
1. 引言:重新思考long-CoT SFT的数据策略
在大型语言模型的监督微调(SFT)领域,特别是针对长链推理(long-CoT)任务的微调,我们长期以来被一个看似不言自明的假设所主导:更多的数据意味着更好的性能。这个假设源自预训练阶段的经验,在那里数据多样性确实是模型泛化能力的关键。然而,当我们把目光转向SFT阶段,尤其是处理需要复杂多步推理的任务时,这个假设可能需要重新审视。
最近来自纽伦堡工业大学、Mistral AI和英伟达的研究团队通过系统实验发现,在long-CoT SFT中,重复利用少量高质量数据进行多轮训练,其效果显著优于不断扩充新数据的策略。这一发现不仅挑战了行业常规做法,也为资源受限的团队提供了更高效的训练路径。本文将深入解析这项研究的关键发现,并探讨其背后的原理和实践意义。
2. 实验设计与方法论解析
2.1 研究框架与核心问题
研究团队设计了严谨的实验来回答一个核心问题:在固定的计算预算下,我们应该如何分配"数据规模"和"训练轮次"这两个关键资源?具体而言,给定相同的梯度更新次数(51,200次),是应该:
- 使用51,200个样本训练1轮?
- 使用25,600个样本训练2轮?
- 还是使用更少的样本(如3,200个)但训练更多轮次(16轮)?
这种实验设计巧妙地隔离了计算预算的影响,使我们能够纯粹比较数据策略的差异。
2.2 模型与数据集选择
研究选用了三个具有代表性的开源基座模型:
- Qwen3-4B 和 Qwen3-8B(来自阿里云)
- Olmo3-7B(来自Allen AI)
数据集方面,基于Dolci SFT 7B构建了具有严格嵌套结构的训练集:
code复制200 ⊂ 400 ⊂ 800 ⊂ 1.6k ⊂ 3.2k ⊂ 6.4k ⊂ 12.8k ⊂ 25.6k ⊂ 51.2k
这种设计确保了不同规模数据集之间的可比性,排除了数据质量差异的干扰。
2.3 评测基准与指标
评估采用了两个需要深度推理的挑战性任务:
- AIME 2024/2025:美国数学竞赛邀请赛级别的问题
- GPQA:研究生水平的综合问答
评测设置考虑了实际应用场景:
- 每个问题生成多个响应(AIME:16次,GPQA:4次)
- 最大生成长度达30k tokens,确保能容纳完整推理链
- 使用标准采样参数保证结果可比性
3. 关键实验结果与发现
3.1 重复训练的显著优势
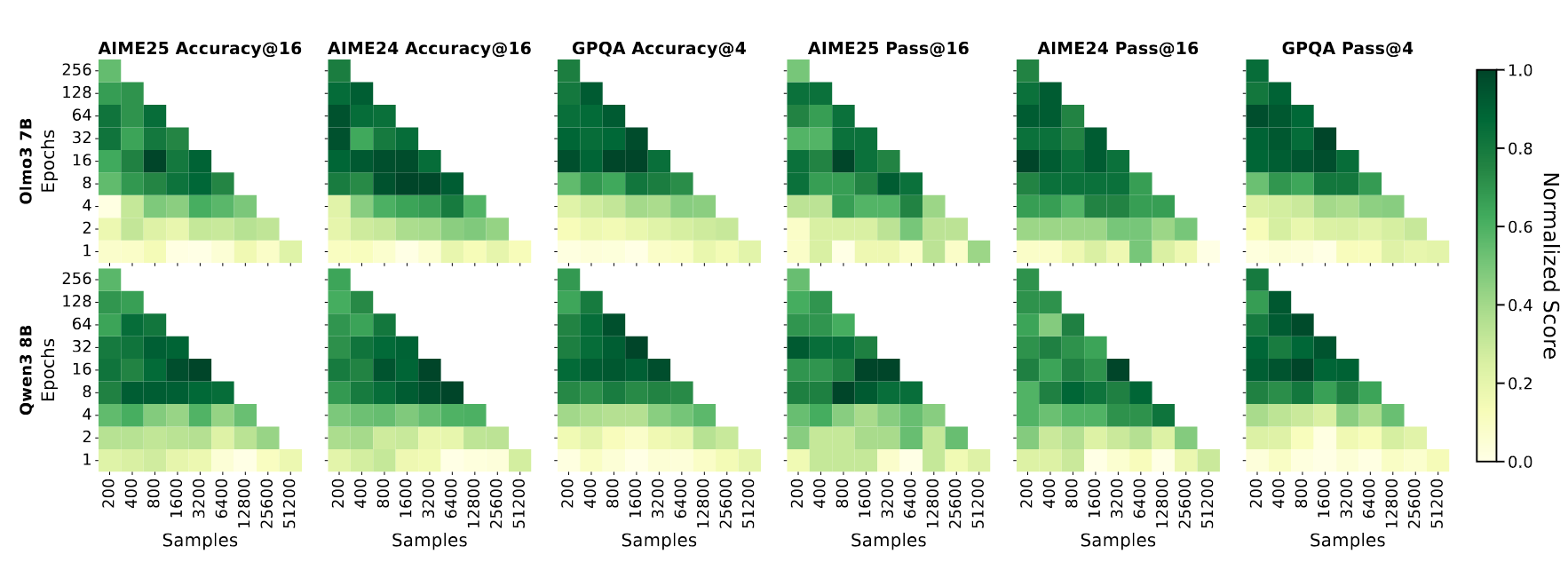
实验结果清晰地显示,在固定计算预算下,增加训练轮次(epoch)比扩大数据规模带来更显著的性能提升。以Olmo3-7B为例:
- 3.2k样本 × 16轮:性能提升12-26个百分点
- 51.2k样本 × 1轮:基准性能
这种优势在所有测试模型上都保持一致,表明这是一个跨架构、跨规模的普适现象。
3.2 训练轮次的收益曲线
深入研究epoch数量的影响,发现性能提升呈现典型的收益递减规律:
| 训练轮次 | 性能增益 | 训练时间 |
|---|---|---|
| 1→8轮 | 大幅提升 | 线性增加 |
