RAG系统中文档影响力量化方法解析

1. 论文概述与核心问题
这篇题为《Quantifying Document Impact in RAG-LLMs》的论文由马里兰大学的研究团队于2026年发表,主要解决检索增强生成(RAG)系统中一个关键问题:如何量化每个检索到的文档对最终生成答案的实际贡献程度。RAG系统虽然能有效缓解大语言模型(LLM)的幻觉问题,但同时也带来了新的挑战——我们无法准确知道模型在生成答案时,到底更"依赖"哪个文档。
传统方法通常采用提示词工程(prompt engineering)让模型自报出处,但这种方法存在明显缺陷:模型可能会为了符合引用格式而简化推理过程,而且对提示词的遵循并不稳定。更严重的是,当存在恶意文档(poisoned documents)时,模型可能无法准确识别并报告其影响。
2. RAG系统的基本流程与挑战
2.1 RAG标准流程
典型的RAG系统工作流程如下:
- 用户输入查询(query)
- 检索器(retriever)从知识库中找出top-k相关文档
- 将查询和检索到的文档一起输入LLM
- LLM基于上下文生成最终答案
这个过程看似简单,但存在一个黑箱问题:我们不知道每个文档对最终答案的实际贡献有多大。当答案出现问题时,我们难以定位是哪个文档导致了错误;当需要优化检索系统时,我们缺乏细粒度的反馈指标。
2.2 现有方法的局限性
当前主要有三种方法试图解决这个问题,但各有不足:
-
注意力机制分析:直接查看transformer模型的注意力权重。问题在于:
- 注意力权重并不直接对应信息重要性
- 很多商用LLM不开放注意力权重
- 计算复杂度高
-
提示词工程:通过设计特殊提示让模型说明参考了哪些文档。问题在于:
- 模型可能虚构引用来源
- 引用格式会干扰正常推理
- 对提示词设计敏感
-
基于梯度的归因方法:计算输入对输出的梯度影响。问题在于:
- 需要模型参数访问权限
- 计算成本极高
- 结果难以解释
3. 核心方法:基于PID理论的影响力评分(IS)
3.1 部分信息分解(PID)理论基础
论文创新性地采用了部分信息分解(Partial Information Decomposition, PID)理论框架。PID是一种信息论方法,用于分析多个输入变量如何共同影响输出变量。它将信息分解为三种成分:
-
互信息(Mutual Information, I):单个来源与目标之间的关系
- 在RAG中:仅给LLM这一个文档时,它能提供多少有用信息
-
并集信息(Union Information, U):至少一个来源提供的总信息量
- 在RAG中:所有文档共同为答案提供了多少知识
-
排除信息(Excluded Information, E):除了某一特定来源外,其他来源的信息总和
- 在RAG中:如果没有文档A,剩下的文档能提供多少有用信息
数学表达式为:
code复制E(Xi→Y|X1,...,Xk) = U(X1,...,Xk;Y) - I(Xi;Y)
I(Xi;Y) = H(Y) - H(Y|Xi)
U(X1,...,Xk;Y) = inf_Q I(Q;Y) s.t. ∀i Xi∈Q
3.2 语义熵的引入与计算
传统PID需要计算概率分布,但在RAG场景中直接应用会遇到两个问题:
- 检索到的文档是确定性的检索结果,不是随机变量
