
1. 大语言模型基础解析
1.1 大语言模型的定义与核心特性
大语言模型(LLM)是当前人工智能领域最具突破性的技术之一。简单来说,它是一个通过海量文本数据训练而成的深度学习系统,能够理解和生成类人语言。这类模型通常包含数十亿甚至数万亿个参数,使其具备捕捉语言细微差别的能力。
从技术角度看,LLM的核心特性体现在三个方面:
- 规模庞大:参数量通常超过10亿,GPT-4据估计已达到100万亿参数规模
- 生成能力强:不仅能理解输入内容,还能生成连贯、符合语境的文本
- 上下文感知:通过自注意力机制捕捉长距离语义关联
提示:参数量的增加并非简单的线性提升。当模型规模超过某个临界点(约100亿参数)时,会展现出"涌现能力"——即突然获得小模型不具备的新能力,如复杂推理、代码生成等。
1.2 模型架构深度剖析
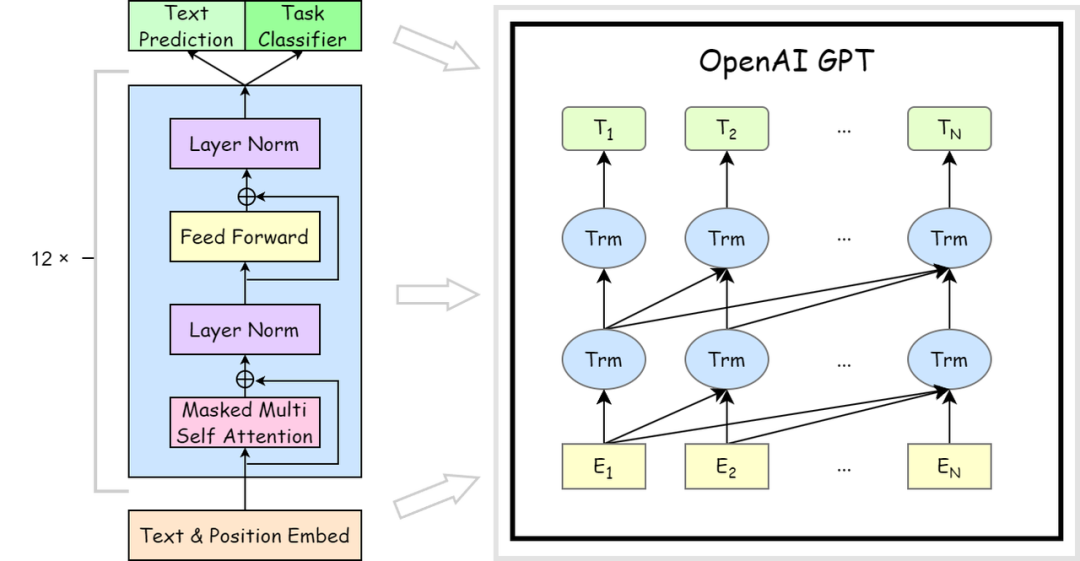
主流大模型普遍采用Transformer架构,其核心组件包括:
1.2.1 输入处理层
- 文本分词(Tokenization):将原始文本转换为模型可处理的token序列
- 词嵌入(Embedding):将token映射到高维向量空间
- 位置编码(Positional Encoding):注入序列位置信息
1.2.2 Transformer模块堆
- 多头自注意力机制:计算token间的关联权重
- 前馈神经网络:对注意力输出进行非线性变换
- 残差连接与层归一化:保障训练稳定性
1.2.3 输出生成层
- 线性投影:将隐状态映射到词表空间
- Softmax归一化:生成下一个token的概率分布
- 采样策略:控制生成多样性的技术(如top-k采样)
1.3 训练流程与关键技术
大模型的训练可分为三个阶段:
-
预训练阶段(最耗时):
- 目标:通过自监督学习构建语言理解能力
- 数据:数TB规模的互联网文本
- 硬件:数千张GPU/TPU并行训练数周至数月
- 典型损失函数:交叉熵(预测被mask的token)
-
微调阶段:
- 目标:使模型行为符合人类偏好
