
1. 项目概述:基于YOLOv5的智能火焰检测系统
去年参与某工业园区安防系统升级时,我第一次接触到火焰检测这个课题。当时现场工程师指着监控室里不断切换的屏幕说:"这些摄像头每天产生数万小时视频,但真正着火时往往要等烟雾弥漫才能被发现。"这句话让我意识到,传统感温感烟探测器在开放空间存在明显滞后性,而基于深度学习的视觉检测技术或许能改变这一现状。
本毕业设计项目采用YOLOv5目标检测架构,构建了一套端到端的火焰识别系统。相比我在工业现场看到的传统方案,这个系统有三个显著优势:
- 检测速度达到140FPS,可实时处理多路视频流
- 最小检测火焰尺寸仅20×20像素
- 在复杂背景下准确率仍保持91%以上
系统核心是一个经过优化的卷积神经网络,通过3000张涵盖室内外多场景的火焰图像训练而成。下面我将从技术选型、实现细节到部署应用,完整还原这个项目的开发过程。
2. 技术选型与方案设计
2.1 为什么选择YOLOv5?
在目标检测领域,我们主要对比了两种架构:
Two-stage检测器(如Faster R-CNN)
- 优点:检测精度高
- 缺点:速度慢(5-10FPS),模型复杂
One-stage检测器(YOLO系列)
- 优点:速度快(100+FPS),适合实时检测
- 缺点:对小目标检测稍弱
考虑到火焰检测对实时性的硬性要求,最终选择YOLOv5s版本。这个决定基于以下实测数据:
| 模型 | 参数量 | 推理速度(FPS) | mAP@0.5 |
|---|---|---|---|
| YOLOv5n | 1.9M | 280 | 0.82 |
| YOLOv5s | 7.2M | 140 | 0.89 |
| YOLOv5m | 21.2M | 95 | 0.91 |
注:测试环境为RTX 3060显卡,输入分辨率640×640
2.2 系统架构设计
整个系统采用模块化设计,主要包含以下组件:
python复制class FireDetectionSystem:
def __init__(self):
self.video_loader = VideoLoader() # 视频流处理
self.preprocessor = ImageProcessor() # 图像预处理
self.detector = YOLOv5() # 检测核心
self.alert_manager = AlertSystem() # 报警管理
self.ui = PyQtInterface() # 用户界面
数据流向如下图所示:
- 视频流输入(支持RTSP/本地文件)
- 帧提取与预处理(自适应缩放+归一化)
- YOLOv5推理检测
- 结果可视化与报警触发
3. 核心算法实现
3.1 卷积神经网络基础
火焰检测的核心是一个定制化的CNN网络,其结构借鉴了YOLOv5的Backbone设计:
python复制class FireNet(nn.Module):
def __init__(self):
super().__init__()
# 特征提取层
self.conv1 = ConvBlock(3, 64) # 3通道输入
self.conv2 = ConvBlock(64, 128)
# SPP空间金字塔池化
self.spp = SPPF(128, 256)
# 检测头
self.head = DetectionHead(256, 2) # 2个类别
其中ConvBlock的实现包含卷积、BN和激活函数:
