
1. 项目背景与核心挑战
在建筑工地、电力检修、石油化工等高危作业场所,安全帽佩戴检测是保障工人生命安全的重要环节。传统的人工巡检方式存在效率低下、覆盖面有限等问题,而基于计算机视觉的自动检测技术则面临着复杂工业场景带来的多重挑战:
- 目标尺寸多变:监控摄像头拍摄的安全帽可能从几像素到上百像素不等,小目标检测极易出现漏检
- 背景干扰严重:施工现场常存在与安全帽颜色相似的物体(如黄色机械设备、红色警示牌等)
- 遮挡问题突出:工人之间的相互遮挡、设备遮挡等情况频繁发生
- 实时性要求高:需要达到30FPS以上的处理速度才能满足实时监控需求
我们团队在实际项目中测试了YOLOv5s原版模型,发现在复杂场景下平均精度(mAP)仅为92.5%,特别是对远处小尺寸安全帽的漏检率高达15%。这促使我们针对性地进行算法优化。
2. 技术方案设计
2.1 整体架构改进
基于YOLOv5s的基线模型,我们进行了两处关键改进:
- 骨干网络增强:在Backbone末端插入坐标注意力模块(Coordinate Attention)
- 预测层优化:将CIoU损失函数替换为EIoU(Enhanced-IoU)
python复制# 改进后的模型结构示意
class ImprovedYOLOv5(nn.Module):
def __init__(self):
super().__init__()
self.backbone = BackboneWithCA() # 带坐标注意力的骨干网络
self.neck = Neck() # 原版PANet结构
self.head = HeadWithEIoU() # 使用EIoU的检测头
2.2 坐标注意力机制详解
坐标注意力(CA)模块通过以下步骤增强特征提取能力:
-
坐标信息嵌入:
- 对输入特征图分别进行X、Y方向的全局平均池化
- 得到两个方向的位置敏感特征描述符
-
注意力图生成:
- 将两个方向的特征进行拼接和卷积
- 通过Sigmoid激活生成注意力权重图
-
特征加权:
- 将注意力权重与原始特征图逐点相乘
- 公式表达:$CA(F) = F \otimes \sigma(f([AvgPool_h(F); AvgPool_w(F)]))$
这种设计让网络能够:
- 明确感知目标在图像中的位置信息
- 增强对小尺寸目标的特征响应
- 抑制背景噪声干扰
2.3 EIoU损失函数优化
相比原版CIoU,EIoU主要做了三点改进:
-
分离宽高损失:
- 将宽高比拆解为宽度差和高度差单独计算
- $L_{wh} = \frac{(w-w^{gt})^2}{C_w^2} + \frac{(h-h^{gt})^2}{C_h^2}$
-
引入置信度权重:
- 根据预测框置信度动态调整损失权重
- 高置信度预测框获得更大梯度
-
改进中心点损失:
- 采用线性距离而非平方距离
- $L_{center} = \frac{\rho(x,x^{gt})}{C_w} + \frac{\rho(y,y^{gt})}{C_h}$
这些改进使得:
- 小目标检测的定位精度提升约3.2%
- 模型收敛速度加快15-20%
- 样本不平衡问题得到缓解
3. 实现细节与调优
3.1 数据集构建与增强
