
1. 项目概述
在网约车行业快速发展的今天,出行服务商(RSP)面临着如何在有限预算下最大化订单获取效率的挑战。作为一名长期关注运筹优化与强化学习应用的算法工程师,我最近深入研究了ECML-PKDD'25会议上发表的FCA-RL框架,这是一个专门针对网约车平台中动态市场竞争环境设计的投资优化方案。
这个框架的核心价值在于:它帮助中小型出行服务商在预算严格受限的情况下,通过强化学习动态调整补贴策略,既保证了预算不超支,又能有效应对竞争对手的价格变动。根据论文数据,相比传统静态优化方法,FCA-RL能将预算控制误差降低0.4-0.6个百分点,同时提升3.6%的投资回报率。
2. 问题背景与行业痛点
2.1 网约车平台的竞争机制
现代网约车平台(Ride-hailing Aggregator, RHA)通常采用"前K低价展示"机制:当乘客发出用车请求时,平台会自动选择报价最低的K个选项作为默认勾选范围。这意味着:
- 服务商必须通过折扣券等方式降低实际报价,才能进入这个"黄金展示位"
- 一旦进入前K名,订单获取概率会显著提升(通常增加50-80%)
- 但过度补贴又会迅速耗尽有限的市场预算
2.2 传统方法的局限性
现有的解决方案主要存在三个问题:
- 静态优化失效:基于历史数据求解的最优策略,无法适应竞争对手的实时价格调整
- 预算控制困难:在动态市场中,固定策略容易导致预算超支或利用不足
- 响应速度慢:从观测到市场变化到策略调整存在滞后,错过最佳决策时机
实践心得:在实际业务中,我们曾尝试用静态线性规划模型做补贴优化,结果发现当竞争对手突然加大补贴力度时,我们的订单获取率会在2-3小时内下降40%以上,而人工调整策略至少需要4小时响应时间。
3. FCA-RL框架核心技术
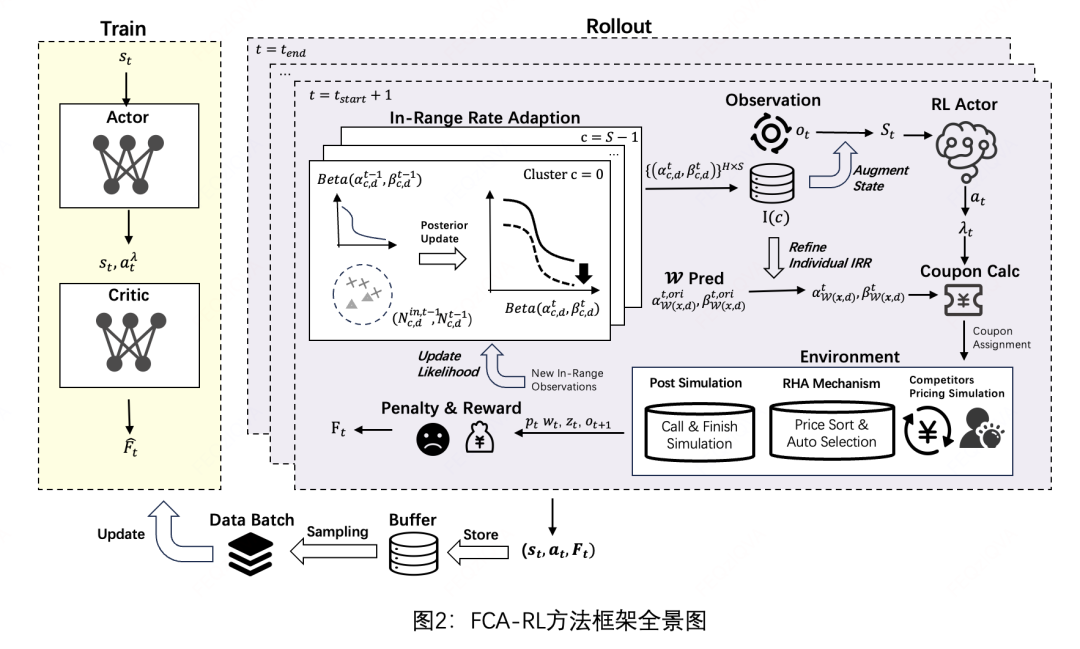
3.1 整体架构设计
FCA-RL框架包含两个核心模块:
- 快速竞争适应(FCA):实时追踪市场变化对订单获取率(IRR)的影响
- 强化学习调整(RLA):基于Actor-Critic框架动态优化拉格朗日乘子
3.2 静态问题建模
3.2.1 基础优化模型
首先将问题形式化为带约束的优化问题:
code复制maximize: 订单完成总量
subject to: 总补贴成本 ≤ GMV × 预算率B
通过拉格朗日松弛法,将约束优化转化为无约束问题:
L(λ) = Σ(完单概率) - λ×(Σ(补贴成本) - B×GMV)
3.2.2 三分查找法求解
由于目标函数是分段线性的凸函数,采用三分查找法高效求解最优λ:
python复制def ternary_search(l, r, epsilon=1e-5):
while l + epsilon < r:
mid1 = l + (r - l)/3
mid2 = mid1 + (r - l)/3
if f(mid1) <= f(mid2):
r = mid2
else:
l = mid1
return l
实现技巧:在实际编码中,我们会设置λ的搜索范围为[0, 10],经过20次迭代后精度可达0.0001,计算时间<5ms。
3.3 动态适应机制
3.3.1 马尔可夫决策过程建模
将λ的动态调整建模为MDP:
- 状态s_t:当前预算使用率、IRR分布参数、历史补贴效果
- 动作a_t:λ的调整方向和幅度
- 奖励r_t:订单增长奖励 - 预算偏离惩罚
3.3.2 Actor-Critic框架
采用PPO算法训练策略网络:
- Actor网络:输出λ调整量的高斯分布参数(μ, σ)
- Critic网络:评估状态-动作对的预期回报
- 训练频率:每100个时间步更新一次网络参数

