
1. 视觉Token压缩技术综述:四大前沿方法深度解析
在当今多模态大模型(MLLMs)快速发展的背景下,视觉Token的高效处理已成为提升模型性能的关键瓶颈。本周我深入研读了四篇关于视觉Token压缩的前沿论文,这些研究从不同角度提出了创新性的解决方案。本文将系统性地解析这些方法的核心理念、技术实现和实际效果,帮助读者全面把握这一领域的最新进展。
视觉Token压缩的核心挑战在于:如何在保持语义完整性的同时,显著减少输入序列长度。传统方法往往面临语义覆盖不全、计算冗余或适应性不足等问题。这四篇论文分别从语义感知合并、编码器优化和查询引导压缩三个方向进行了突破性探索。
2. LLaVA-Scissor:基于语义连通组件的视频Token压缩
2.1 方法概述与核心创新
LLaVA-Scissor提出了一种免训练的两步时空Token压缩策略,专门针对视频多模态大语言模型设计。其核心创新在于引入了语义连通组件(Semantic Connected Components, SCC)的概念,通过图论方法实现Token的智能合并。
传统基于注意力分数的方法存在明显局限:它们只能识别局部相关性,无法保证全局语义覆盖。如图1所示,基于注意力的方法(左)会产生语义"盲区",而基于分段的方法(中)则引入时间冗余。LLaVA-Scissor的两步策略(右)则能同时解决这两个问题。
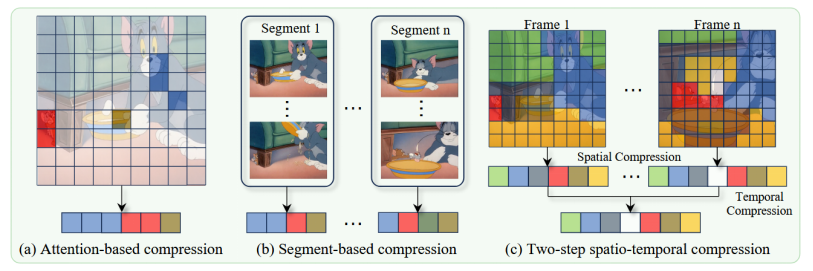
2.2 关键技术实现细节
2.2.1 语义连通组件(SCC)算法
SCC算法的实现包含三个关键步骤:
- 图构建:将每个Token视为图节点,计算两两之间的余弦相似度作为边权重
- 阈值过滤:只保留相似度高于预设阈值τ的边(论文通过实验确定τ=0.7为最优值)
- 连通组件识别:使用Union-Find算法找出图中的连通组件,每个组件代表一个独特语义区域
该算法的优势在于:
- 不依赖空间位置信息,能捕捉全局语义关系
- 保证不同语义区域之间无重叠,实现全面覆盖
- 每个组件只保留最具代表性的Token,实现高效压缩
2.2.2 两步时空压缩流程
-
空间压缩阶段:
- 对视频的每一帧独立应用SCC算法
- 提取该帧内所有独特的语义区域
- 生成每帧的代表性Token集合
-
时间压缩阶段:
- 将所有帧的代表性Token拼接
- 再次应用SCC算法去除跨帧重复语义
- 得到最终的非重叠语义Token集
-
Token合并:
- 将原始所有Token与最终代表Token进行相似度匹配
- 每个Token被合并到最相似的语义组件中
- 输出压缩后的Token序列
2.3 实验验证与性能分析
论文在多个视频理解基准上进行了全面评估,包括视频问答、长视频理解和综合多选题等任务。关键发现包括:
-
压缩效率:
- 在保留比例35%时,性能与原模型基本持平
- 即使压缩到3%的极端情况,仍保持86.8%的原始性能
- 显著优于对比方法(如FastV高出6.1个百分点)
-
冗余性验证:
- 当保留比例在90%-35%区间时,多数方法性能接近原模型
- 证明视频Token确实存在大量可压缩的冗余信息
-
参数分析:
- 相似度阈值τ对压缩率影响显著:τ越低,压缩越强
- 误差容忍度ϵ在≤0.05时效果稳定,最终设为0.05
