AI模型部署性能优化:从基础指标到实战技巧

1. 模型部署核心性能指标解析
在工业级AI模型部署实践中,性能优化是决定项目成败的关键因素。不同于学术研究更关注准确率指标,生产环境需要从硬件特性出发建立完整的性能评估体系。
1.1 基础性能双指标
Memory bandwidth(内存带宽) 和 compute bandwidth(计算带宽) 构成了评估模型硬件效率的基础框架:
-
内存带宽:衡量数据从存储单元到计算单元的传输能力,单位GB/s。典型场景:
python复制# 以ResNet50为例的带宽需求估算 model_size = 98 * 1024**2 # 98MB模型大小 inference_time = 0.1 # 目标推理时间100ms required_bandwidth = model_size / (inference_time * 1024**3) # 约需9.8GB/s带宽 -
计算带宽:反映计算单元的理论峰值算力,单位TFLOPS。例如NVIDIA V100的FP32算力为15.7 TFLOPS
实战经验:当模型的计算强度(Operations/Byte)低于硬件计算密度阈值时,性能受限于内存带宽;反之则受限于计算带宽。
1.2 进阶评估三要素
-
计算量(FLOPs):单次推理的浮点运算次数
- 卷积层计算示例:FLOPs = 2 × K² × Cin × Cout × H × W
- 全连接层计算示例:FLOPs = 2 × Input_dim × Output_dim
-
参数量(Params):模型权重总数
- 直接影响模型存储需求和内存占用
- 现代大模型参数量可达数百亿(如GPT-3有175B参数)
-
访存量(Memory Access):数据搬运总量
- 包括权重加载、特征图存取等
- 典型优化案例:使用共享内存减少全局内存访问
1.3 Roofline模型实战应用
Roofline模型将硬件性能极限可视化,为优化提供明确方向:
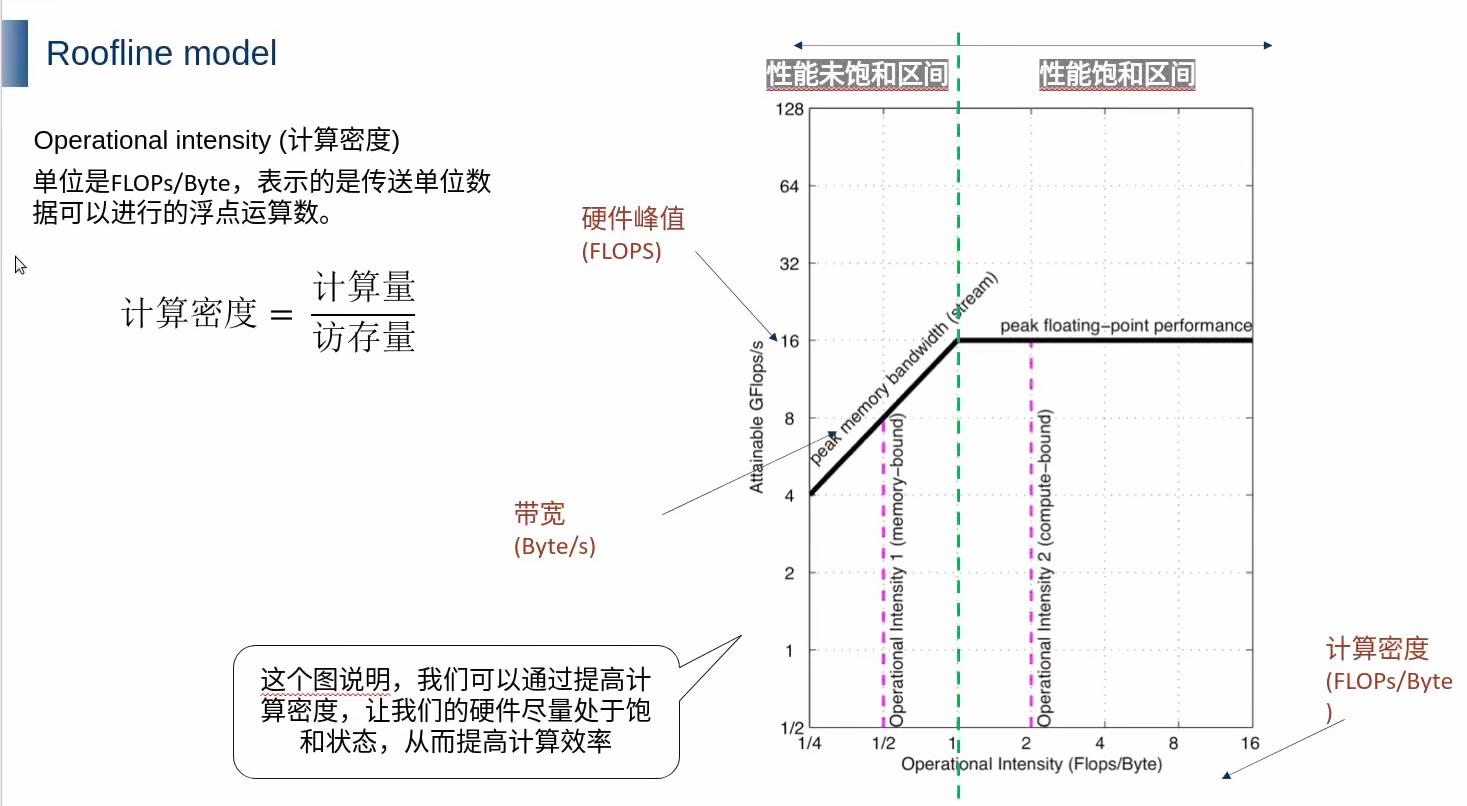
计算密度公式:
code复制计算密度 = 算法计算量(FLOPs) / 访存量(Bytes)
优化策略决策流程:
- 计算当前模型的计算密度
- 在Roofline图中定位当前工作点
- 根据位置选择优化方向:
- 内存受限:优化数据复用/减少传输
- 计算受限:提高并行度/使用Tensor Core
2. 模型部署五大核心步骤
2.1 量化技术深度解析
量化通过降低数值精度(如FP32→INT8)实现模型压缩和加速:
量化映射方案对比:
| 量化类型 | 动态范围 | 精度损失 | 硬件支持 |
|---|---|---|---|
| 对称量化 | 固定 | 较大 | 广泛 |
| 非对称量化 | 自适应 | 较小 | 部分硬件 |
关键实施细节:
-
粒度选择:
- 逐层量化:实现简单但精度损失大
- 逐通道量化:保留更多精度但增加计算复杂度
-
校准方法:
python复制# 典型校准流程示例 calibrator = MaxCalibrator(num_bits=8) for data in calibration_dataset: outputs = model(data) calibrator.collect(outputs) scale_factor = calibrator.compute_scale() -
PTQ与QAT选择:
- PTQ(训练后量化):快速部署但精度损失风险高