- 方法:监督微调(SFT)+人类反馈强化学习(RLHF)
- 关键:设计合理的奖励模型(Reward Model)
-
推理优化:
- 量化:降低模型权重精度以减少内存占用
- 剪枝:移除冗余的神经元连接
- 蒸馏:训练小模型模仿大模型行为
2. 大模型的局限性及RAG的诞生
2.1 大模型的五大核心挑战
尽管能力强大,当前LLM仍存在明显局限:
-
知识时效性问题:
- 训练数据存在时间滞后(如GPT-4数据截止2023年)
- 无法自动获取训练后的新知识
-
领域专业性不足:
- 对垂直领域(如医疗、法律)理解深度有限
- 专业术语和概念可能被错误使用
-
幻觉现象:
- 生成看似合理但实际错误的内容
- 包括事实性错误(Factual Hallucination)和逻辑矛盾(Logical Hallucination)
-
推理能力局限:
- 多步推理容易出现错误累积
- 数学计算等精确任务表现不稳定
-
上下文长度限制:
- 即使支持长上下文(如128k token),仍可能丢失中间信息
- 处理超长文档时效率显著下降
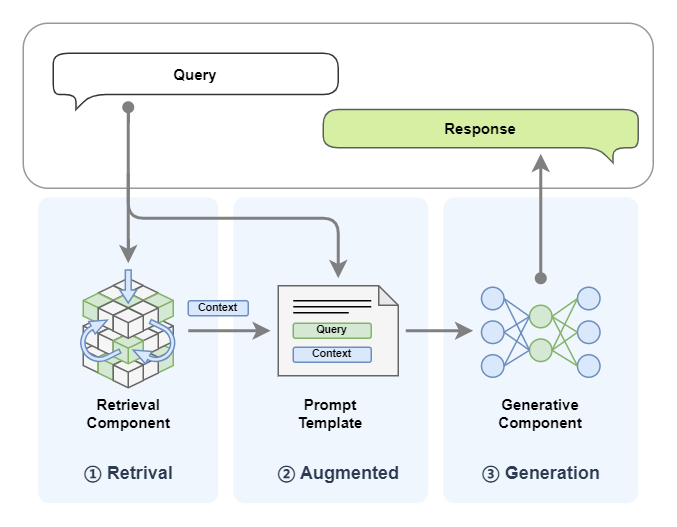
2.2 RAG技术原理详解
检索增强生成(RAG)通过引入外部知识库,有效缓解上述问题。其核心思想可类比人类专家的研究过程:
- 问题分析:理解用户查询的深层意图
- 文献检索:从可靠来源查找相关信息
- 综合回答:结合已有知识和新证据形成结论
2.2.1 RAG技术架构
典型RAG系统包含三个核心模块:
-
检索器(Retriever):
- 将用户查询转换为向量表示
- 从向量数据库检索相关文档片段
- 常用算法:BM25(稀疏检索)、DPR(密集检索)
-
重排序器(Reranker):
- 对初步检索结果进行精细排序
- 考虑语义相关性和事实准确性
- 典型模型:Cross-Encoder架构的BERT变体
-
生成器(Generator):
- 将检索结果作为额外上下文
- 生成最终回答时标注引用来源
- 可配置的温度参数控制创造性
