
1. Make Sense.ai 标注工具入门指南
作为一名计算机视觉工程师,我深知数据标注是模型训练中最耗时却又最关键的环节。传统标注工具如LabelImg虽然功能完善,但配置复杂、依赖环境多。直到发现Make Sense.ai这个在线标注工具,我的工作效率直接提升了三倍。这个基于浏览器的工具无需安装任何软件,打开网页就能直接使用,特别适合快速标注和小型项目。
Make Sense.ai支持物体检测(Object Detection)、图像分类(Image Classification)和关键点检测(Keypoint Detection)三种主流标注任务。我最近用它在15分钟内完成了200张商品图片的标注,而同样的工作量在其他工具上至少要花1小时。最让我惊喜的是它原生支持YOLO格式,标注完直接导出就能用于训练,省去了格式转换的麻烦。
提示:虽然界面默认是英文,但用浏览器翻译插件(如Google翻译)可以一键转为中文,对英语不好的用户特别友好。
2. 完整标注流程详解
2.1 准备工作与环境设置
首先在浏览器地址栏输入 https://www.makesense.ai 进入官网。建议使用Chrome或Edge等现代浏览器,我在Firefox上遇到过偶尔卡顿的情况。页面加载完成后,你会看到一个非常简洁的界面:
如果英语界面让你感到不适,推荐安装"沉浸式翻译"这类浏览器插件。以Edge浏览器为例:
- 点击右上角扩展图标
- 搜索"Translator"安装微软官方翻译插件
- 在Make Sense.ai页面右键选择"翻译为中文"
2.2 数据导入与项目创建
准备好你的图片数据集,建议将图片放在同一个文件夹内。我习惯按"项目名称_images"的格式命名文件夹,比如"product_detection_images"。点击"开始"按钮后,直接将整个文件夹拖入标注区域:
选择任务类型时需要注意:
- 物体检测:需要框选物体并标注类别(如YOLO、COCO格式)
- 图像分类:为整张图片打标签(如猫、狗分类)
- 关键点检测:标注特定点位置(如人脸关键点)
我们以最常用的"物体检测"为例继续说明。
2.3 标签创建与管理
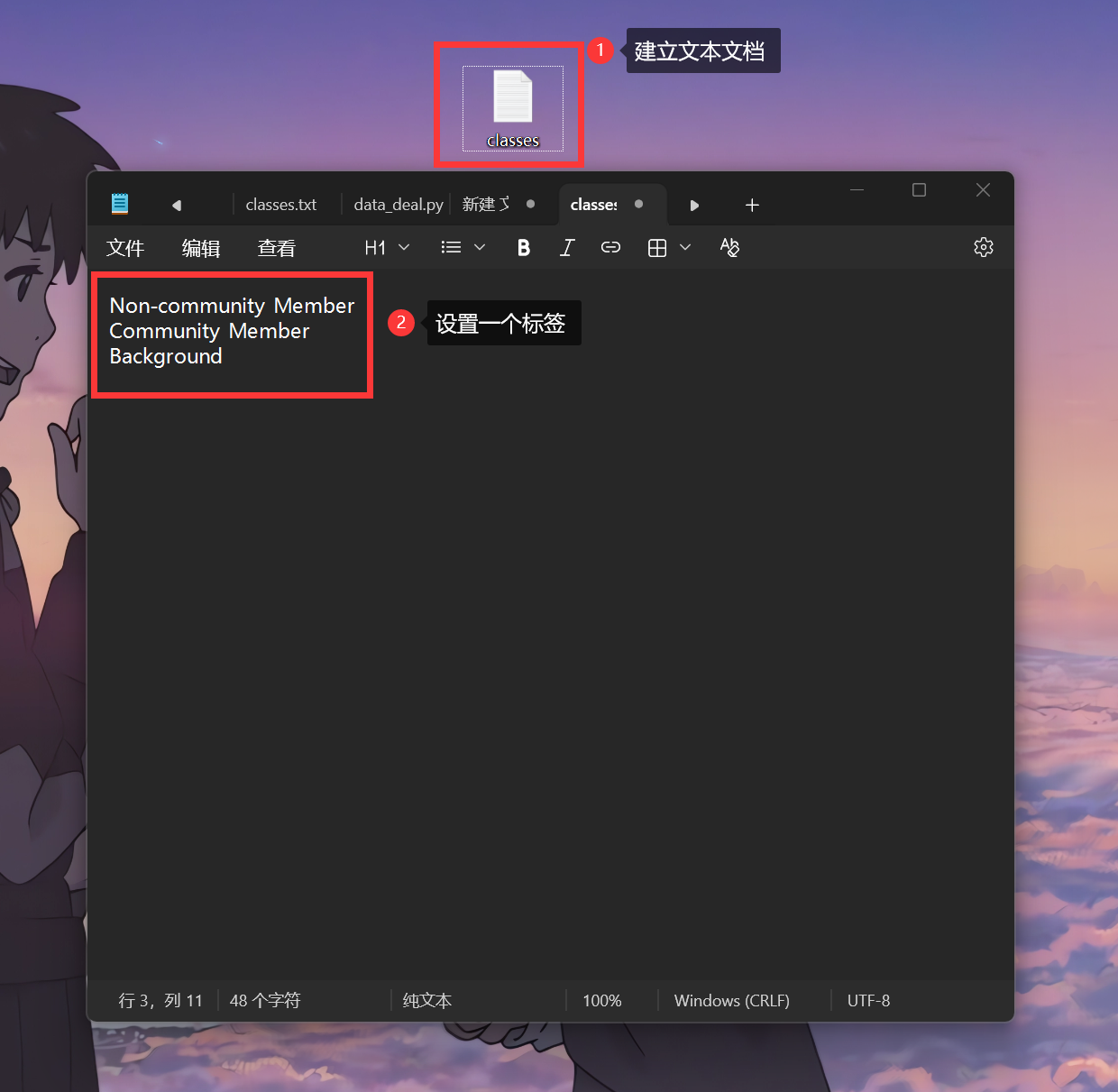
在项目根目录下新建一个名为"classes.txt"的文本文件,这是YOLO系列模型的标准标签格式。每个类别独占一行,且必须使用英文命名。例如一个商品检测项目的标签文件可能是这样的:
code复制apple
banana
orange
watermelon
重要:标签名称不要包含空格或特殊字符,否则可能导致训练出错。我曾因为用了中文标签浪费了半天时间排查问题。
创建好标签文件后,点击"从文件加载标签"按钮导入:
3. 高效标注技巧与最佳实践
3.1 精准标注操作指南
进入标注界面后,你会看到左侧是图片列表,中间是标注区域,右侧是标签选择区。标注一个物体的标准流程是:
- 点击左侧"创建矩形框"工具(或按快捷键"R")
- 在物体周围拖动鼠标创建边界框
- 在右侧选择对应的标签
- 按Enter确认标注
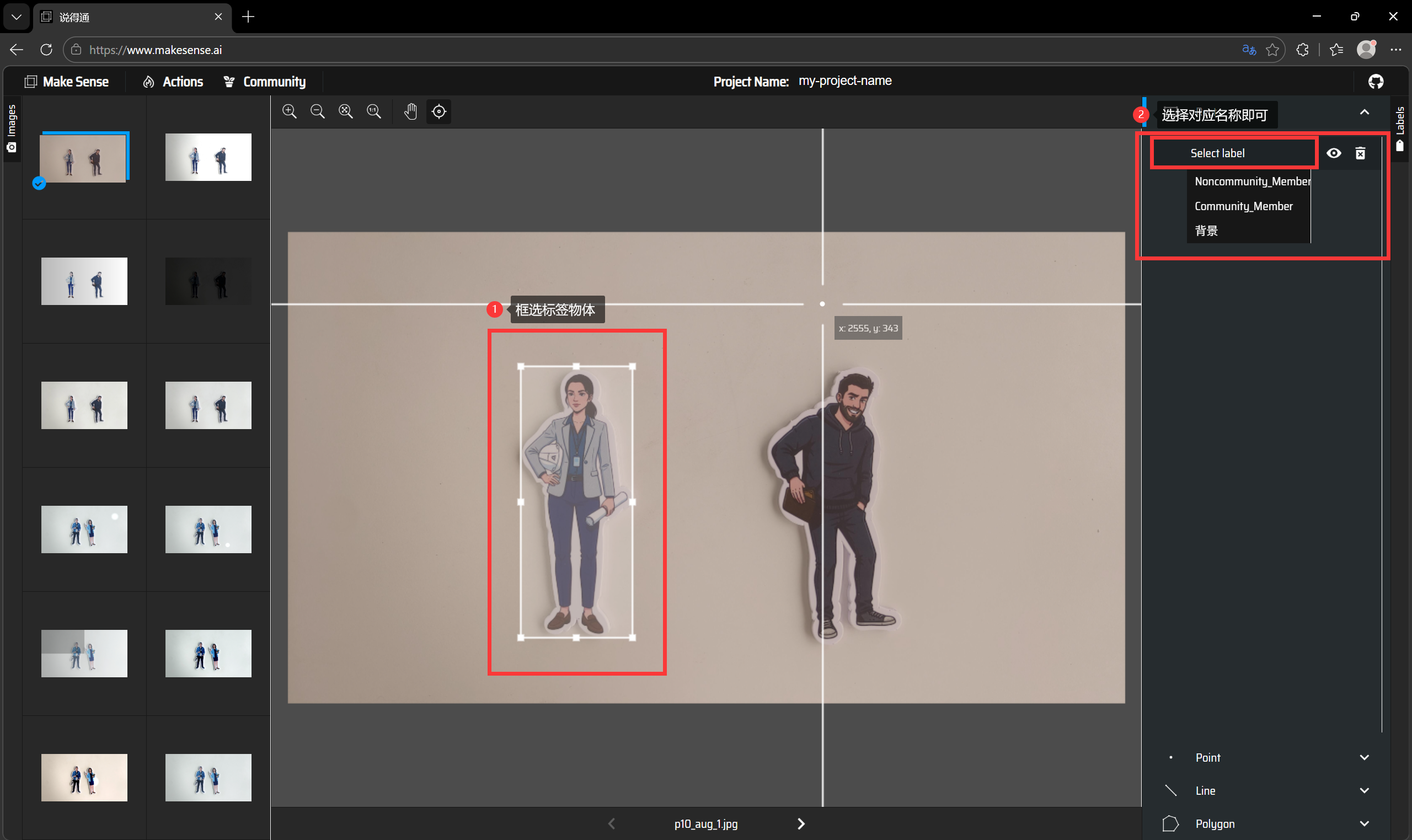
标注时要注意几个关键点:
- 边界框要尽可能贴合物体边缘,但不要包含背景
- 对于被遮挡的物体,按实际可见部分标注
- 同类物体在不同图片中的标注标准要保持一致
- 模糊不清或无法辨认的物体不要标注
3.2 快捷键与效率技巧
熟练使用快捷键可以大幅提升标注速度:
- 空格键:切换下一张图片
- Ctrl+Z:撤销上一步操作