| 8→16轮 | 明显但减缓 | 线性增加 |
| 16→32轮 | 轻微提升 | 线性增加 |
| 32+轮 | 基本饱和 | 继续增加 |
实践建议:16-32轮是大多数场景下的合理选择,超过这个范围的计算资源投入回报较低。
4. 现象背后的原理探究
4.1 Token准确率的核心作用
研究发现,模型在训练集上的token预测准确率与最终推理性能高度相关:
- 98-100%准确率:性能趋于饱和
- 低于95%准确率:仍有提升空间
这意味着token准确率可以作为可靠的训练停止信号,而传统的验证集损失在这个场景下反而会误导早期停止。
4.2 过拟合的重新解读
虽然多轮训练确实导致了典型的过拟合信号:
- 训练损失趋近于0
- 验证损失上升
- 预测熵下降
但令人惊讶的是,这些"过拟合"迹象与下游推理性能的提升并行不悖。这表明在long-CoT SFT中,模型可能更多是在学习如何有效组织和调用预训练阶段已获得的推理能力,而非从头学习新能力。
4.3 错误样本的价值
反直觉的是,在包含错误推理过程的样本上训练,有时反而能带来更好的性能提升。研究推测这是因为:
- 错误样本通常涉及更复杂的推理路径
- 模型从失败的尝试中也能学习有价值的推理模式
- 多样化的错误类型增强了模型的鲁棒性
这提示我们在数据清洗时不必过度追求"完美"样本,适度的噪声可能反而有益。
5. 实践指导与操作建议
5.1 资源分配策略
基于研究发现,建议采用以下资源分配优先级:
- 确保数据质量:精选少量(200-400)高质量long-CoT样本
- 充分重复训练:对这些样本进行16-32轮训练
- 监控token准确率:达到95-98%后收益递减
- 平衡计算预算:在固定预算内最大化epoch而非样本量
5.2 训练实施细节
具体操作时需注意:
- 学习率选择:建议基于最大数据规模的单轮训练进行初步搜索
- 批量大小:保持与常规SFT相同的设置
- 早停标准:以token准确率为主要指标,而非验证损失
- 混合策略:可考虑先多轮训练核心样本,再少量补充新数据
5.3 数据管理建议
- 保留错误样本:特别是那些展示了有趣推理路径的失败案例
- 构建难度梯度:确保数据包含不同复杂度的样本
- 记录元数据:标注样本的难度、错误类型等特征
- 动态采样:后期可对困难样本进行适当加权
6. 潜在影响与未来方向
这一发现对行业实践可能产生多方面影响:
- 降低数据门槛:小团队也能通过精心设计和充分训练获得好效果
- 改变评估方式:需要建立更适合SFT阶段的评估指标
- 优化计算分配:重新思考整个训练流程的资源分配策略
未来研究可以探索:
- 不同领域(数学、编程等)的最佳epoch差异
- 与课程学习(curriculum learning)的结合
- 动态调整训练轮次的自动化策略
在实际项目中应用这些发现时,我建议从小规模试点开始。例如先选取100-200个代表性样本,进行20轮左右的训练,观察token准确率曲线和最终性能变化,再逐步扩展到更大规模。这种渐进式方法既能验证效果,又能控制风险。