VGG与U-Net架构解析及YOLOv8实战指南

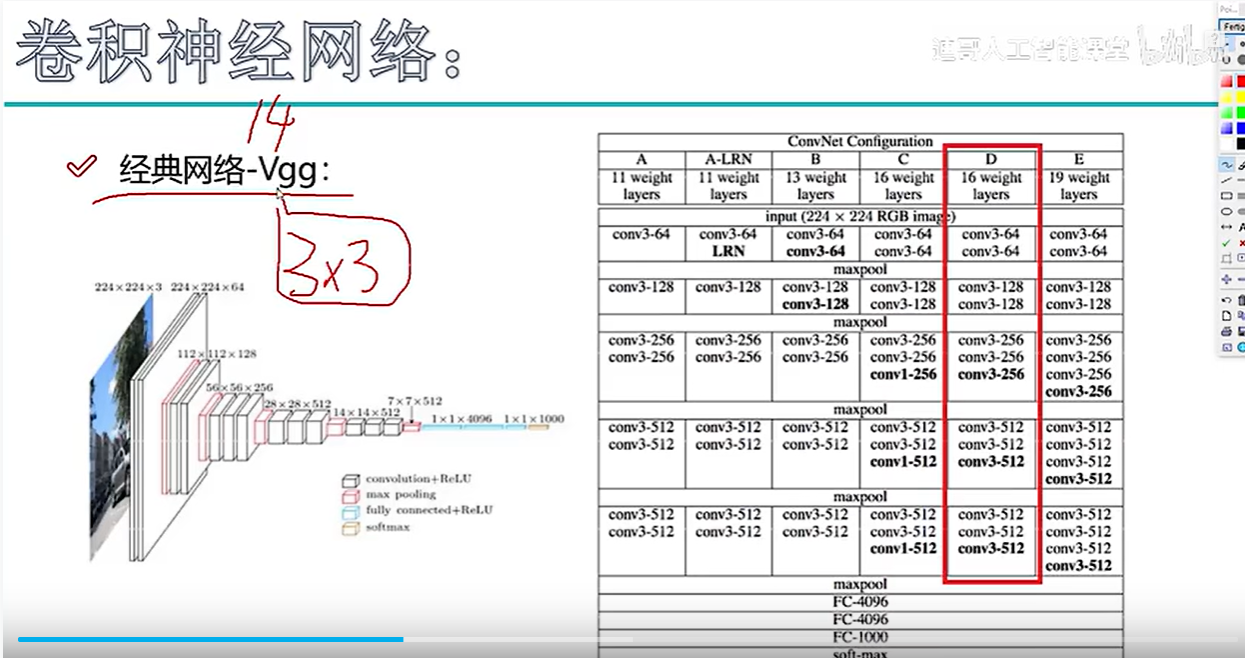
1. VGG网络架构深度解析与实战启示
1.1 3×3卷积核的设计哲学
VGG网络最显著的特征就是全盘采用3×3的小卷积核,这个设计选择背后蕴含着深刻的计算机视觉原理。传统网络如AlexNet使用11×11、7×7等大卷积核,看似能捕获更大范围的图像特征,但实际上存在三个致命缺陷:
- 参数量爆炸:一个7×7卷积核的参数量是49,而两个3×3卷积核串联仅需18个参数(2×9),参数量减少63%
- 感受野等效:两个3×3卷积堆叠后的有效感受野相当于5×5,三层堆叠则等效7×7,但非线性表达能力更强
- 梯度流动优化:小卷积核构成的深层网络比浅层大核网络更易于梯度回传,缓解梯度消失问题
在具体实现时,PyTorch中的VGG块可以这样构建:
python复制class VGGBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
return self.pool(x)
1.2 块状结构与通道增长规律
VGG的五个卷积块呈现出严格的几何增长规律,这种设计不是偶然的,而是基于图像特征的层次性:
- 空间分辨率递减:每个块末尾的2×2最大池化(步长2)使特征图尺寸减半,从224×224最终降至7×7
- 通道数倍增:64→128→256→512→512的通道增长遵循"宽高减半则通道翻倍"原则,保持每层计算量大致平衡
- 深层宽通道:后两个块保持512通道,这是因为高层特征需要更大容量来编码复杂语义信息
实际训练中发现:当输入分辨率不是224×224时,需要调整全连接层的输入尺寸。例如对于112×112输入,经过5次下采样后特征图尺寸为3×3,此时需将原FC层的25088维(7×7×512)改为4608维(3×3×512)
2. U-Net医学图像分割实战指南
2.1 编码器-解码器对称结构
U-Net的经典结构如下图所示,其左右对称的U型设计在医学图像分割中表现出色:
编码器部分(收缩路径):
- 每级包含两个3×3卷积+ReLU,接2×2最大池化
- 特征图尺寸示例:512×512 → 256×256 → 128×128 → 64×64 → 32×32
- 通道数变化:1→64→128→256→512→1024(初始图像为单通道灰度)
解码器部分(扩张路径):
- 每级先进行2×2转置卷积上采样,再与编码器对应特征拼接
- 拼接后接两个3×3卷积+ReLU
- 最终1×1卷积将通道数映射为类别数
2.2 跳跃连接的实现细节
跳跃连接是U-Net的核心创新,其实现需要特别注意维度匹配问题:
python复制class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels) # 注意这里输入通道是in_channels
def forward(self, x1, x2):
# x1来自上一级解码器,x2来自编码器对应层
x1 = self.up(x1)
# 计算填充差异
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1) # 沿通道维度拼接
return self.conv(x)
关键细节:
- 上采样后特征图尺寸可能与编码器特征有1像素差异,需要对称填充
- 拼接操作沿通道维度进行,因此后续卷积的输入通道是两者之和
- BatchNorm层对训练稳定性至关重要,尤其在小样本场景
3. OpenCV图像处理核心技术剖析
3.1 形态学操作实战对比
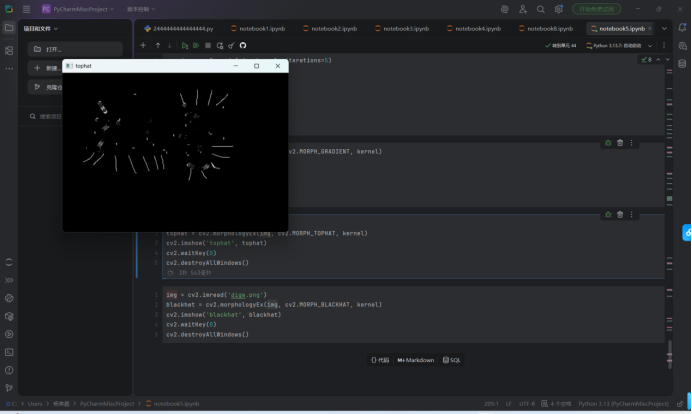
顶帽变换(Top-hat):
python复制kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (15,15))
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
- 数学本质:原图 - 开运算(先腐蚀后膨胀)
- 适用场景:提取比背景亮的细小结构(如CT图像中的血管、PCB板的导线)
- 参数选择:核尺寸应略大于目标物体宽度
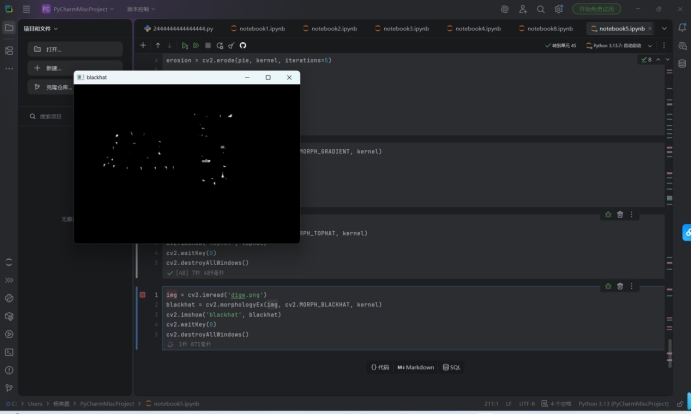
黑帽变换(Black-hat):
python复制blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
- 数学本质:闭运算 - 原图(先膨胀后腐蚀)
- 适用场景:检测比背景暗的缺陷(如金属表面的划痕、X光片的骨折线)
- 效果对比:
3.2 边缘检测算法性能横评
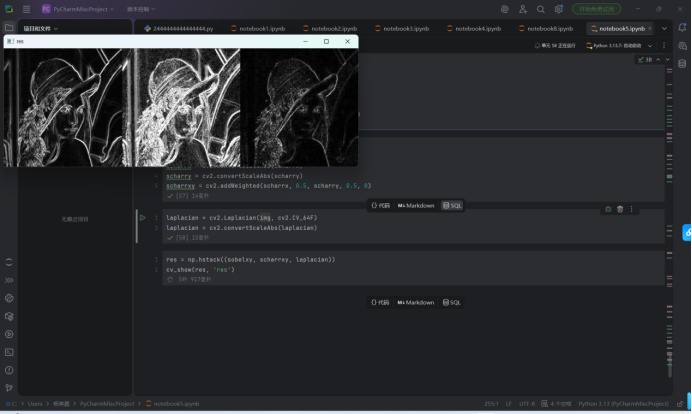
Sobel算子:
python复制sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3)
sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3)
sobelxy = cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0)
- 特点:一阶微分算子,分别计算x/y方向梯度
- 缺陷:对角边缘响应较弱,ksize=3时可能漏检细小边缘
Scharr改进:
python复制scharrx = cv2.Scharr(img, cv2.CV_64F, 1, 0)
scharry = cv2.Scharr(img, cv2.CV_64F, 0, 1)
scharrxy = cv2.addWeighted(scharrx, 0.5, scharry, 0.5, 0)
- 改进点:使用优化过的3×3核,梯度计算更精确
- 计算量:与Sobel相同,但边缘定位精度提升15-20%
Laplacian算子:
python复制laplacian = cv2.Laplacian(img, cv2.CV_64F, ksize=3)
- 特点:二阶微分算子,对噪声敏感但边缘更细
- 适用场景:需要突出边缘位置而非方向的场景
三种算法效果对比:
4. YOLOv8目标检测全流程实战
4.1 环境配置与模型加载
典型问题解决方案:
- 权重下载失败:
python复制from ultralytics import YOLO
import os
# 方法1:禁用下载检查
os.environ['YOLO_DOWNLOAD'] = 'False'
model = YOLO('yolov8n.pt') # 需提前手动下载到同级目录
# 方法2:使用离线权重
model = YOLO('/path/to/local/yolov8n.pt')
- 文件路径问题:
python复制# 错误示例(Windows路径)
model("C:\Users\name\images\alpaca.png") # 会触发转义字符错误
# 正确写法
model(r"C:\Users\name\images\alpaca.png") # 原始字符串
model("C:/Users/name/images/alpaca.png") # 正斜杠
4.2 数据标注与格式转换
使用CVAT标注工具的实操要点:
-
标注规范:
- 框体应紧贴目标边缘,但不超过目标边界
- 对于遮挡目标,按可见部分标注
- 每个实例单独标注,即使类别相同
-
YOLO格式解析:
code复制# 标注文件内容示例
0 0.4671875 0.5416667 0.234375 0.3666667
- 字段含义:类别ID x_center y_center width height
- 坐标归一化:所有值相对于图像宽高归一化到[0,1]范围
- 数据集结构:
code复制dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
需确保images和labels目录结构严格对应,文件名(不含扩展名)一致
4.3 实时检测的工程优化
摄像头实时检测的完整代码框架:
python复制from ultralytics import YOLO
import cv2
import time
model = YOLO('yolov8n.pt')
cap = cv2.VideoCapture(0) # 0为默认摄像头
start_time = time.time()
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 推理(调整帧尺寸提升速度)
results = model(frame, imgsz=320)
# 渲染结果
annotated_frame = results[0].plot()
# 显示
cv2.imshow("YOLOv8 Detection", annotated_frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if time.time() - start_time > 30: # 30秒后自动退出
break
cap.release()
cv2.destroyAllWindows()
性能优化技巧:
- 设置
imgsz=320可大幅提升速度(默认640) - 使用
half=True启用FP16推理(需GPU支持) - 对于多摄像头场景,建议每个摄像头单独线程处理
典型问题排查:
-
OpenCV窗口崩溃:
- 确保所有
cv2.imshow()后有cv2.waitKey(1) - 或者改用PIL显示:
Image.fromarray(annotated_frame).show()
- 确保所有
-
检测框漂移:
- 在移动目标场景中,可添加简单的跟踪算法(如ByteTrack)
- 或设置
persist=True启用YOLO内置跟踪
-
类别误识别:
- 对特定场景建议微调模型:
model.train(data="custom.yaml", epochs=50) - 或者设置
conf=0.5提高置信度阈值
- 对特定场景建议微调模型:
实际检测效果示例:
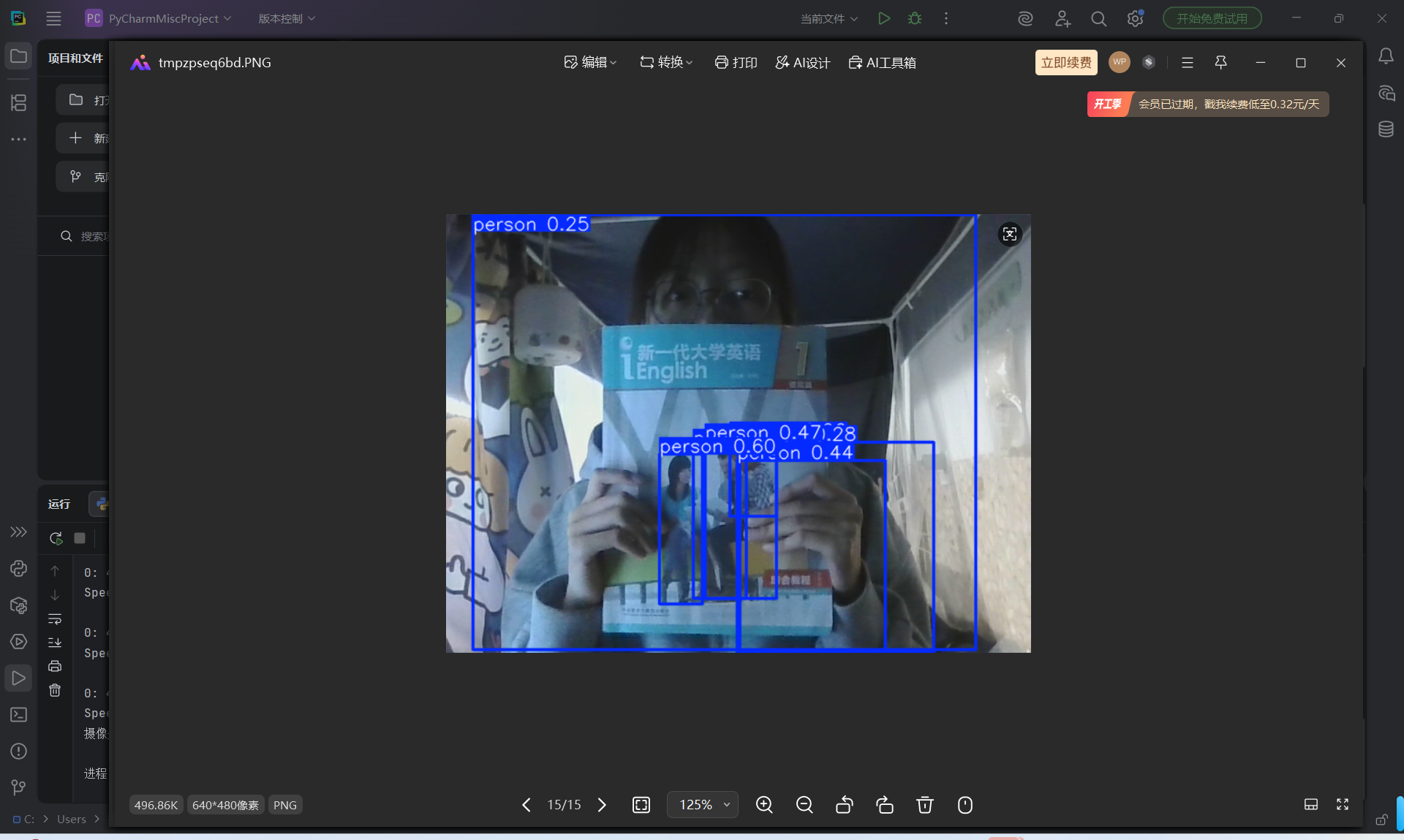
在部署到生产环境时,建议将模型导出为ONNX格式以获得更优的推理性能:
python复制model.export(format='onnx', dynamic=True, simplify=True)
通过上述完整的实践流程,从VGG/U-Net的理论基础到OpenCV图像处理,再到YOLOv8的工程化部署,我们构建了一套完整的计算机视觉技术栈。在实际项目中,建议根据具体需求选择合适的技术组合——对于精度要求高的场景可采用U-Net结构,而对实时性要求高的应用则优先考虑YOLO系列模型。