- Delete:删除选中标注框
- 方向键:微调标注框位置
我常用的高效工作流是:
- 先用较快速度完成所有图片的初轮标注
- 第二遍检查时精细调整边界框
- 最后统一复查标签准确性
4. 数据导出与后续处理
4.1 导出标注结果
完成所有标注后,点击右上角的"导出标注"按钮。对于YOLO格式,选择"YOLO"选项卡:
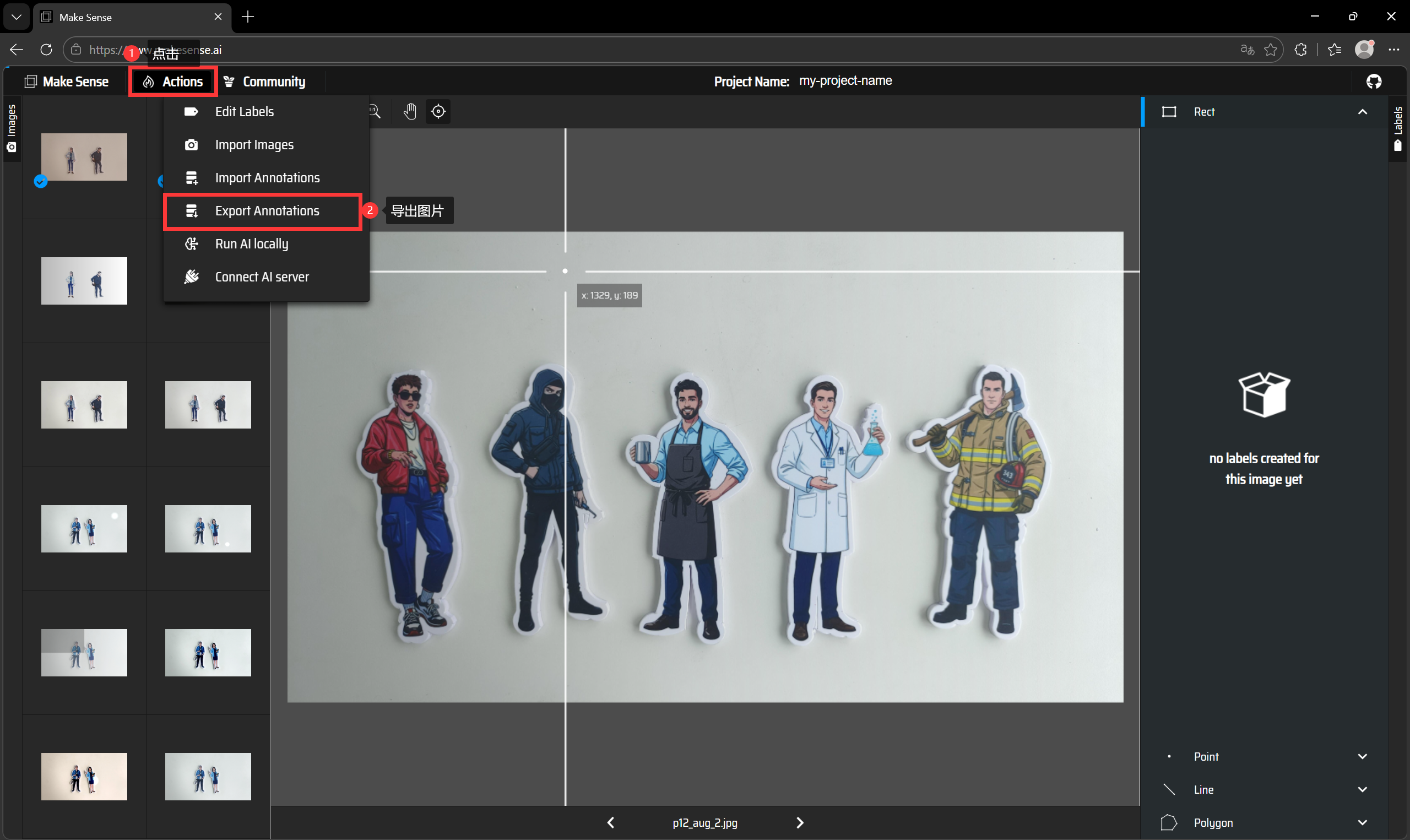
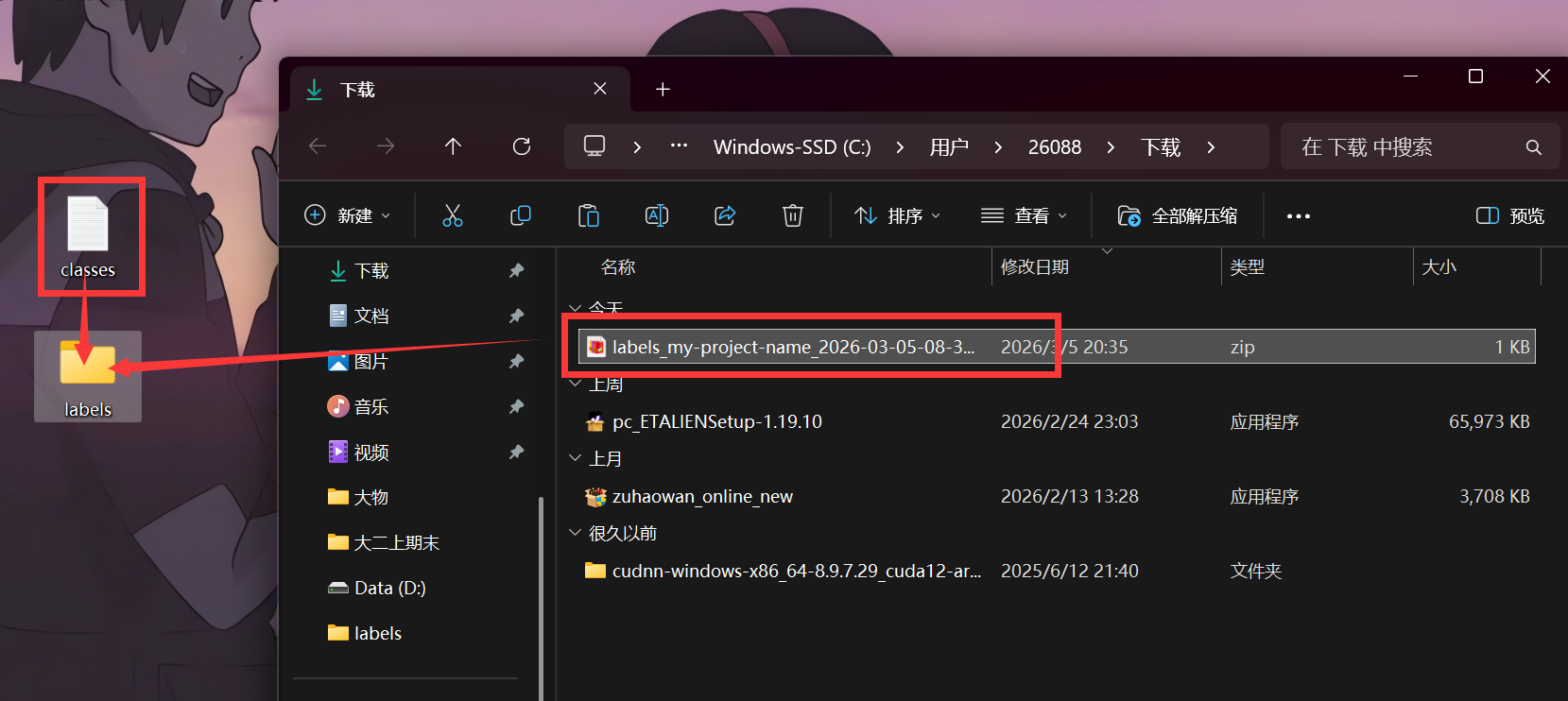
系统会生成一个包含所有标注信息的压缩包。这里有个血的教训:千万不要直接在桌面解压!建议先创建一个专门的文件夹(如"project_labels"),然后把压缩包和之前的classes.txt一起放进去再解压:
4.2 数据结构整理
规范的YOLO数据集目录结构应该是:
code复制dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
我推荐使用这个Python脚本自动整理结构:
python复制import os
import zipfile
from sklearn.model_selection import train_test_split
# 解压标注文件
with zipfile.ZipFile('labels.zip', 'r') as zip_ref:
zip_ref.extractall('labels')
# 创建标准目录
os.makedirs('dataset/images/train', exist_ok=True)
os.makedirs('dataset/images/val', exist_ok=True)
