sparse/0 \
--output_path dense \
--output_type COLMAP
# 步骤2:PatchMatch立体匹配
colmap patch_match_stereo \
--workspace_path dense \
--workspace_format COLMAP \
--PatchMatchStereo.geom_consistency true \
--PatchMatchStereo.filter true \
--PatchMatchStereo.num_samples 15 \
--PatchMatchStereo.max_image_size 2000 \
--PatchMatchStereo.num_iterations 5
# 步骤3:立体融合生成稠密点云
colmap stereo_fusion \
--workspace_path dense \
--workspace_format COLMAP \
--input_type geometric \
--output_path dense/fused.ply \
--StereoFusion.min_num_pixels=3 \
--StereoFusion.max_reproj_error=4
稠密重建阶段最耗时的部分是PatchMatch立体匹配,这个步骤对硬件要求较高。在我的实验中,640张图像的稠密重建花费了约12小时(使用24线程CPU)。
4.3 表面重建:从点云到3D模型
最后一步是将稠密点云转换为连续的3D网格模型。
bash复制colmap poisson_mesher \
--input_path dense/fused.ply \
--output_path dense/meshed-poisson.ply
Poisson表面重建算法能够从噪声点云中重建出平滑的表面,适合处理室内场景。重建完成后,可以使用MeshLab等工具查看和编辑生成的3D模型。
5. 实验结果分析与优化尝试
5.1 首次成功:64帧图像的结果