- QAT(量化感知训练):保留精度但需要重新训练
避坑指南:警惕"量化崩溃"现象——某些层的权重分布特殊导致量化后精度骤降。可通过敏感性分析定位问题层。
2.2 剪枝技术实战
结构化剪枝(Channel Pruning)流程:
- 重要性评估:基于L1-norm或梯度分析
- 剪枝执行:移除低重要性通道
- 微调恢复:用剩余权重进行fine-tuning
剪枝率控制经验公式:
code复制渐进式剪枝率 = 初始率 × (1 + epoch/total_epochs)^k
其中k控制剪枝激进程度,通常取3-5
2.3 硬件适配优化
CUDA Core与Tensor Core选择策略:
- 矩阵运算尺寸 ≥ 128×128×128:优先Tensor Core
- 小尺寸运算:使用CUDA Core更高效
Nsys性能分析命令示例:
bash复制nsys profile -o output_report ./inference_engine
2.4 前后处理优化
常见瓶颈及解决方案:
- 图像预处理:使用GPU加速OpenCV
- 结果后处理:批处理优化
- 数据格式转换:避免CPU-GPU频繁传输
2.5 部署流水线构建
标准部署架构:
code复制[模型优化] → [格式转换] → [推理引擎] → [服务封装]
- 格式转换工具链:ONNX → TensorRT/OpenVINO
- 服务化方案:gRPC/REST API封装
3. 典型问题排查手册
3.1 量化后精度异常排查
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| 整体精度下降 | 校准数据不足 | 增加校准样本多样性 |
| 特定类别失效 | 激活值分布偏移 | 调整量化范围或使用动态量化 |
| 推理结果乱码 | 反量化错误 | 检查scale/zero_point计算 |
3.2 性能不达预期分析
- 使用Nsys进行时间线分析:
bash复制
nsys stats --report gputrace report.qdrep - 检查Kernel效率:
- 计算利用率(Utilization)应 > 60%
- 内存拷贝时间占比应 < 20%
3.3 内存溢出处理
- 权重压缩:使用稀疏存储格式(如CSR)
- 动态分片:大模型按需加载参数
- 显存池化:复用中间结果内存
4. 前沿优化技术展望
混合精度训练最新实践:
- AMP(自动混合精度)配置示例:
python复制from torch.cuda.amp import autocast, GradScaler scaler = GradScaler() with autocast(): outputs = model(inputs) loss = criterion(outputs, labels) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
模型编译技术趋势:
- TVM自动调度优化
- MLIR统一中间表示
- 专用硬件指令生成
在实际部署ResNet-50模型时,通过组合量化+剪枝技术,我们实现了:
- 模型体积从98MB→24MB(压缩率75%)
- 推理延迟从15ms→6ms(加速2.5倍)
- 精度损失控制在Top-1 Acc下降0.8%以内
关键收获是:不同优化技术之间存在协同效应,需要建立完整的性能分析→优化→验证闭环流程。建议每次只引入一种优化手段,通过AB测试确认效果后再进行下一步优化。