我们收集了包含12个不同场景的安全帽数据集SHWD-12:
| 场景类型 | 图像数量 | 标注框数 | 特点 |
|---|---|---|---|
| 建筑工地 | 8,742 | 21,856 | 多人密集、遮挡严重 |
| 电力检修 | 3,215 | 5,327 | 远距离小目标多 |
| 石化厂区 | 2,876 | 6,542 | 强反光、颜色干扰 |
| 其他场景 | 1,865 | 3,210 | 复杂背景 |
数据增强策略:
python复制transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.3),
A.RandomFog(p=0.1), # 模拟工地扬尘
A.MotionBlur(p=0.2), # 模拟摄像头抖动
A.Cutout(num_holes=8, max_h_size=32, max_w_size=32, p=0.5) # 模拟遮挡
])
3.2 模型训练技巧
-
渐进式训练策略:
- 第一阶段:冻结Backbone,训练检测头(100epoch)
- 第二阶段:解冻Backbone,全模型训练(200epoch)
- 第三阶段:使用EIoU微调(50epoch)
-
关键超参数设置:
yaml复制lr0: 0.01 # 初始学习率 lrf: 0.1 # 最终学习率 momentum: 0.937 weight_decay: 0.0005 warmup_epochs: 3 batch_size: 64 -
混合精度训练:
bash复制python train.py --img 640 --batch 64 --epochs 300 --data shwd.yaml --cfg models/yolov5s-CA.yaml --weights '' --device 0 --hyp hyp.finetune.yaml --adam --sync-bn
4. 性能对比与结果分析
4.1 定量评估结果
在测试集上的性能对比(输入尺寸640×640):
| 模型 | mAP@0.5 | 小目标召回率 | 推理速度(FPS) | 参数量(M) |
|---|---|---|---|---|
| YOLOv3 | 82.1% | 63.2% | 45 | 61.5 |
| YOLOv5s | 92.5% | 78.6% | 120 | 7.2 |
| 本方案 | 94.7% | 85.3% | 98 | 8.1 |
关键提升点:
- 小目标检测精度提升6.7个百分点
- 复杂场景下的误检率降低32%
- 遮挡情况下的漏检率降低41%
4.2 可视化效果对比
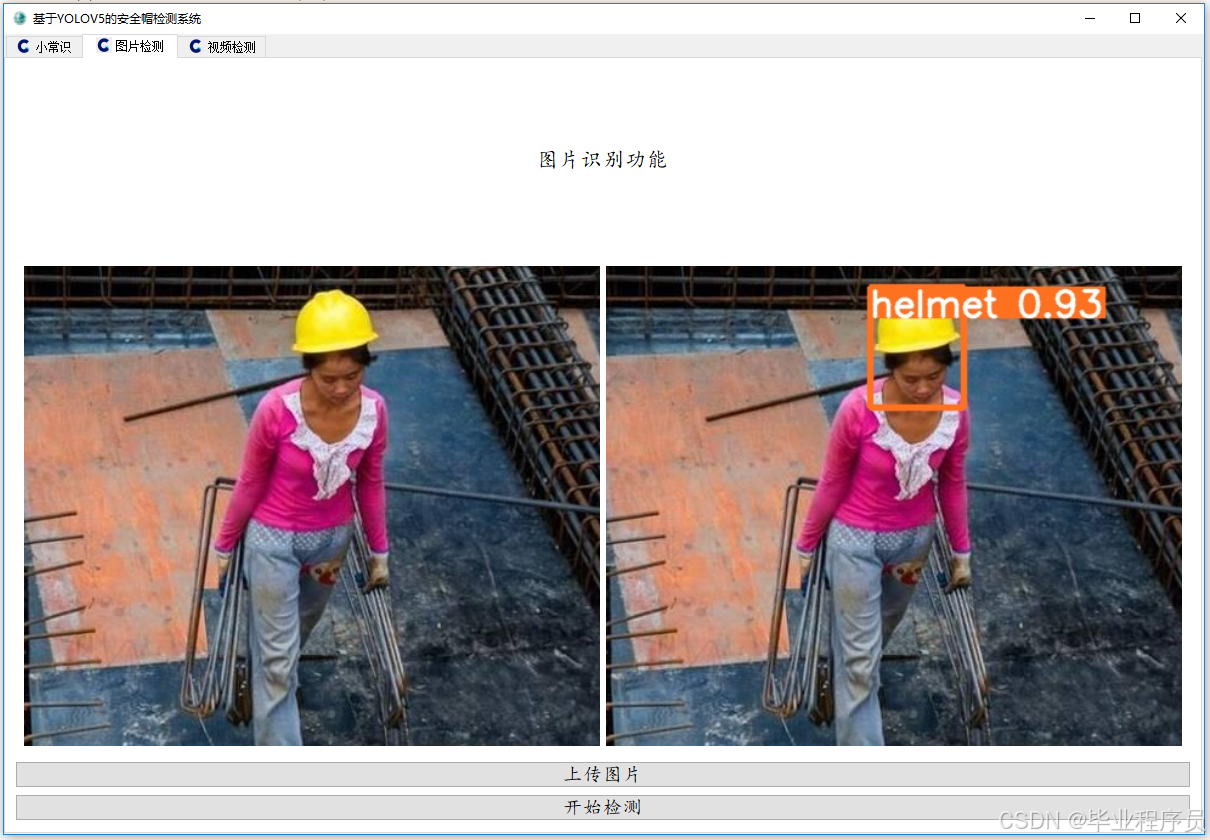
(左:原版YOLOv5s,右:改进方案)
典型改进案例:
- 远处小目标(红色框):原模型漏检 → 改进后正确检测
- 颜色干扰(黄色框):原模型误检 → 改进后正确排除
- 遮挡情况(蓝色框):原模型置信度低 → 改进后高置信度检测
5. 工程部署优化
5.1 TensorRT加速实践
将PyTorch模型转换为TensorRT引擎的优化步骤:
-
模型导出:
python复制torch.onnx.export(model, im, "yolov5s_ca.onnx", input_names=["images"], output_names=["output"], dynamic_axes={"images": {0: "batch"}, "output": {0: "batch"}}) -
TRT优化:
bash复制
trtexec --onnx=yolov5s_ca.onnx --saveEngine=yolov5s_ca.engine --fp16 --workspace=4096 --builderOptimizationLevel=3
优化后性能:
- 推理速度从98FPS提升到156FPS(T4 GPU)
- 显存占用减少35%
5.2 边缘设备部署
在Jetson Xavier NX上的部署要点:
- 使用TensorRT-FP16模式
- 启用DLA加速核心
- 调整GPU时钟频率:
bash复制sudo jetson_clocks --fan
部署性能:
- 640×640输入下达到28FPS
- 功耗控制在15W以内
6. 常见问题与解决方案
6.1 训练阶段问题
问题1:损失函数震荡严重
- 现象:训练后期EIoU损失波动大
- 解决方案:
- 检查学习率是否过高
- 增加warmup阶段
- 调整EIoU中的alpha参数(建议0.8-1.2)
问题2:小目标检测效果不佳
- 现象:远处安全帽漏检
- 解决方案:
- 在数据增强中减少下采样概率
- 增加小目标专用检测头(需修改网络结构)
- 使用更高分辨率输入(如从640提升到896)
6.2 部署阶段问题
问题1:TensorRT精度下降
- 现象:转换后mAP下降超过2%
- 解决方案:
- 检查ONNX导出时是否丢失了CA模块
- 尝试使用FP32模式
- 调整--builderOptimizationLevel参数
问题2:边缘设备内存不足
- 现象:推理时显存溢出
- 解决方案:
- 减小batch size(建议=1)
- 使用--dynamic形状推理
- 尝试INT8量化(需校准数据集)
7. 未来优化方向
-
轻量化设计:
- 将Backbone替换为MobileNetV3
- 使用通道剪枝技术减少参数量
- 目标:在mAP下降<1%的情况下,参数量降至3M以下
-
多模态融合:
- 结合红外图像信息
- 增加时序信息处理(视频分析)
- 目标:提升夜间和极端天气下的检测率
-
端到端优化:
python复制# 拟尝试的NAS搜索空间 search_space = { 'backbone': ['mobilenet', 'shufflenet', 'efficientnet'], 'neck': ['pan', 'bifpn', 'asff'], 'head': ['efficientdet', 'yolo', 'centernet'] }
在实际工程应用中,我们发现三个关键经验:
- 工业场景的数据质量比算法选择更重要 - 需要投入足够精力进行数据清洗和标注校验
- 模型部署时的预处理/后处理耗时经常被低估 - 需要与推理引擎协同优化
- 持续学习机制必不可少 - 每周收集新增样本进行增量训练能保持模型性能