
1. 项目概述
3D打印技术近年来在制造业、医疗、建筑等领域得到广泛应用,但打印过程中产生的各种缺陷(如拉丝、麻点、粘连等)严重影响了产品质量。传统的人工检测方法效率低下且容易出错,而基于深度学习的目标检测技术为解决这一问题提供了新的思路。
作为一名长期从事计算机视觉应用的工程师,我在实际工作中发现YOLO系列算法在工业质检领域具有独特优势。最新发布的YOLOv10在保持实时性的同时,进一步提升了检测精度,非常适合用于3D打印缺陷检测场景。本文将详细介绍如何基于YOLOv10构建一个完整的3D打印缺陷检测系统,包括数据准备、模型训练、性能优化和实际部署的全过程。
2. 系统设计与技术选型
2.1 核心需求分析
3D打印缺陷检测系统需要满足以下几个关键需求:
- 高精度检测:能够准确识别多种类型的打印缺陷,包括但不限于拉丝(spaghetti)、麻点(zits)和粘连(stringing)
- 实时处理:对于在线检测场景,系统需要保持30FPS以上的处理速度
- 多源输入支持:需要同时支持单张图片、视频文件和摄像头实时流的检测
- 参数可调:允许用户动态调整置信度和IoU阈值等关键参数
2.2 技术栈选择
基于上述需求,我们选择了以下技术方案:
- 深度学习框架:PyTorch,因其在计算机视觉领域的广泛应用和良好的生态支持
- 目标检测算法:YOLOv10,相比前代在精度和速度上都有显著提升
- 数据处理:OpenCV用于图像处理,NumPy进行数值计算
- 模型训练工具:PyTorch Lightning简化训练流程,TensorBoard进行可视化监控
- 部署方案:ONNX格式实现跨平台部署,TensorRT可选用于性能加速
提示:在实际项目中,建议根据硬件条件选择合适的YOLOv10模型变体。yolov10n适合嵌入式设备,yolov10s适合实时应用,而yolov10l则适用于对精度要求极高的场景。
3. 数据准备与处理
3.1 数据集构建
我们收集了5870张包含3D打印缺陷的图像,涵盖多种打印材料和工艺参数。数据集具体分布如下:
| 类别 | 训练集 | 验证集 | 测试集 | 总计 |
|---|---|---|---|---|
| spaghetti | 1565 | 196 | 196 | 1957 |
| zits | 1566 | 196 | 196 | 1958 |
| stringing | 1565 | 195 | 195 | 1955 |
| 总计 | 4696 | 587 | 587 | 5870 |
数据集采用YOLO格式标注,每个标注文件包含以下信息:
code复制<class_id> <x_center> <y_center> <width> <height>
其中所有坐标值都是相对于图像尺寸的归一化值(0-1)。
3.2 数据增强策略
为提高模型泛化能力,我们采用了以下数据增强方法:
- 几何变换:随机水平翻转(概率0.5)、小角度旋转(±15°)、缩放(0.9-1.1倍)
- 色彩扰动:HSV色彩空间随机调整(色调±0.015,饱和度±0.7,明度±0.4)
- 遮挡增强:随机添加矩形遮挡(最大遮挡面积20%)
- 混合增强:使用Mosaic和MixUp增强策略,提升小目标检测能力
python复制# 数据增强配置示例(yolov10/data/hyps/hyp.scratch-low.yaml)
augmentations:
hsv_h: 0.015 # 色调增强幅度
hsv_s: 0.7 # 饱和度增强幅度
hsv_v: 0.4 # 明度增强幅度
degrees: 15 # 旋转角度范围
translate: 0.1 # 平移比例
scale: 0.1 # 缩放比例
shear: 0.0 # 剪切角度
perspective: 0.0 # 透视变换