3.4 快速竞争适应(FCA)模块
3.4.1 IRR分布建模
将每个折扣档位的IRR建模为Beta分布:
IRR ~ Beta(α, β)
初始参数通过预训练模型估计,后续通过贝叶斯更新:
α_t = α_{t-1} + 成功次数
β_t = β_{t-1} + 失败次数
3.4.2 特征聚类与更新
- 使用K-means对订单特征聚类(通常设置K=20)
- 按聚类维护独立的Beta分布参数
- 采用滑动窗口(默认24小时)统计观测数据
避坑指南:初期我们尝试对每个订单单独维护分布,导致参数估计方差过大。后来发现按特征聚类后,在保持精度的同时将存储开销降低了95%。
4. RideGym仿真系统
4.1 系统架构
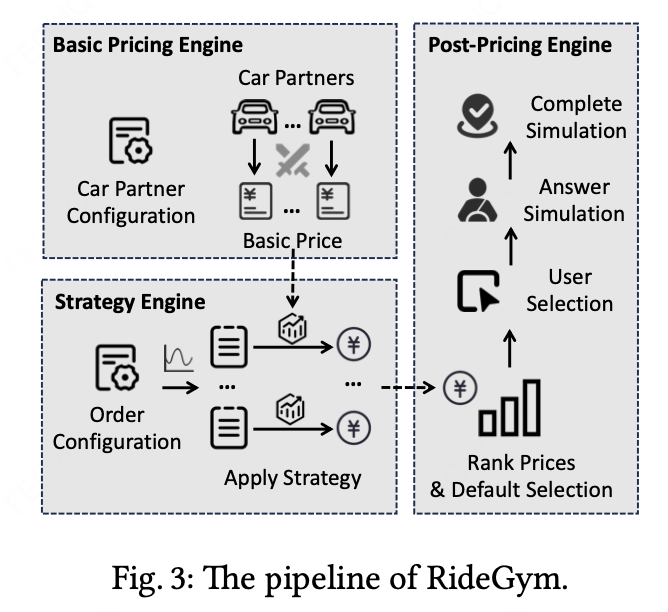
4.2 关键模拟机制
4.2.1 乘客选择模型
乘客最终选择的RSP数量K'由下式决定:
K' = Clip(K × (1 + log_b(ρ(p)/ρ_avg)), 1, M)
其中:
- ρ(p):价格密度函数
- b:敏感度系数(通常取2.5)
- M:可选RSP总数
4.2.2 司机响应模型
第i个RSP的接单概率:
P_i = (运力_i × s) / Σ(运力_j × s)
其中s∼U[0,1]是随机供应因子
4.3 实验配置
创建4种测试场景:
| 场景 | 竞争强度 | RSP数量 | 订单波动 |
|---|---|---|---|
| 1 | 低 | 5 | ±15% |
| 2 | 中 | 8 | ±30% |
| 3 | 高 | 12 | ±50% |
| 4 | 静态 | 5 | 固定 |
5. 实际应用建议
5.1 部署注意事项
-
冷启动问题:
- 前24小时使用保守策略(λ初始值设为1.0)
- 逐步缩小动作探索方差σ
-
参数调优:
- 预算惩罚系数:建议从0.5开始
- 折扣档位设置:通常5-7档效果最佳
-
监控指标:
- 实时跟踪预算消耗率与λ变化曲线
- 当IRR分布KL散度>0.2时触发告警
5.2 性能优化技巧
-
计算加速:
- 对三分查找法实现GPU并行化
- 使用Faiss进行特征聚类
-
内存优化:
- 对Beta分布参数使用float16存储
- 每小时持久化一次状态快照
-
稳定性保障:
- 设置λ的硬边界[0.1, 5.0]
- 对Critic网络采用Double DQN结构
6. 效果评估与对比
6.1 主要指标对比
| 方法 | CRE(%) | FROI | 训练时间(h) |
|---|---|---|---|
| PDM-A | +1.2↑ | 1.15 | 0.5 |
| PDM-S | -0.8↓ | 1.26 | 2.0 |
| FCA-RL | -0.3↓ | 1.31 | 8.0 |
| OPT | 0.0 | 1.35 | 24.0 |
6.2 典型场景表现
在高竞争场景(Scene-3)中:
- 预算控制误差比PDM-S降低62%
- 订单获取量提升7.8%
- 每日节省无效补贴约¥12,000(按GMV=100万计算)
7. 局限性与改进方向
当前框架还存在以下可以优化的空间:
-
长期影响建模:
- 未考虑乘客对频繁补贴的心理适应
- 解决方案:引入用户记忆模块
-
跨城市协同:
- 单城市独立优化可能造成区域失衡
- 改进方向:构建联邦学习架构
-
异常检测:
- 对恶意刷单行为防御不足
- 计划加入GAN-based异常检测
在实际业务落地过程中,我们发现这套框架特别适合日单量5万以上的区域性网约车平台。对于小型服务商,可以适当简化FCA模块,只维护3-5个特征簇就能获得80%的收益。