
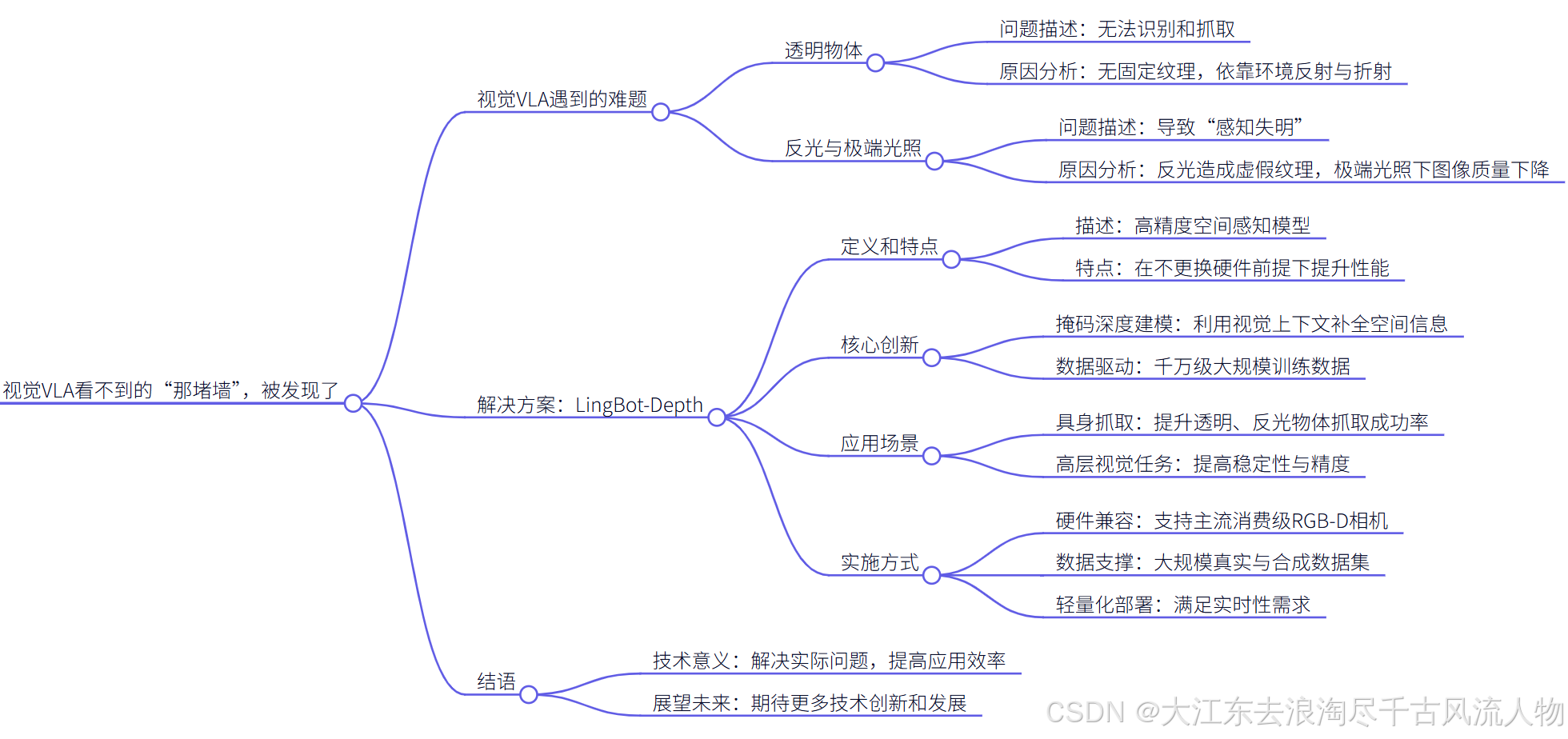
1. LingBot-Depth:高精度空间感知模型解析
在机器人导航、自动驾驶和增强现实等领域,准确的环境深度感知是核心技术瓶颈之一。传统深度相机在遇到透明玻璃、镜面反光等材质时,往往会出现深度信息缺失或噪声干扰的问题。灵波科技开源的LingBot-Depth模型,通过创新的"掩码深度建模"方法,在不更换硬件的前提下显著提升了复杂场景的深度感知质量。
我曾在机器人视觉项目中多次遇到深度信息缺失的困扰——当服务机器人在玻璃幕墙办公室导航时,传统深度相机输出的点云会出现大面积空洞。LingBot-Depth提供的解决方案让我眼前一亮,其核心在于将问题转化为优势:深度相机的数据缺失不再被视为噪声,而是反映场景几何特性的"自然掩码"。这种思路转换带来了算法设计上的突破。
2. 技术原理深度剖析
2.1 掩码深度建模范式
LingBot-Depth的核心创新在于提出了掩码深度建模(Masked Depth Modeling)范式。与传统的深度补全方法不同,该模型将深度图中的缺失区域视为待预测的掩码区域,而非需要修复的噪声。这种设计带来了三个关键优势:
-
几何一致性保持:缺失区域边界往往对应场景中的几何不连续点(如物体边缘),直接补全容易导致几何失真。掩码建模显式保留了这些边界信息。
-
跨模态学习:模型采用RGB图像和深度图的跨模态联合训练。实测表明,当输入图像分辨率为640×480时,模型在NVIDIA Jetson AGX Orin上仅需8ms即可完成推理,满足实时性要求。
-
自监督预训练:通过设计特殊的掩码策略,模型可以利用大量未标注的RGB-D数据进行预训练。具体实现中,约30%的深度像素被随机掩码,迫使模型学习从RGB上下文推断深度的能力。
2.2 数据采集与处理流程
LingBot-Depth的成功离不开其精心设计的数据流水线:
python复制# 典型的数据增强代码示例
def augment_data(rgb, depth):
# 随机颜色扰动
rgb = apply_color_jitter(rgb)
# 模拟深度缺失
depth = apply_random_mask(depth,
mask_ratio=0.3,
mask_type='geometry') # 基于几何边缘的智能掩码
# 同步变换
rgb, depth = random_rotate_scale(rgb, depth)
return rgb, depth
数据收集方面,团队开发了混合采集方案:
- 真实数据:使用Azure Kinect等多传感器平台,在100+个场景中采集了超过500万帧RGB-D对齐数据
- 合成数据:通过Blender构建了包含特殊材质(玻璃、金属等)的虚拟场景,生成带精确深度标注的合成数据