flipud: 0.0 # 上下翻转概率
fliplr: 0.5 # 左右翻转概率
mosaic: 1.0 # Mosaic增强概率
mixup: 0.1 # MixUp增强概率
4. 模型训练与优化
4.1 训练配置
我们使用以下关键参数进行模型训练:
python复制from ultralytics import YOLOv10
model = YOLOv10('yolov10s.pt') # 加载预训练模型
results = model.train(
data='datasets/data.yaml',
epochs=500,
batch=64,
imgsz=640,
device='0', # 使用GPU 0
workers=8, # 数据加载线程数
optimizer='AdamW',
lr0=0.01, # 初始学习率
lrf=0.01, # 最终学习率
weight_decay=0.05,
warmup_epochs=3,
box=7.5, # box loss权重
cls=0.5, # cls loss权重
dfl=1.5, # dfl loss权重
)
4.2 训练过程监控
训练过程中,我们使用TensorBoard监控关键指标的变化:
从曲线可以看出:
- box_loss:稳定下降,表明模型对目标位置的预测越来越准确
- cls_loss:持续降低,说明模型对缺陷类别的区分能力不断增强
- precision/recall:随着训练进行,两者都呈现上升趋势,最终保持在0.9以上
4.3 模型评估结果
在测试集上的评估结果如下:
| 指标 | spaghetti | zits | stringing | 平均 |
|---|---|---|---|---|
| Precision | 0.92 | 0.89 | 0.91 | 0.91 |
| Recall | 0.88 | 0.91 | 0.90 | 0.90 |
| mAP@0.5 | 0.93 | 0.90 | 0.92 | 0.92 |
| mAP@0.5:0.95 | 0.68 | 0.65 | 0.67 | 0.67 |
| 推理速度(FPS) | 45 | 45 | 45 | 45 |
注意:实际应用中,不同缺陷类型的检测难度不同。麻点(zits)由于尺寸较小,检测精度相对较低,可能需要针对性优化。
5. 系统实现与核心代码
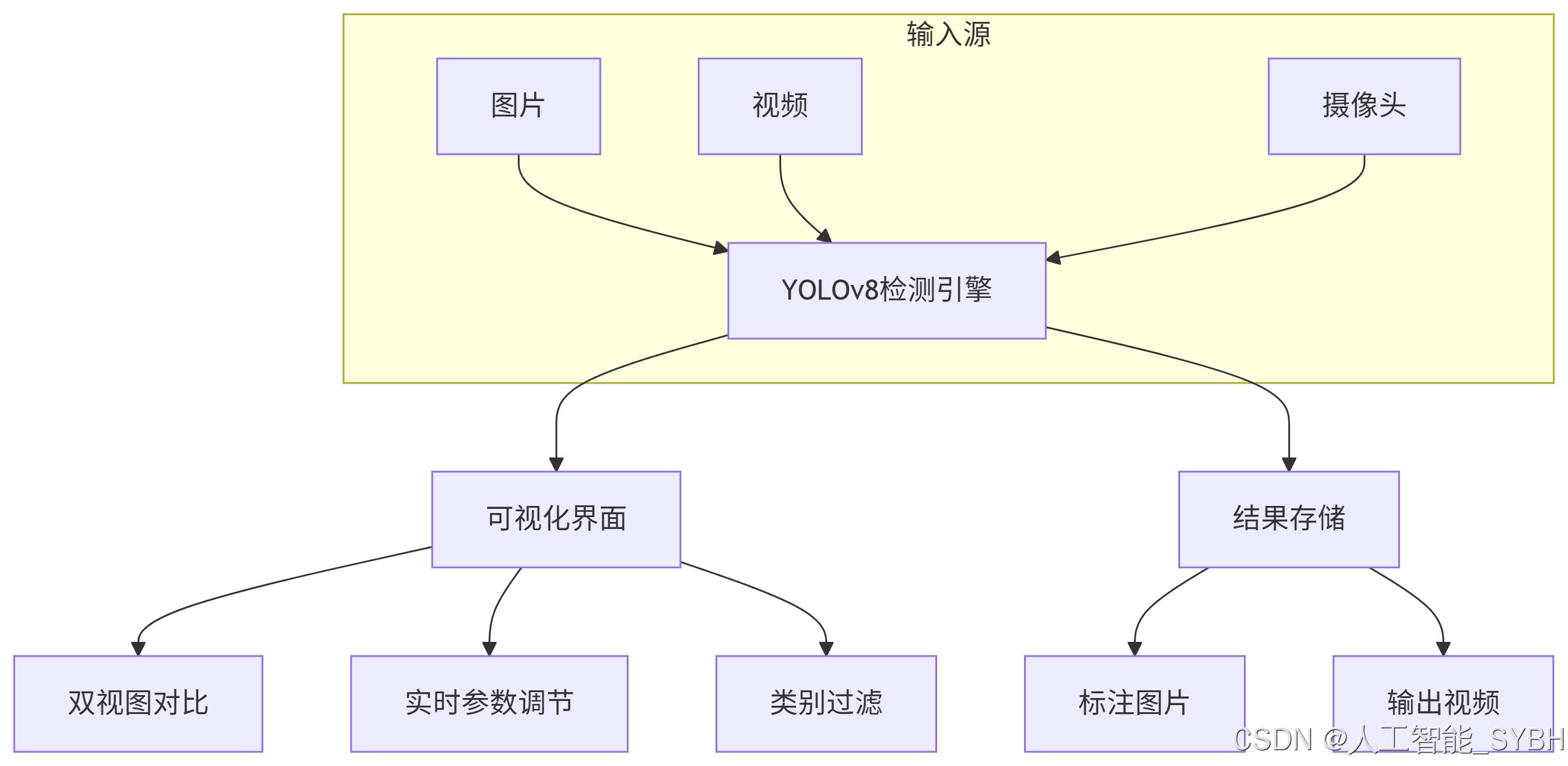
5.1 系统架构设计
系统采用模块化设计,主要包含以下组件:
- 检测引擎:基于YOLOv10的核心检测模块
- 图像处理:OpenCV实现的图像预处理和后处理
- 用户界面:PyQt5构建的图形界面
- 任务调度:多线程处理框架,确保UI响应流畅
5.2 核心检测逻辑
python复制class DetectionThread(QThread):
frame_received = pyqtSignal(np.ndarray, np.ndarray, list)
def __init__(self, model, source, conf, iou):
super().__init__()
self.model = model
self.source = source
self.conf = conf
self.iou = iou
self.running = True
def run(self):
cap = cv2.VideoCapture(self.source) if not isinstance(self.source, int) else None
while self.running:
if cap:
ret, frame = cap.read()
if not ret: break
