深度学习环境配置:PyTorch与CUDA版本兼容性全解析

1. 深度学习开发环境的核心组件解析
作为2016年就开始在深度学习领域摸爬滚打的老兵,我见证了无数新手在环境配置上栽跟头。最近在技术社区答疑时,发现PyTorch和CUDA的版本匹配问题依然是高频痛点。这张NVIDIA显卡驱动、CUDA Toolkit和cuDNN的版本关系图(见下图),正是许多开发者容易忽视的关键参考。
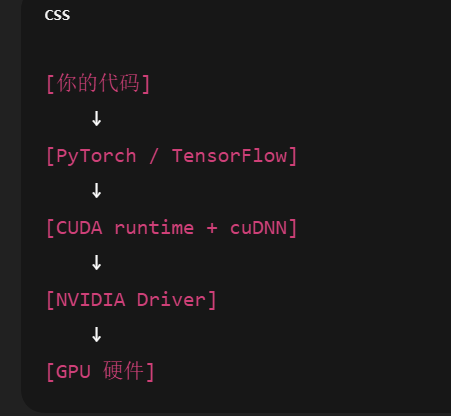
1.1 PyTorch的本质与定位
PyTorch本质上是一个开源的机器学习框架,它的核心价值在于提供了两大能力:
- 动态计算图:区别于TensorFlow早期的静态图,PyTorch的即时执行模式让调试像写Python一样直观
- GPU加速计算:通过CUDA接口将张量运算卸载到NVIDIA显卡,这也是版本兼容问题的根源
我在实际项目中最常使用的torch.Tensor对象,当调用.cuda()方法时,就会触发CUDA的并行计算机制。这个简单的操作背后,是PyTorch的CUDA扩展模块在起作用。
1.2 CUDA的技术栈地位
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台,它包含:
- 硬件层:GPU上的流处理器(Streaming Multiprocessors)
- 软件层:CUDA指令集架构(ISA)和并行计算引擎
- 工具链:nvcc编译器、性能分析工具等
当我们在Python中执行import torch时,PyTorch会通过libcudart.so动态库与CUDA运行时API交互。这个加载过程如果出现版本不匹配,就会报出经典的CUDA runtime error。
2. 版本兼容性深度剖析
2.1 版本依赖的三层结构
从底层到上层的依赖关系就像盖房子:
- 地基层:NVIDIA显卡驱动(如470.103.01)
- 框架层:CUDA Toolkit(如11.3)
- 工具层:cuDNN(如8.2.0)
- 应用层:PyTorch(如1.12.1)
这张版本对应表(见下图)就是开发者的"施工图纸",我曾经因为忽略它导致整个项目组卡在环境配置上三天。

2.2 典型版本冲突场景
去年在部署一个目标检测项目时,我遇到了经典的版本陷阱:
- 服务器预装驱动版本:450.80.02
- 项目要求CUDA 11.1 → 需要驱动≥455.23
- 强行安装后出现
CUDA driver version is insufficient错误
解决方案是:
bash复制# 查看当前驱动版本
nvidia-smi --query-gpu=driver_version --format=csv
# 升级驱动(Ubuntu示例)
sudo apt-get install nvidia-driver-460
2.3 版本选择决策树
根据我的踩坑经验,版本选择应该遵循以下流程:
- 确认显卡型号和支持的最高CUDA版本(通过
nvidia-smi -L) - 根据项目需求确定PyTorch版本
- 查阅PyTorch官网的版本对应表
- 安装匹配的CUDA Toolkit
- 配置对应的cuDNN
重要提示:生产环境建议使用Docker镜像或conda环境隔离,避免影响系统级CUDA
3. 环境配置实战指南
3.1 官方推荐安装方式
PyTorch官网提供的安装命令已经考虑了版本兼容性:
bash复制# CUDA 11.3的PyTorch 1.12安装示例
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
但这里有个隐藏坑点:conda默认的下载通道可能包含非官方编译版本。我建议显式指定pytorch官方通道:
bash复制conda install ... -c pytorch -c nvidia
3.2 手动安装CUDA Toolkit
当需要特定CUDA版本时,手动安装更可靠:
- 从NVIDIA开发者网站下载runfile安装包
- 禁用nouveau驱动(Linux系统)
bash复制sudo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nvidia-nouveau.conf" sudo update-initramfs -u - 运行安装程序时注意取消驱动安装选项(如果已单独安装驱动)
3.3 环境验证脚本
部署后建议运行以下验证脚本:
python复制import torch
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"CUDA版本: {torch.version.cuda}")
print(f"cuDNN版本: {torch.backends.cudnn.version()}")
print(f"当前设备: {torch.cuda.get_device_name(0)}")
4. 疑难问题排查手册
4.1 常见错误代码解析
| 错误代码 | 可能原因 | 解决方案 |
|---|---|---|
| CUDA error 35 | 驱动不兼容 | 升级NVIDIA驱动 |
| CUDA error 209 | 设备架构不匹配 | 编译时指定正确的ARCH参数 |
| CUDNN_STATUS_NOT_INITIALIZED | cuDNN版本错误 | 重新安装匹配的cuDNN |
4.2 内存相关故障
在多卡训练时遇到过CUDA out of memory错误,解决方法包括:
- 减小batch size
- 使用梯度累积:
python复制for i, (inputs, labels) in enumerate(data_loader): outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() if (i+1) % 4 == 0: # 每4个batch更新一次 optimizer.step() optimizer.zero_grad() - 启用
torch.cuda.empty_cache()
4.3 版本降级技巧
当需要降级CUDA版本时,务必彻底清理旧版本:
bash复制sudo /usr/local/cuda-X.Y/bin/uninstall_cuda_X.Y.pl
sudo rm -rf /usr/local/cuda-X.Y
然后重新安装目标版本,最后更新环境变量:
bash复制export PATH=/usr/local/cuda-11.3/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH
5. 性能优化实践
5.1 计算设备选择策略
在代码中灵活切换设备可以提升开发效率:
python复制device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
data = data.to(device)
对于多GPU场景,我推荐使用DistributedDataParallel而非简单的DataParallel:
python复制torch.distributed.init_process_group(backend='nccl')
model = torch.nn.parallel.DistributedDataParallel(model)
5.2 混合精度训练配置
通过自动混合精度(AMP)可以显著减少显存占用:
python复制scaler = torch.cuda.amp.GradScaler()
for epoch in epochs:
for inputs, targets in data:
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
5.3 CUDA内核优化技巧
对于自定义算子,正确的线程块配置很关键:
python复制def optimal_block_size(dim):
if dim <= 512: return 256
elif dim <= 1024: return 512
else: return 1024
blocks = (input_size + optimal_block_size(input_size) - 1) // optimal_block_size(input_size)
threads = optimal_block_size(input_size)
6. 开发环境维护建议
6.1 多版本管理方案
我习惯使用conda创建隔离环境:
bash复制conda create -n pytorch1.10 python=3.8
conda activate pytorch1.10
conda install pytorch==1.10.0 cudatoolkit=11.3 -c pytorch
对于需要频繁切换的项目,可以编写环境初始化脚本:
bash复制#!/bin/bash
ENV=$1
case $ENV in
"detection")
conda activate pytorch1.9
export CUDA_HOME=/usr/local/cuda-11.1
;;
"segmentation")
conda activate pytorch1.12
export CUDA_HOME=/usr/local/cuda-11.3
;;
esac
6.2 容器化部署实践
Dockerfile配置示例:
dockerfile复制FROM nvidia/cuda:11.3.1-cudnn8-runtime-ubuntu20.04
RUN apt-get update && apt-get install -y python3-pip
RUN pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
WORKDIR /app
COPY . .
构建时注意指定NVIDIA运行时:
bash复制docker build -t dl-project .
docker run --gpus all -it dl-project
6.3 持续集成配置
在GitLab CI中配置GPU测试的示例:
yaml复制test:
image: nvidia/cuda:11.3.1-cudnn8-runtime
script:
- pip install -r requirements.txt
- python -m pytest tests/
tags:
- nvidia
在Jenkins中需要安装NVIDIA插件并配置:
groovy复制pipeline {
agent {
label 'gpu-node'
}
environment {
CUDA_HOME = '/usr/local/cuda-11.3'
}
stages {
stage('Test') {
steps {
sh 'nvidia-smi'
sh 'python test.py'
}
}
}
}
经过这些年处理各种CUDA相关问题的经验,我总结出一个黄金法则:任何GPU相关错误,首先检查四件套的版本匹配——驱动、CUDA、cuDNN、PyTorch。保持环境的一致性记录(比如用requirements.txt记录完整版本号),能节省大量调试时间。