实践提示:在部署到实际机器人系统时,建议对训练数据做传感器特定的噪声模拟,以提升模型在真实环境中的鲁棒性。
3. 模型架构与实现细节
3.1 网络结构设计
LingBot-Depth采用encoder-decoder架构,但在传统U-Net基础上做了关键改进:
- 多尺度特征融合:在encoder的每个下采样阶段都插入跨模态注意力模块,促进RGB和深度特征的交互
- 动态掩码预测:decoder不仅输出深度值,还预测每个位置的置信度,用于后续的后处理优化
- 轻量化设计:通过深度可分离卷积和通道剪枝,模型参数量控制在15M以内,适合端侧部署
3.2 训练技巧与参数配置
在实际训练中,以下几个配置对最终性能影响显著:
| 超参数 | 推荐值 | 作用说明 |
|---|---|---|
| 初始学习率 | 3e-4 | 使用AdamW优化器 |
| 批大小 | 32 | 需根据GPU显存调整 |
| 损失权重 λ | 0.7 | 平滑L1损失和SSIM损失的平衡系数 |
| 掩码比例 | 30%-50% | 影响模型补全能力的关键 |
训练时采用渐进式掩码策略:初期使用30%的随机掩码,随着训练进行逐步增加到50%,并引入更多基于语义的边缘掩码。
4. 应用场景与性能对比
4.1 深度补全性能
在iBims-1基准测试中,LingBot-Depth的表现令人印象深刻:
| 方法 | RMSE ↓ | δ1 ↑ | 推理时间(ms) |
|---|---|---|---|
| OMNI-DC | 0.127 | 0.891 | 25 |
| PromptDA | 0.115 | 0.902 | 32 |
| LingBot-Depth | 0.098 | 0.927 | 8 |
特别是在透明物体场景下,传统方法RMSE通常在0.2以上,而LingBot-Depth能稳定保持在0.12以下。
4.2 单目深度估计
当仅输入RGB图像时,模型依然表现出色。在NYUv2数据集上的对比:
| 方法 | Abs Rel ↓ | Sq Rel ↓ |
|---|---|---|
| DPT | 0.110 | 0.057 |
| DINOv2 | 0.095 | 0.049 |
| LingBot-Depth | 0.083 | 0.042 |
这得益于模型在预训练阶段学习到的强大跨模态表示能力。
4.3 立体匹配增强
在传统立体视觉流程中,LingBot-Depth可作为后处理模块显著提升效果:
- 先用传统方法(如SGM)计算初始视差图
- 将左图RGB和初始视差输入LingBot-Depth
- 模型输出优化后的深度图
实测表明,这种方案在Middlebury数据集上能将错误率降低约35%,同时保持实时性能。
5. 部署实践与优化建议
5.1 端侧部署方案
在Jetson系列设备上的部署经验:
- 模型量化:采用FP16量化后,模型大小从58MB减小到29MB,速度提升20%
- TensorRT优化:通过层融合和内核自动调优,推理速度可再提升30%
- 内存管理:建议预分配GPU内存池,避免动态分配带来的延迟波动
cpp复制// 典型的部署代码结构
void run_inference(cv::Mat rgb, cv::Mat depth_raw) {
// 前处理
preprocess(rgb, depth_raw);
// 创建TensorRT引擎
auto engine = create_engine("lingbot_depth.engine");
// 异步推理
engine->enqueue(buffers, stream);
// 后处理
postprocess(output_depth);
}
5.2 实际应用中的调优技巧
- 领域适配:如果应用场景特殊(如工业环境),建议用少量场景数据(约1000帧)进行微调
- 多帧融合:对于静态场景,可以融合多帧预测结果以进一步提升精度
- 异常检测:通过分析模型输出的置信度图,可以识别并过滤不可靠的预测区域
6. 常见问题与解决方案
6.1 透明物体边缘模糊
现象:玻璃杯边缘深度出现阶梯状伪影
解决方案:
- 在训练数据中增加更多薄壁透明物体的样本
- 在损失函数中增加边缘感知权重
- 后处理时使用联合双边滤波
6.2 远距离深度不准
现象:5米外的物体深度误差较大
优化方向:
- 调整训练数据的距离分布,增加远距离样本比例
- 在损失函数中使用对数尺度误差计算
- 采用分级预测策略:先预测粗略深度再局部细化
6.3 实时性不达标
排查步骤:
- 检查是否启用了TensorRT优化
- 确认输入分辨率是否过高(建议不超过640×480)
- 分析GPU利用率,可能存在内存带宽瓶颈
我在机器人项目中的实际测试表明,经过充分优化后,模型在Jetson Xavier NX上可以稳定达到30FPS的处理速度,完全满足实时性要求。
7. 扩展应用与未来方向
虽然LingBot-Depth最初为机器人导航设计,但其应用远不止于此:
- AR/VR:在移动设备上实现实时的场景三维重建
- 工业检测:精确测量反光金属零件的三维尺寸
- 智能家居:通过普通摄像头实现手势交互
从技术演进角度看,我认为下一步的发展方向包括:
- 与神经辐射场(NeRF)技术结合,实现更精细的场景建模
- 探索脉冲神经网络(SNN)实现方式,进一步降低功耗
- 开发自适应机制,使模型能在线适应新的环境特性
经过多个项目的实战检验,LingBot-Depth确实在复杂场景深度感知方面带来了质的提升。特别是在处理办公室玻璃隔断、商场镜面装饰等传统方法失效的场景时,其优势尤为明显。建议在实际部署时,可以先用少量场景数据微调模型,这样通常能获得10-15%的额外精度提升。