- 文本输出的可能组合太多,无法计算完整概率分布
论文创新地采用语义熵(Semantic Entropy)替代传统香农熵,解决了这些问题:
-
解决语义冗余:传统熵基于token计算,而语义熵基于意思计算。例如"北京是中国的首都"和"中国的首都是北京"会被识别为相同语义。
-
应对无限样本空间:通过采样有限数量的响应(如10个),计算它们之间的语义相似度,将无限文本空间坍缩为有限"含义簇"。
语义熵计算流程:
- 对同一查询生成N个响应
- 获取每个响应的句子嵌入(BERT模型)
- 计算所有响应间的余弦相似度
- 归一化相似度分数到[0,1]
- 通过softmax转换为概率分布
- 计算熵值:H_S = Σ p_i log2(p_i)
3.3 影响力评分(IS)的定义与计算
基于PID和语义熵,论文定义了影响力评分(Influence Score, IS):
code复制IS_i = -E(Xi→Y|X1,...,Xk)
= I(Xi;Y) - U(X1,...,Xk;Y)
= H_S(Y|X1,...,Xk) - H_S(Y|Xi)
IS的直观解释:
- 值越接近0(越高),说明该文档是核心文档
- 负得越多(越低),说明其他文档才是主力
添加负号是为了使IS与依赖程度呈正相关关系。
4. 实验验证与结果分析
4.1 恶意文档识别实验(Poison Attack)
实验设置:
- 在5个检索文档中植入1个恶意文档
- 恶意文档包含错误信息
- 测试IS能否识别出恶意文档
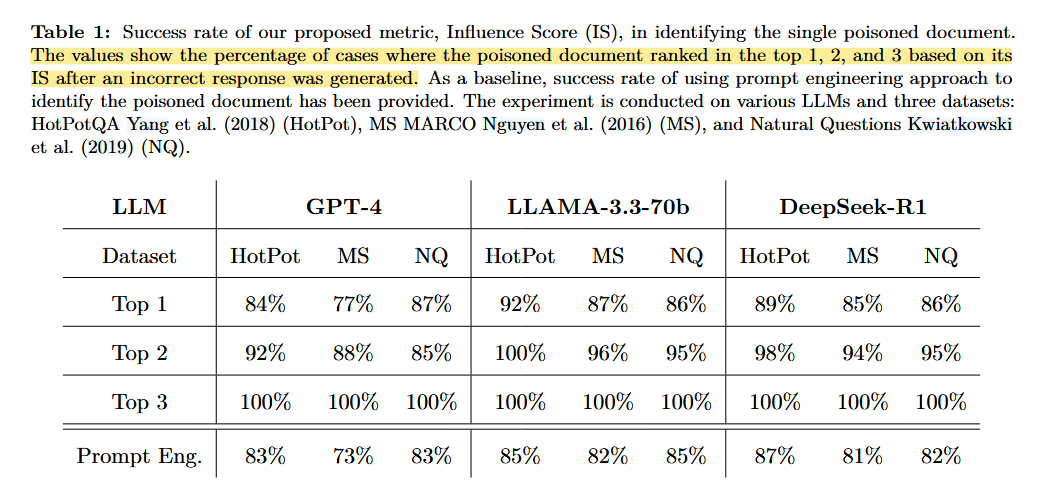
关键结果:
- 86%的案例中,IS成功将恶意文档识别为影响力第一
- 前3名检出率达到100%
- 显著优于提示词工程方法
4.2 消融实验(Ablation Study)
实验设置:
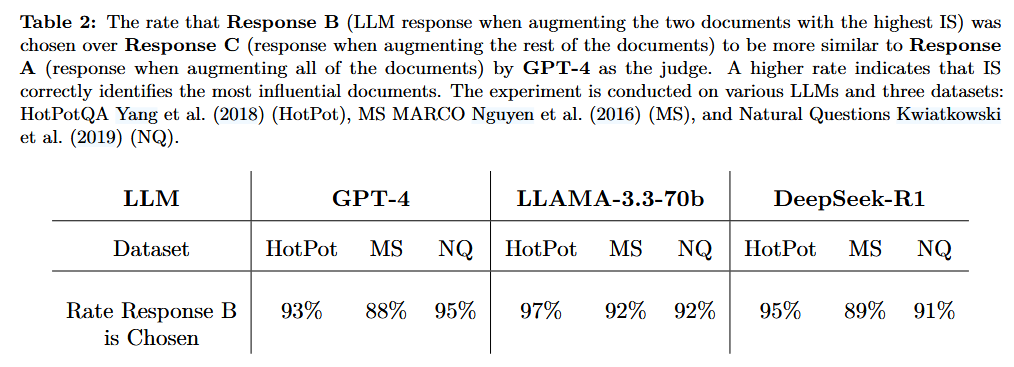
- Response A:使用所有文档生成(基准)
- Response B:仅使用IS最高的两个文档生成
- Response C:使用剩余文档生成
- 由GPT-4和人类评估相似度
关键结果:
- Response B与基准A最相似
- 证明IS选出的确实是"含金量"最高的文档
- 人类评估与GPT-4评估结果一致
5. 实际应用价值与局限性
5.1 应用价值
-
增强归因与事实核查:
- 可视化每个文档的贡献权重
- 快速定位错误信息的来源
- 提高生成结果的可解释性
-
偏见识别:
- 分析模型更倾向于哪些文档
- 发现知识库中的潜在偏见
- 为数据清洗提供依据
-
检索优化:
- 基于实际贡献而非相似度优化检索
- 改进embedding模型和排序算法
- 提升RAG系统的整体效果
-
安全防御:
- 快速识别并剔除毒化数据源
- 降低对抗性攻击的风险
- 提高系统的鲁棒性
5.2 局限性
-
计算开销:
- 计算k个文档的IS需要进行2k+1次推理
- 不适合实时性要求高的场景
- 可能增加API调用成本
-
适用边界:
- 当LLM主要依赖内部知识时效果下降
- 对完全错误的文档识别有限
- 需要足够多样的采样响应
6. 实现细节与实操建议
6.1 实现步骤
-
设置基础环境:
- 准备RAG系统(如LangChain框架)
- 选择适合的embedding模型(论文使用BERT)
- 确定采样次数N(论文使用10次)
