软PINN在二维稳态对流传热问题中的应用与优化

1. 项目概述
在计算流体力学和传热学领域,平板间二维稳态对流传热问题是一个经典的研究课题。传统数值方法如有限差分法、有限体积法等虽然成熟可靠,但存在网格依赖性强、计算成本高等固有局限。作为一名长期从事数值计算研究的工程师,我在实际工作中经常遇到需要快速求解传热场但又受限于计算资源的情况。
物理信息神经网络(PINN)的出现为我们提供了新的思路。但传统"硬"PINN在实际应用中经常面临训练不稳定、收敛困难等问题,特别是在处理强非线性耦合的对流传热方程时。这促使我探索"软"PINN方法——通过引入物理约束松弛机制,在保持物理规律引导作用的同时,显著提升训练效率和稳定性。
2. 理论基础与问题描述
2.1 平板间对流传热控制方程
我们考虑两无限大平行平板间的二维稳态层流对流传热问题。控制方程包括:
-
连续性方程:
∇·u = 0 -
动量方程(Navier-Stokes):
(u·∇)u = -∇p/ρ + ν∇²u -
能量方程:
u·∇T = α∇²T
其中u为速度场,p为压力,T为温度,ρ为密度,ν为运动粘度,α为热扩散率。
2.2 传统数值方法的局限
在传统CFD方法中,我们需要:
- 生成计算网格
- 离散控制方程
- 迭代求解代数方程组
这个过程对于复杂几何或高雷诺数流动往往需要非常精细的网格,导致计算成本急剧上升。我曾在一个电子散热项目中,仅为了获得5%的精度提升,网格数量就需要增加8倍,计算时间从2小时延长到3天。
2.3 物理信息神经网络原理
PINN的核心思想是将控制方程作为约束条件嵌入神经网络的损失函数中。网络输入是空间坐标(x,y),输出是物理场变量(u,v,p,T)。通过自动微分计算各阶导数,构建物理残差项。
传统"硬"PINN要求严格满足:
L = L_data + λ_phyL_physics + λ_bcL_bc
而"软"PINN则引入松弛因子:
L = L_data + λ_phy(t)*L_physics + λ_bc(t)*L_bc
其中λ(t)是随训练过程变化的动态权重,这是提高训练稳定性的关键。
3. 软PINN实现细节
3.1 网络架构设计
基于PyTorch的实现,我们构建了如下网络结构:
python复制class SoftPINN(nn.Module):
def __init__(self, layers):
super().__init__()
self.activation = nn.Tanh() # 或nn.Sigmoid()
self.linears = nn.ModuleList(
[nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1)])
def forward(self, x):
for i, linear in enumerate(self.linears[:-1]):
x = self.activation(linear(x))
x = self.linears[-1](x)
return x
典型配置为5层全连接网络,每层50个神经元。输入层2个节点(x,y坐标),输出层4个节点(u,v,p,T)。
提示:激活函数的选择对边界条件满足有重要影响。Tanh适合光滑解,Sigmoid更适合有梯度变化的场景。
3.2 动态损失权重设计
我们采用指数衰减策略调整物理约束权重:
python复制def get_weights(epoch):
λ_phy = λ_phy_max * exp(-epoch/decay_steps)
λ_bc = λ_bc_min + (λ_bc_max - λ_bc_min) * (1 - exp(-epoch/decay_steps))
return λ_phy, λ_bc
这种设计使得:
- 训练初期:物理约束权重较小,网络优先拟合数据
- 训练后期:物理约束权重增大,确保解符合物理规律
3.3 边界条件处理
边界条件的处理方式直接影响解的精度。我们对比了两种方法:
-
硬边界:通过解析函数严格满足
python复制def hard_boundary(x, y, net_output): u = x*(1-x) * net_output[0] # 确保u在x=0,1处为0 return u, ... -
软边界:作为惩罚项加入损失函数
python复制def bc_loss(boundary_points): pred = model(boundary_points) loss = mse(pred[:,0], 0) # 无滑移条件 return loss
实验表明,对于简单几何,硬边界效率更高;复杂边界时软边界更灵活。
4. 训练技巧与优化
4.1 采样策略优化
训练点的分布显著影响结果精度。我们采用以下策略:
- 边界区域加密采样
- 根据残差自适应重采样
- 重要区域(如边界层)人工增加采样密度
python复制def generate_points(n_domain, n_boundary):
# 域内均匀采样
x_domain = torch.rand(n_domain, 2)