os.makedirs('dataset/labels/train', exist_ok=True)
os.makedirs('dataset/labels/val', exist_ok=True)
# 分割训练集和验证集
image_files = [f for f in os.listdir('images') if f.endswith('.jpg')]
train_files, val_files = train_test_split(image_files, test_size=0.2)
# 移动文件到对应目录
for file in train_files:
os.rename(f'images/{file}', f'dataset/images/train/{file}')
os.rename(f'labels/{file.replace(".jpg",".txt")}',
f'dataset/labels/train/{file.replace(".jpg",".txt")}')
for file in val_files:
os.rename(f'images/{file}', f'dataset/images/val/{file}')
os.rename(f'labels/{file.replace(".jpg",".txt")}',
f'dataset/labels/val/{file.replace(".jpg",".txt")}')
5. 常见问题与解决方案
5.1 标注过程中的典型问题
问题1:标注框无法精确贴合物体边缘
- 解决方法:放大图片(鼠标滚轮)后再标注,或者使用"调整顶点"工具微调
问题2:误标或漏标
- 预防措施:定期按Ctrl+S保存进度,我设置每标注10张图片就保存一次
问题3:标签类别需要修改
- 操作步骤:直接编辑classes.txt文件,然后重新导入标签
5.2 导出后的数据验证
在将数据投入训练前,建议用这个脚本检查标注是否正确:
python复制import cv2
import os
def visualize_labels(image_path, label_path):
image = cv2.imread(image_path)
h, w = image.shape[:2]
with open(label_path) as f:
for line in f.readlines():
class_id, x_center, y_center, width, height = map(float, line.split())
# 转换YOLO格式为像素坐标
x_center *= w
y_center *= h
width *= w
height *= h
x1 = int(x_center - width/2)
y1 = int(y_center - height/2)
x2 = int(x_center + width/2)
y2 = int(y_center + height/2)
cv2.rectangle(image, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('Preview', image)
cv2.waitKey(0)
# 示例用法
visualize_labels('dataset/images/train/img001.jpg',
'dataset/labels/train/img001.txt')
6. 进阶技巧与经验分享
6.1 团队协作标注方案
如果需要多人协作标注,可以这样操作:
- 将原始图片数据集分成若干子集
- 每位成员标注自己负责的部分
- 使用这个命令合并标注结果:
bash复制find . -name "*.txt" -exec cat {} >> merged_labels.txt \;
6.2 标注质量评估指标
我开发了一套简单的质量评估标准:
- 完整性:所有可见目标都应被标注
- 准确性:边界框与物体边缘的偏差不超过5个像素
- 一致性:同类物体在不同图片中的标注方式相同
可以用这个Python函数自动计算标注覆盖率:
python复制def calculate_coverage(label_folder, image_folder):
label_count = len([f for f in os.listdir(label_folder) if f.endswith('.txt')])
image_count = len([f for f in os.listdir(image_folder) if f.endswith('.jpg')])
return label_count / image_count
# 使用示例
coverage_rate = calculate_coverage('dataset/labels/train', 'dataset/images/train')
print(f'标注覆盖率为: {coverage_rate:.2%}')
在实际项目中,我发现Make Sense.ai特别适合这些场景:
- 快速原型开发阶段的小规模数据标注
- 教育领域的教学演示
- 个人学习和小型研究项目
对于企业级的大规模标注任务,虽然也能用,但可能还是需要更专业的标注平台。不过就免费工具而言,Make Sense.ai已经是我用过的最顺手的一个了。