-
计算语义熵:
python复制def compute_semantic_entropy(responses, embedding_model): # 获取所有响应的嵌入 embeddings = [embedding_model.encode(r) for r in responses] # 计算余弦相似度矩阵 sim_matrix = cosine_similarity(embeddings) # 归一化相似度(行归一化) norm_sim = sim_matrix / sim_matrix.sum(axis=1, keepdims=True) # 计算语义熵 entropy = -np.sum(norm_sim * np.log2(norm_sim + 1e-10), axis=1).mean() return entropy -
计算IS分数:
python复制def compute_influence_score(query, docs, llm, embedding_model, N=10): # 计算H_S(Y|X1,...,Xk) full_context = "\n".join(docs) full_responses = [llm.generate(full_context, query) for _ in range(N)] H_full = compute_semantic_entropy(full_responses, embedding_model) IS_scores = [] for doc in docs: # 计算H_S(Y|Xi) single_responses = [llm.generate(doc, query) for _ in range(N)] H_single = compute_semantic_entropy(single_responses, embedding_model) # 计算IS_i IS_i = H_full - H_single IS_scores.append(IS_i) return IS_scores
6.2 优化建议
-
计算效率优化:
- 并行化多个推理请求
- 缓存中间计算结果
- 对长文档进行分块处理
-
质量提升技巧:
- 增加采样次数N可以提高稳定性
- 使用更先进的embedding模型(如SimCSE)
- 结合其他归因方法进行交叉验证
-
应用场景选择:
- 优先在关键任务中使用
- 对高风险查询进行分析
- 定期抽样检查文档影响力
7. 延伸思考与未来方向
这项研究为RAG系统的可解释性提供了重要工具,但仍有多个值得探索的方向:
-
动态IS计算:
- 研究增量式计算IS的方法
- 减少重复计算
- 适应流式处理场景
-
多模态扩展:
- 应用于图像、表格等多模态文档
- 开发跨模态的影响力评估
- 处理混合内容的影响力分解
-
训练阶段集成:
- 将IS作为训练信号
- 优化检索器和生成器的协同
- 开发基于IS的主动学习策略
-
安全增强:
- 构建基于IS的实时监测系统
- 开发对抗性文档检测算法
- 建立文档影响力异常预警机制
在实际应用中,我们可以根据具体需求对IS方法进行调整。例如,对于实时性要求高的场景,可以开发轻量级近似算法;对于关键任务系统,可以结合IS与其他解释性方法提供更全面的分析。