使用64张间隔1秒的图像,我首次成功重建出了室内场景的3D模型。虽然模型质量还有待提高,但基本结构已经能够辨认。这个结果验证了我的方法在静态多视角场景中的可行性。
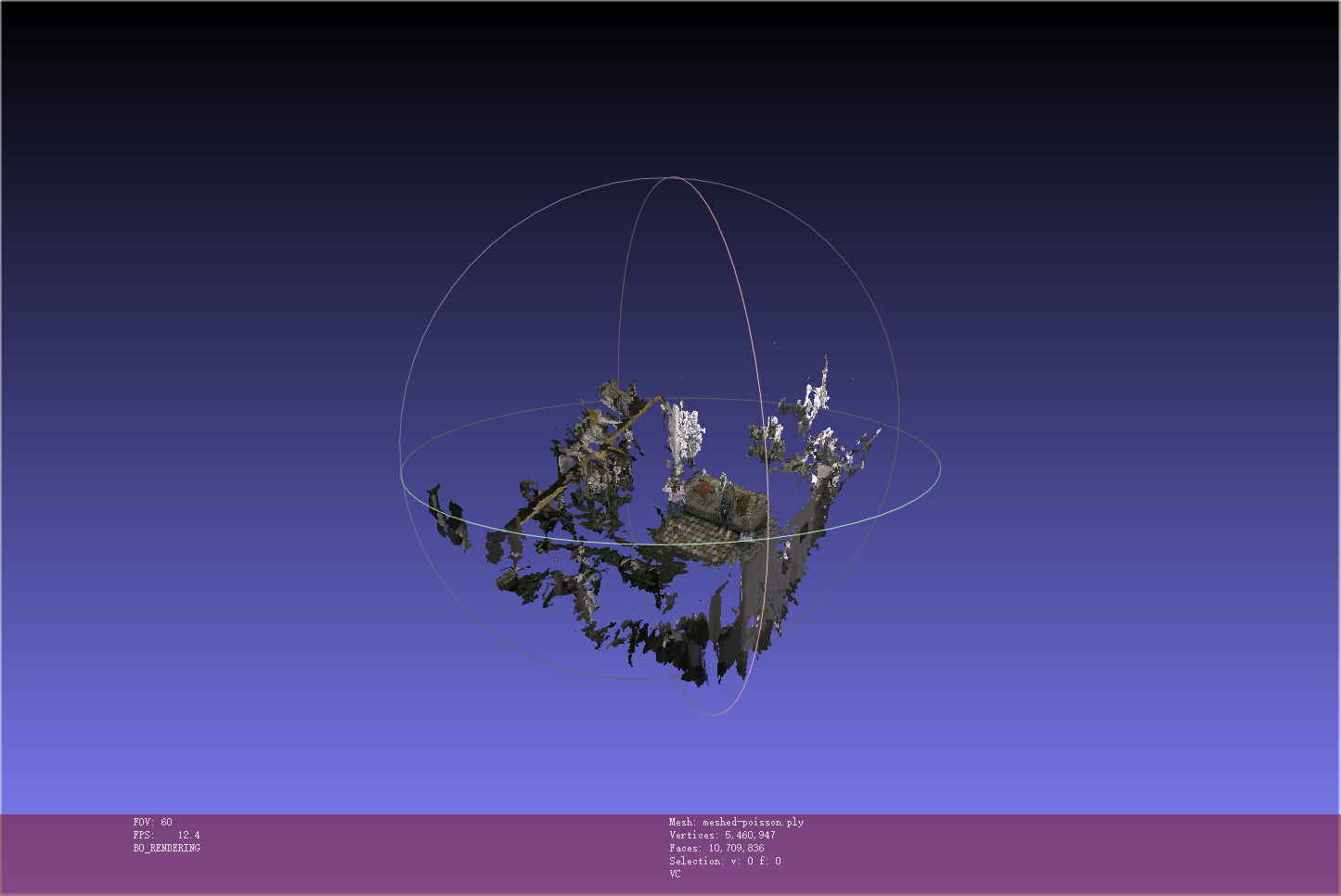
从结果可以看出:
- 主要家具的轮廓已经能够辨认
- 墙面和地面的几何结构基本正确
- 细节部分(如小物件)还不够清晰
5.2 增加数据量:640帧图像的尝试
为了提升模型质量,我将图像数量增加到640张(间隔0.1秒)。理论上,更多的输入图像应该能带来更好的重建效果,但实际结果却出乎意料。
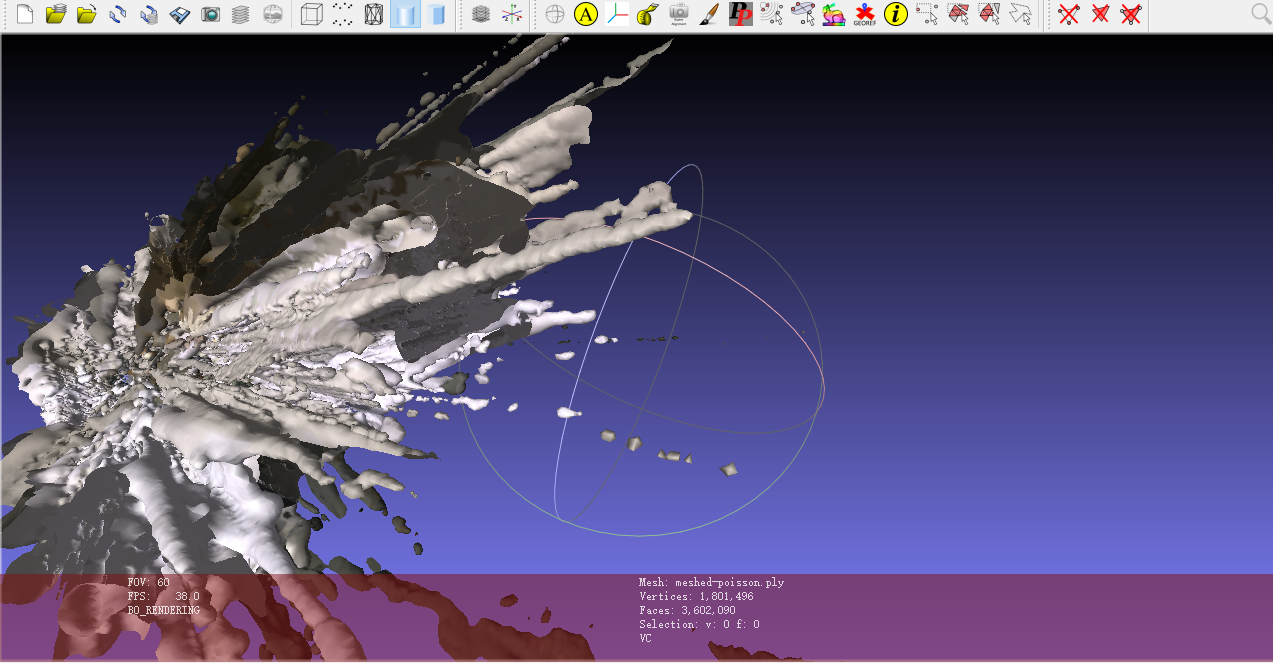
这次重建得到的模型反而更加混乱,出现了大量不合理的几何结构。经过分析,可能的原因包括:
- 图像间变化太小,导致特征匹配混淆
- 计算误差累积效应
- 需要调整算法参数以适应更高密度的输入
这个结果说明,在3D重建中,并不是输入数据越多越好,需要根据场景特点和算法能力找到合适的平衡点。
6. 3D建模工具链的深度解析
在探索过程中,我对各种3D建模工具进行了调研,以下是它们在不同场景下的适用性分析:
| 工具名称 | 适用场景 | 在纯图反演中的作用 | 学习曲线 |
|---|---|---|---|
| COLMAP | 从图像重建3D模型 | 核心工具,完成重建全流程 | 中等 |
| Blender | 3D建模与渲染 | 后期处理与优化 | 陡峭 |
| 3ds Max | 专业3D建模 | 不直接相关 | 陡峭 |
| Maya | 动画与特效 | 不直接相关 | 陡峭 |
| ZBrush | 数字雕刻 | 不直接相关 | 陡峭 |
| C4D | 运动图形 | 不直接相关 | 中等 |
| Unreal Engine | 实时渲染 | 可视化与交互 | 中等 |
对于基于图像的3D重建任务,COLMAP是最核心的工具,而Blender和Unreal Engine可以作为后期处理和可视化的辅助工具。其他工具更多用于专业的3D内容创作,与自动重建流程关系不大。