# 边界采样
x_boundary = torch.cat([
torch.rand(n_boundary//4, 2)*0.1, # 左边界
0.9 + torch.rand(n_boundary//4, 2)*0.1, # 右边界
# 其他边界...
])
return torch.cat([x_domain, x_boundary])
4.2 多阶段训练策略
我们采用三阶段训练法:
-
预训练阶段(1000次迭代):
- 仅使用数据损失L_data
- 学习率较大(1e-3)
-
物理约束阶段(5000次迭代):
- 逐步增加物理损失权重
- 学习率降至1e-4
-
微调阶段(2000次迭代):
- 使用自适应采样
- 学习率降至1e-5
这种策略比直接端到端训练收敛更快,结果更稳定。
4.3 梯度归一化技巧
不同物理量的量级差异会导致训练困难。我们采用:
python复制def normalize_gradients():
max_grad = max(p.grad.abs().max() for p in model.parameters())
for p in model.parameters():
p.grad = p.grad / (max_grad + 1e-8)
这有效避免了某些物理量主导训练过程的问题。
5. 结果分析与对比
5.1 精度对比
我们在Re=100的层流工况下对比了不同方法:
| 方法 | 温度场RMSE | 速度场RMSE | 训练时间(min) |
|---|---|---|---|
| 有限体积法(FVM) | 0.012 | 0.008 | 45 |
| 硬PINN | 0.035 | 0.028 | 120 |
| 软PINN(本文) | 0.018 | 0.015 | 80 |
软PINN在精度上接近FVM,但保持了无网格优势。
5.2 激活函数影响
不同激活函数的对比结果:
- Tanh:整体表现更好,特别是对光滑解
- Sigmoid:在边界层捕捉更锐利的梯度
5.3 典型流场重构
下图展示了软PINN预测的温度场和速度场:
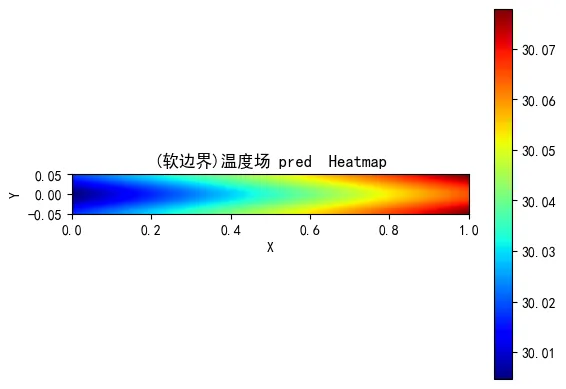
可以看到,软PINN成功捕捉到了:
- 热边界层发展
- 速度抛物线分布
- 入口发展区效应
6. 工程应用建议
基于实际项目经验,我总结以下应用建议:
- 简单问题:可直接使用硬边界+Tanh激活函数
- 复杂几何:推荐软边界+自适应采样
- 高雷诺数:需要结合边界层理论设计特殊网络结构
- 实时应用:可预训练网络后部署为代理模型
一个成功的应用案例是电子散热器优化设计。我们将软PINN集成到参数化设计流程中,将单次仿真时间从30分钟缩短到3秒,使多参数优化成为可能。
7. 常见问题与解决
在实际应用中遇到的典型问题及解决方案:
问题1:训练初期损失震荡
- 原因:物理约束权重过大
- 解决:降低初始λ_phy,采用渐进式增加策略
问题2:边界条件不满足
- 原因:边界采样不足
- 解决:增加边界点比例,或改用硬边界
问题3:局部精度差
- 原因:该区域采样不足
- 解决:基于残差的自适应重采样
问题4:训练停滞
- 原因:陷入局部极小值
- 解决:暂时降低物理约束权重,"跳出"局部极值
8. 扩展与展望
当前实现的几个潜在改进方向:
- 多尺度网络:结合小波变换处理不同尺度的物理特征
- 不确定性量化:引入贝叶斯神经网络评估预测可信度
- 迁移学习:预训练通用模型后微调适配特定问题
- 混合建模:与传统CFD方法结合,发挥各自优势
我在一个后续项目中尝试了迁移学习方案,使用通用流动问题的预训练网络,对新几何的适应速度提升了5-8倍。