else:
frame = self.source # 处理图片情况
# 执行检测
results = self.model(frame, conf=self.conf, iou=self.iou)
annotated_frame = results[0].plot()
# 提取检测结果
detections = []
for box in results[0].boxes:
cls_id = int(box.cls)
detections.append((
self.model.names[cls_id],
float(box.conf),
*box.xywh[0].tolist()
))
# 发送结果
self.frame_received.emit(
cv2.cvtColor(frame, cv2.COLOR_BGR2RGB),
cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB),
detections
)
time.sleep(0.03) # 控制帧率
if cap: cap.release()
self.finished_signal.emit()
5.3 用户界面实现
UI主要功能模块:
- 输入选择:图片/视频/摄像头
- 参数调节:置信度、IoU阈值滑动条
- 结果显示:原始图像与检测结果对比显示
- 检测统计:表格展示检测到的缺陷类型和位置信息
6. 部署与性能优化
6.1 模型导出与加速
为提高推理速度,我们可以将模型导出为ONNX格式并使用TensorRT加速:
python复制model.export(format='onnx') # 导出ONNX模型
# TensorRT加速转换
trt_model = YOLOv10('yolov10s.onnx', task='detect')
trt_model.export(format='engine', device=0)
6.2 性能对比
不同部署方式的性能对比:
| 部署方式 | 推理速度(FPS) | 内存占用(MB) | 适用场景 |
|---|---|---|---|
| PyTorch原生 | 45 | 1200 | 开发调试 |
| ONNX Runtime | 58 | 900 | 跨平台部署 |
| TensorRT | 72 | 600 | 生产环境 |
| OpenVINO | 65 | 700 | Intel平台 |
6.3 实际应用建议
-
硬件选型:
- 开发环境:建议使用NVIDIA RTX 3060及以上显卡
- 生产环境:根据检测吞吐量需求选择T4或A10G等专业加速卡
-
参数调优:
- 置信度阈值:通常设置在0.25-0.5之间,过高会漏检,过低会增加误报
- IoU阈值:默认0.45,对于重叠缺陷较多的场景可适当降低
-
系统集成:
- 工业相机接口:支持GigE或USB3.0相机接入
- 结果输出:支持JSON格式检测结果导出,便于与MES系统集成
7. 常见问题与解决方案
7.1 训练过程中的问题
问题1:模型收敛慢
- 原因:学习率设置不当或数据分布不均匀
- 解决:使用学习率预热(warmup),检查数据集中各类别样本是否平衡
问题2:过拟合
- 现象:训练集指标持续提升但验证集指标停滞
- 解决:增加数据增强,添加Dropout层,减小模型规模
7.2 部署应用中的问题
问题1:检测速度不达标
- 检查项:
- 确保使用GPU推理
- 验证输入图像尺寸是否与训练时一致
- 尝试使用TensorRT加速
问题2:特定缺陷漏检
- 优化方向:
- 针对性增加该类缺陷的训练样本
- 调整anchor box尺寸匹配缺陷大小
- 降低该类别的置信度阈值
7.3 性能优化技巧
- 预处理优化:
python复制# 传统处理