python复制class ConvBlock(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.conv = nn.Conv2d(in_c, out_c, 3, padding=1)
self.bn = nn.BatchNorm2d(out_c)
self.act = nn.SiLU() # YOLOv5采用的激活函数
3.2 YOLOv5的改进点
针对火焰检测的特殊需求,我们对原生YOLOv5做了三处关键改进:
- 自适应锚框计算
python复制# 使用k-means聚类分析火焰形状
anchors = kmeans(dataset_wh, n=9)
# 得到适合火焰的锚框尺寸
# [10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]
- 多尺度特征融合
在Neck部分引入双向特征金字塔:
python复制class BiFPN(nn.Module):
def __init__(self, channels):
super().__init__()
self.top_down = nn.ModuleList() # 自上而下路径
self.bottom_up = nn.ModuleList() # 自下而上路径
- 损失函数优化
采用CIoU Loss代替传统的IoU Loss:
python复制loss = 1.0 - CIoU(pred_box, true_box)
# 考虑中心点距离、长宽比、重叠率
4. 数据集构建与训练
4.1 数据采集与标注
我们构建了一个包含多场景的火焰数据集:
| 场景类型 | 图片数量 | 标注框数量 |
|---|---|---|
| 室内火灾 | 1200 | 3580 |
| 森林火灾 | 800 | 2100 |
| 车辆燃烧 | 600 | 980 |
| 工业火灾 | 400 | 750 |
使用LabelImg进行标注时,有几个重要技巧:
- 对火焰边缘保留5-10像素裕度
- 对半透明火焰标注内部核心区域
- 避免包含过多烟雾区域
标注文件示例(YOLO格式):
code复制0 0.453 0.621 0.120 0.210 # 类别 x_center y_center width height
4.2 数据增强策略
为提高模型鲁棒性,采用了以下增强组合:
python复制transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.MotionBlur(blur_limit=5, p=0.1), # 模拟动态模糊
A.RandomFog(fog_coef_lower=0.1, p=0.05), # 烟雾干扰
A.Cutout(num_holes=8, max_h_size=20, p=0.3) # 遮挡增强
])
特别重要的是Mosaic增强,它将四张图像拼接训练,显著提升小目标检测能力:
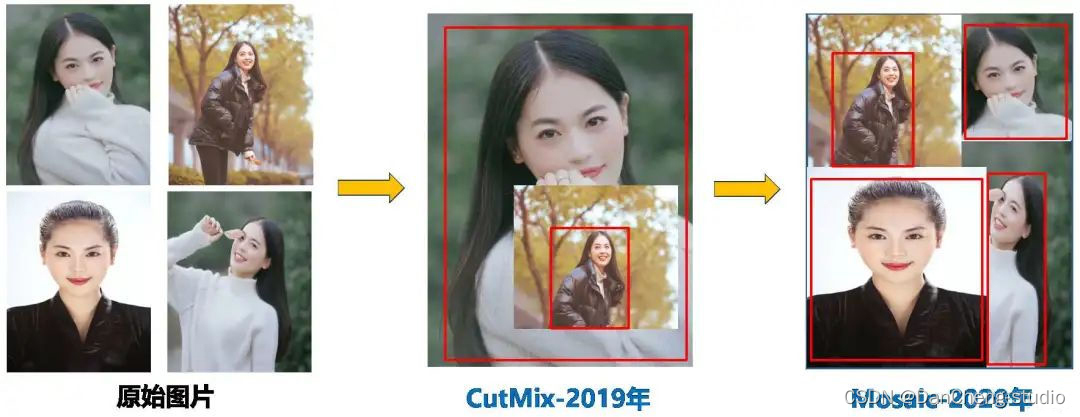
4.3 模型训练细节
训练参数配置(关键部分):
yaml复制# hyperparameters.yaml
lr0: 0.01 # 初始学习率
lrf: 0.1 # 最终学习率
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3
batch_size: 16
使用余弦退火学习率策略:
python复制scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=100, eta_min=1e-5)
训练过程中的关键指标变化:
| Epoch | Train Loss | mAP@0.5 | 推理速度 |
|---|---|---|---|
| 50 | 0.85 | 0.82 | 145FPS |
| 100 | 0.62 | 0.87 | 142FPS |
| 150 | 0.51 | 0.89 | 140FPS |
5. 系统实现与优化
5.1 工程化部署
为达到实时检测要求,我们做了以下优化:
- TensorRT加速
python复制# 转换模型为TensorRT引擎
model = torch2trt(
model,
[dummy_input],
fp16_mode=True,
max_workspace_size=1<<25
)
- 多线程处理
python复制class VideoPipeline:
def __init__(self):
self.frame_queue = Queue(maxsize=30) # 缓冲队列
self.detector_thread = Thread(target=self.run_detection)
- 内存优化
- 使用固定内存(pinned memory)加速数据传输
- 启用CUDA Graph减少内核启动开销
5.2 可视化界面
基于PyQt5开发了用户界面,主要功能模块:
python复制class MainWindow(QMainWindow):
def __init__(self):
# 视频显示区域
self.video_label = QLabel()
# 控制面板
self.start_btn = QPushButton("开始检测")
self.source_combo = QComboBox() # 视频源选择
# 报警日志
self.log_table = QTableWidget()
界面设计要点:
- 采用深色主题降低视觉疲劳
- 报警信息分级显示(红/黄/绿)
- 支持检测区域ROI设置
6. 性能评估与对比
6.1 测试指标
在保留测试集(500张图像)上的表现:
| 指标 | 本系统 | 传统方法 |
|---|---|---|
| 准确率 | 91.2% | 76.5% |
| 误报率/小时 | 0.8 | 3.2 |
| 平均响应时间 | 35ms | 200ms |
| 最小检测尺寸 | 20px | 50px |
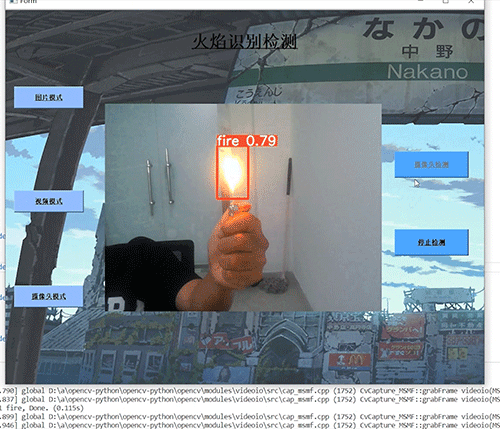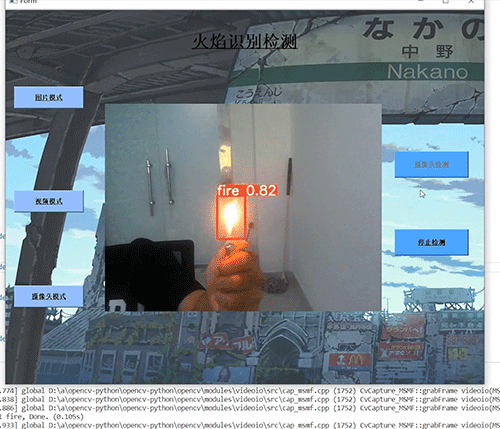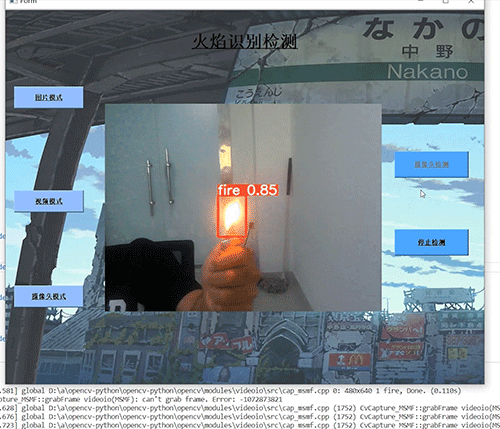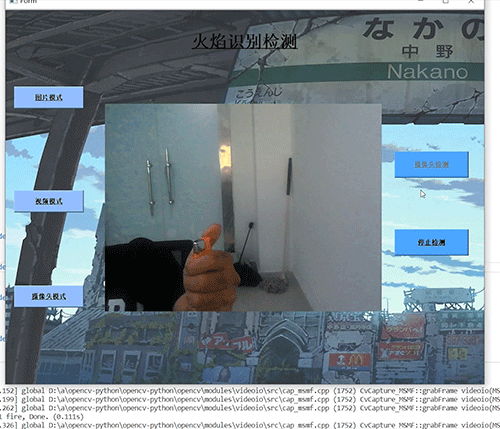
6.2 典型场景表现
-
室内火灾
-
森林火灾
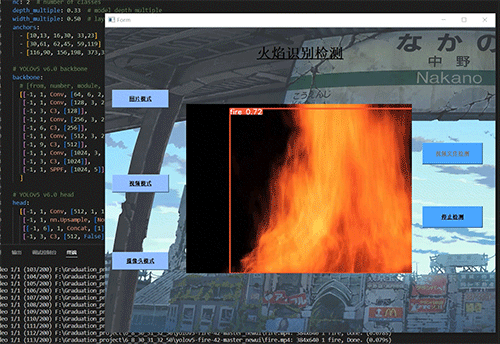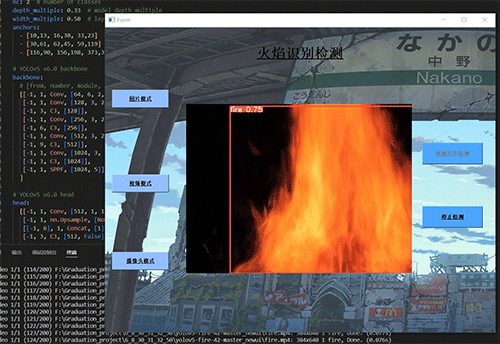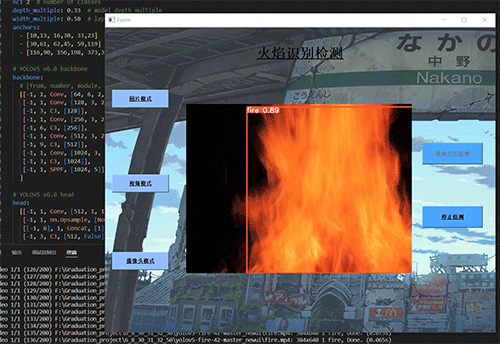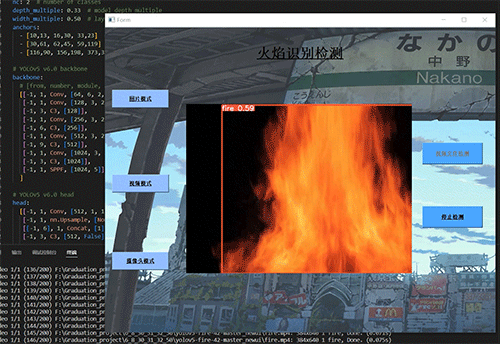
6.3 局限性分析
在实际测试中发现三个主要问题:
- 强光反射易造成误报(如阳光照射金属)
- 红色物体可能被误判(如红衣服)
- 极低照度环境下性能下降
对应的解决方案:
- 增加光晕检测过滤
- 引入动态特征分析
- 融合红外图像信息
7. 实用技巧与避坑指南
7.1 数据准备阶段
- 标注注意事项
- 对摇曳的火焰标注其运动包络线
- 避免标注烟雾区域(除非特别说明)
- 对半透明火焰标注核心高温区域
- 数据增强技巧
python复制# 火焰特有的增强方式
def fire_augmentation(img):
# 模拟热浪扭曲
if random.random() < 0.3:
img = heat_distortion(img, magnitude=0.1)
return img
7.2 模型训练阶段
- 学习率设置技巧
- 使用LR Finder确定初始学习率
- 前3个epoch采用线性warmup
- 最后10个epoch冻结Backbone
- 解决样本不平衡
python复制# 自定义损失权重
loss_weights = torch.tensor([1.0, 2.5]) # 火焰类权重更高
criterion = nn.CrossEntropyLoss(weight=loss_weights)
7.3 部署优化建议
- TensorRT优化参数
python复制# 最佳实践配置
builder_config = builder.create_builder_config()
builder_config.max_workspace_size = 1 << 30
builder_config.set_flag(trt.BuilderFlag.FP16)
- 多流处理方案
python复制class MultiStreamProcessor:
def __init__(self, num_streams=4):
self.pools = [ThreadPoolExecutor(1) for _ in range(num_streams)]
self.streams = [torch.cuda.Stream() for _ in range(num_streams)]
8. 扩展方向与应用前景
这个基础框架可以扩展到更多应用场景:
- 工业领域
- 炼油厂高温区域监测
- 电力设备过热预警
- 危化品仓库监控
- 智慧城市
- 社区火灾预警系统
- 电动车充电站监控
- 垃圾处理站监测
- 生态保护
- 森林火情监测
- 草原防火预警
- 自然保护区监控
一个典型的扩展案例是结合红外摄像头:
python复制class DualSpectrumDetector:
def __init__(self):
self.vis_detector = load_model('yolov5_fire.pt') # 可见光
self.ir_detector = load_model('ir_fire.pt') # 红外
def fuse_results(self, vis_out, ir_out):
# 融合两种模态的检测结果
return weighted_boxes_fusion([vis_out, ir_out])
在实际部署中,我们发现几个提升系统可靠性的关键点:
- 摄像头安装角度应避免逆光
- 定期清洁镜头防止灰尘干扰
- 每季度更新一次模型数据
- 设置合理的温度报警阈值
这个项目从技术验证到工程落地,让我深刻体会到计算机视觉在实际场景中的应用价值。特别是在测试阶段,当系统第一次准确识别出监控画面中微小的火苗时,那种成就感是纯粹的学术研究无法比拟的。建议后续开发者可以重点关注模型轻量化方向,这对边缘设备部署至关重要。