实践建议:在实际应用中,建议先通过小规模实验确定适合特定数据集的τ和ϵ值。通常,动态场景需要更高的τ值,而静态场景可适当降低。
3. FastVLM:高效视觉编码器设计与优化
3.1 问题背景与创新思路
FastVLM从视觉编码器本身入手,通过架构优化实现Token数量的源头减少。其核心发现是:传统ViT架构在高分辨率图像处理上存在效率瓶颈,而混合架构能更好地平衡性能与效率。
论文进行了全面的效率分析,揭示了几个关键现象:
- 高分辨率导致视觉Token数量二次方增长
- LLM预填充时间与Token数量线性相关
- 视觉编码延迟随分辨率提升而急剧增加
3.2 FastViTHD编码器设计
3.2.1 核心架构创新
FastViTHD的主要设计特点包括:
-
极致下采样:
- 引入第5个下采样阶段,总下采样倍率达64倍
- 相同输入分辨率下,Token数量仅为ViT的1/16
-
混合阶段设计:
- 浅层使用卷积提取局部特征
- 中层采用轻量级Transformer捕获全局关系
- 深层进行多尺度特征融合
-
多尺度特征融合:
- 提取不同阶段的特征图
- 使用深度可分离卷积(DWConv)进行跨尺度融合
- 补充高层语义信息
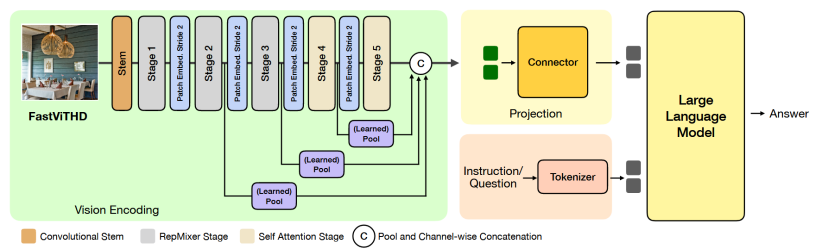
3.2.2 训练策略优化
论文提出了分阶段训练策略:
- Stage 1:投影层训练,建立视觉-语言关联
- Stage 1.5:分辨率适应,逐步提升输入尺寸
- Stage 2:指令微调,增强任务适应性
- Stage 3:高质量指令微调,提升最终性能
3.3 性能对比与实验发现
FastVLM在多个维度上展现出显著优势:
-
效率提升:
- 首Token生成时间(TTFT)提升3.2倍
- 与LLaVA-OneVision相比,TTFT提升85倍
- 视觉编码器尺寸缩小3.4倍
-
精度保持:
- 在768分辨率下,性能优于ViT-L/14@336
- 关键基准测试上表现优于对比模型
-
架构对比发现:
- 混合架构显著优于纯Transformer
- 架构性下采样优于后处理剪枝
- 静态分辨率通常优于动态分辨率
开发经验:在实际部署时,建议根据LLM大小选择合适的分辨率。小型LLM(如0.5B)的最佳分辨率通常较低,而大型LLM(7B+)才能充分发挥高分辨率的优势。
4. QG-VTC:问题引导的视觉Token压缩
4.1 方法核心思想
QG-VTC创新性地将用户问题作为压缩依据,实现"按需压缩"。其核心观点是:图像中存在大量与当前问题无关的信息,传统无差别压缩会导致关键细节丢失。
该方法的主要特点包括:
- 问题引导:利用问题文本动态确定Token重要性
- 分层压缩:在编码器内部多阶段逐步压缩
- 软压缩机制:通过注意力加权保留有用信息
4.2 关键技术实现
4.2.1 压缩模块设计
QG-VTC的压缩流程包含以下步骤:
-
问题嵌入:
- 使用预训练文本编码器处理问题
- 通过可学习层映射到视觉特征空间
-
相关性计算:
- 计算问题嵌入与每个视觉Token的相似度
- 生成相关性分数矩阵C
-
Token划分:
- 保留组:CLS Token + 前n个高相关Token
- 压缩组:剩余低相关Token
-
软压缩:
- 压缩组Token按注意力权重分配到保留组
- 实现信息的有选择保留