7. 实战经验与避坑指南
7.1 数据采集的最佳实践
- 视角重叠:相邻图像间应有60%-80%的重叠区域
- 光照条件:尽量保持光照一致,避免强烈阴影
- 场景复杂度:包含足够多的纹理特征,但不要过于杂乱
- 相机运动:平滑的相机运动,避免剧烈变化
7.2 COLMAP参数调优心得
-
特征提取:
- 对于高分辨率图像,可以增加
SiftExtraction.max_image_size - 在纹理丰富的场景中,可以降低
SiftExtraction.peak_threshold
- 对于高分辨率图像,可以增加
-
特征匹配:
- 对于高重叠度序列,
exhaustive_matcher通常足够 - 对于无序图像集,考虑使用
vocab_tree_matcher
- 对于高重叠度序列,
-
稠密重建:
PatchMatchStereo.num_samples影响细节程度,但会增加计算量PatchMatchStereo.geom_consistency应保持开启以提高精度
7.3 常见问题与解决方案
-
特征匹配失败:
- 检查图像间是否有足够重叠
- 尝试调整特征提取参数
- 考虑使用更鲁棒的特征描述符
-
重建结果破碎:
- 检查相机参数是否正确
- 尝试不同的三角化方法
- 增加输入图像数量(但不要过度)
-
模型细节缺失:
- 提高稠密重建的质量设置
- 考虑使用更高分辨率的输入图像
- 尝试不同的表面重建算法
8. 未来改进方向
虽然已经取得了初步成功,但当前的3D建模结果还有很大的提升空间。以下是我计划尝试的改进方向:
- 多尺度特征融合:结合不同尺度的特征提取,提升重建细节
- 语义分割辅助:使用语义信息指导重建过程,改善物体边界
- 深度学习增强:尝试基于学习的深度估计和三维重建方法
- 实时重建优化:研究增量式重建算法,实现近实时建模
在实际操作中,我发现3D重建是一个需要耐心和细致的工作。每个场景都有其独特性,需要根据具体情况调整方法和参数。这次成功的经验让我更加理解了计算机视觉中几何重建的核心原理,也为后续的研究打下了坚实基础。