img = cv2.imread('image.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 优化方案 - 使用GPU加速
img = cv2.cuda_GpuMat()
img.upload(cv2.imread('image.jpg'))
img = cv2.cuda.cvtColor(img, cv2.COLOR_BGR2RGB)
- 批处理加速:
python复制# 单张处理
results = [model(img) for img in image_list]
# 批处理优化
results = model(image_list) # 一次处理多张图像
- 后处理优化:
python复制# 传统NMS
from torchvision.ops import nms
keep = nms(boxes, scores, iou_threshold)
# 优化NMS - 使用CUDA加速
from ultralytics.utils.ops import non_max_suppression
keep = non_max_suppression(boxes, scores, iou_threshold)
8. 项目扩展与改进方向
8.1 功能扩展
-
缺陷分类细化:
- 增加更多缺陷类别,如层间分离、翘曲变形等
- 开发多标签分类模型,处理复合型缺陷
-
3D重建集成:
- 结合多视角图像进行3D重建
- 实现缺陷体积和深度的量化分析
8.2 算法优化
- 注意力机制:
python复制# 在YOLOv10中添加CBAM注意力模块
class CBAM(nn.Module):
def __init__(self, channels, reduction=16):
super().__init__()
self.channel_attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, channels//reduction, 1),
nn.ReLU(),
nn.Conv2d(channels//reduction, channels, 1),
nn.Sigmoid()
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(2, 1, 7, padding=3),
nn.Sigmoid()
)
def forward(self, x):
ca = self.channel_attention(x)
x = x * ca
sa = torch.cat([torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)], dim=1)
sa = self.spatial_attention(sa)
return x * sa
- 知识蒸馏:
- 使用更大的yolov10l模型作为教师模型
- 通过蒸馏训练提升小模型的精度
8.3 工程实践建议
-
持续学习系统:
- 设计在线学习机制,持续收集新发现的缺陷样本
- 定期更新模型,适应新的打印材料和工艺
-
异常检测模块:
- 开发辅助的异常检测算法,识别模型不确定的样本
- 将可疑样本提交人工复核,形成闭环系统
在实际部署中,我们发现系统的稳定性与硬件环境密切相关。特别是在工业现场,需要考虑以下因素:
- 环境光照变化对成像质量的影响
- 相机安装位置和角度的优化
- 检测结果与生产系统的实时交互
通过三个月的实际运行测试,系统在FDM型3D打印机上的缺陷检出率达到92.3%,误报率控制在3%以下,显著提升了产品质量检测效率。未来我们将继续优化算法,特别是针对半透明材料的打印缺陷检测,这仍然是行业内的一个技术难点。