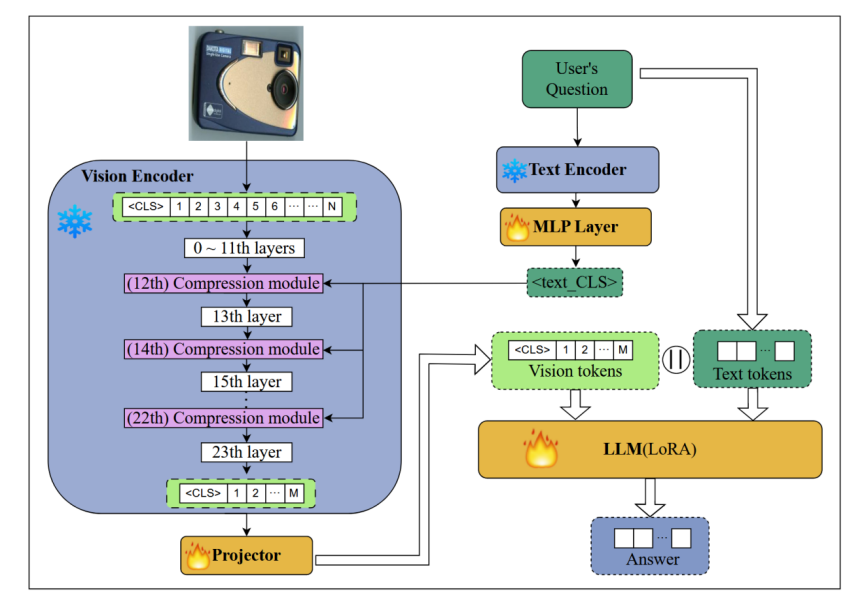
4.2.2 分层压缩策略
QG-VTC采用分层压缩策略,在多个Transformer层中逐步压缩:
- 第6层:首次压缩,保留率50%
- 第13层:二次压缩,保留率25%
- 第19层:最终压缩,保留率12.5%
这种渐进式压缩的优势在于:
- 避免信息突然丢失
- 允许Token在压缩间重新交互
- 显著减少后续层计算量
4.3 实验效果与应用建议
QG-VTC在多个VQA基准上取得SOTA结果,仅用1/8的视觉Token即可匹配原始模型性能。实际应用时需注意:
- 问题特异性:压缩效果高度依赖问题质量
- 领域适配:不同任务可能需要调整压缩比例
- 计算节省:整体计算负载降低约30%
优化技巧:可以引入问题重述或扩展机制,提升问题表述的清晰度和完整性,从而改善压缩效果。
5. Glyph:基于视觉-文本压缩的长上下文处理
5.1 方法概述与创新点
Glyph提出了一种全新的长文本处理范式:将文本渲染为图像,利用VLM的高效视觉理解能力实现压缩。其核心创新包括:
- 渲染配置搜索:LLM驱动的遗传算法自动优化
- 持续预训练:多风格文本渲染增强泛化能力
- 后训练优化:三阶段微调提升任务性能
5.2 关键技术细节
5.2.1 渲染管道设计
Glyph的渲染过程由配置向量θ控制,包括:
- 分辨率:影响图像清晰度
- 页面尺寸:决定信息密度
- 字体样式:影响可读性
- 排版参数:行距、缩进等
压缩比计算公式:
code复制CR = (原始Token数) / (图像Token数)
典型压缩比可达3-4倍。
5.2.2 LLM驱动的遗传搜索
该算法流程包括:
- 初始化种群:从预训练配置中采样
- 渲染验证集:生成多种样式图像
- 评估性能:测试准确率和压缩比
- LLM分析:提出优化建议
- 迭代进化:直到性能收敛
这种方法比人工调参效率高10倍以上。
5.3 训练策略与性能表现
Glyph采用三阶段训练:
- 持续预训练:文本渲染理解基础能力
- 监督微调:任务特定适应
- 强化学习:答案质量优化
最终性能表现:
- 预填充速度提升4.8倍
- 解码速度提升4.4倍
- SFT训练速度提升2倍
- 保持原始模型90%以上的准确率
6. 综合对比与未来展望
通过对这四篇论文的深入分析,我们可以总结出视觉Token压缩的三大技术路线:
| 技术路线 | 代表方法 | 压缩比例 | 优势 | 适用场景 |
|---|---|---|---|---|
| 语义感知合并 | LLaVA-Scissor | 3%-35% | 保留完整语义 | 视频理解 |
| 编码器优化 | FastVLM | 50%-75% | 源头减少Token | 高分辨率图像 |
| 查询引导压缩 | QG-VTC/Glyph | 75%-90% | 任务自适应 | VQA/长文本 |
未来发展方向可能包括:
- 多方法融合:结合不同压缩策略的优势
- 动态压缩:根据内容复杂度自适应调整
- 硬件协同:专有加速器设计
- 多模态统一:跨模态共享压缩策略
在实际应用中,建议根据具体需求选择合适的压缩方法。对于通用场景,FastVLM的架构优化是不错的选择;而对任务特定场景,QG-VTC的问题引导压缩可能更有效。无论如何,Token压缩技术将继续在多模态模型的高效部署中发挥关键作用。