2.2.2 知识库构建关键步骤
构建高质量的检索知识库需要以下流程:
-
文档采集:
- 来源:企业内部文档、行业报告、学术论文等
- 格式处理:PDF/Word/HTML等异构数据统一解析
-
文本预处理:
- 清洗:去除广告、页眉页脚等噪声
- 分块:按语义将长文档分割为适当片段(通常256-512token)
- 元数据标注:添加来源、更新时间等关键信息
-
向量化编码:
- 使用嵌入模型(如BGE、OpenAI embeddings)生成向量
- 维度通常为768或1024维
- 考虑多语言支持(如paraphrase-multilingual模型)
-
索引构建:
- 选择向量数据库:FAISS(本地)、Pinecone(云端)等
- 优化索引结构:IVF、HNSW等算法平衡速度与精度
- 支持增量更新:确保新文档能实时加入检索池
3. RAG进阶架构与优化策略
3.1 RAG的六种高级变体
3.1.1 检索-重排序RAG
在基础RAG上增加重排序环节,使用更强大的交叉编码器对初步检索结果进行精细评分,显著提升上下文质量。实践表明,重排序可使最终答案准确率提升15-20%。
3.1.2 多模态RAG
突破文本限制,支持图像、视频等多媒体检索。关键技术包括:
- CLIP等跨模态嵌入模型
- 多模态Transformer架构
- 混合检索策略(文本+视觉特征)
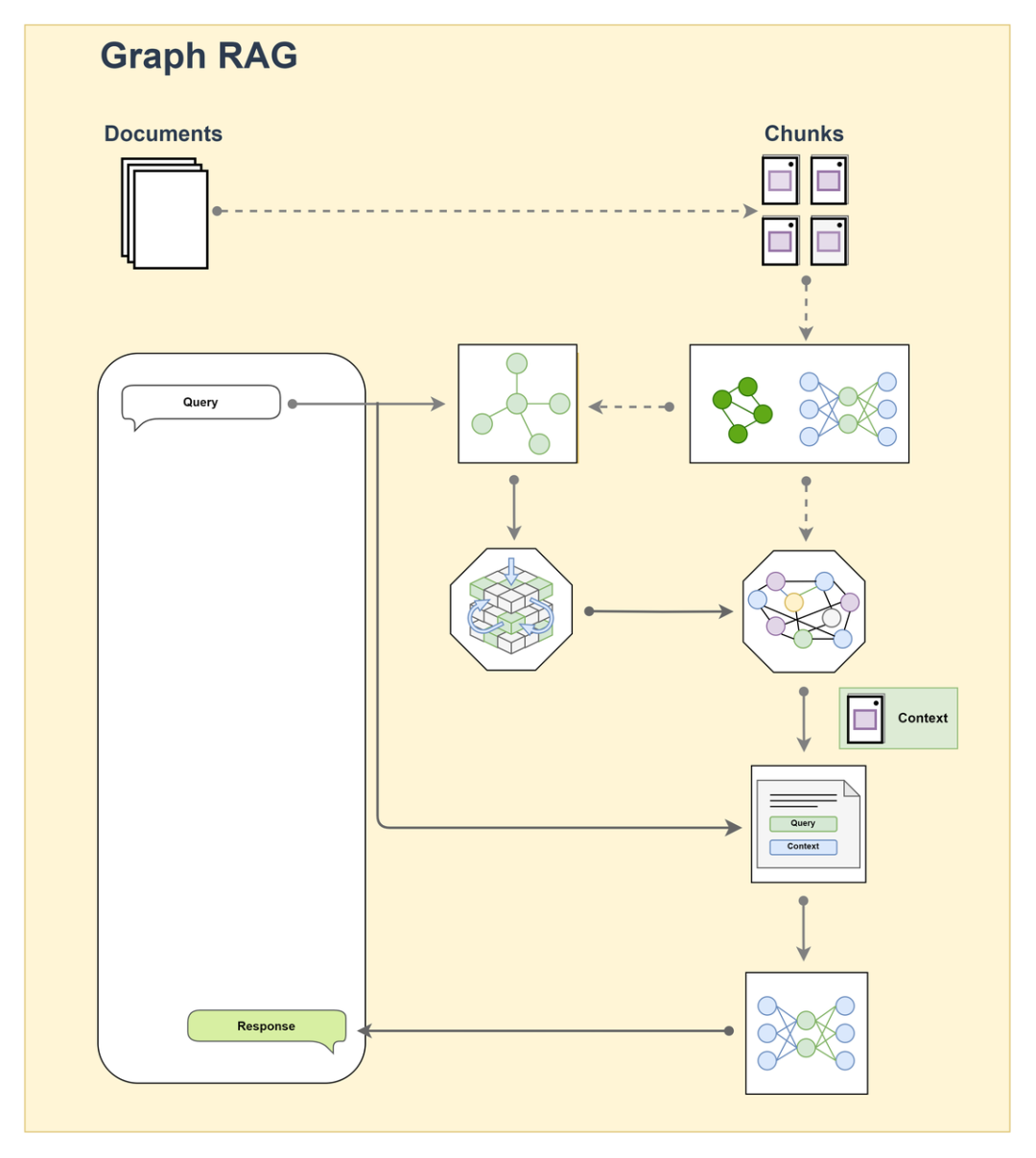
3.1.3 图RAG
将知识组织为图结构,实现关系推理。典型实现方式:
- 从文档提取实体和关系构建知识图谱
- 使用图遍历算法进行多跳检索
- 将子图转换为文本提示
3.1.4 混合RAG
结合关键词检索(BM25)和向量检索的优势:
- 关键词检索保证召回率
- 向量检索提升语义匹配精度
- 结果融合算法(如RRF)平衡两者
3.1.5 自主代理RAG
引入AI代理动态控制流程:
- 查询理解:分析用户真实意图
- 路由决策:选择最合适的检索策略
- 结果验证:检查生成内容的准确性
3.1.6 多代理RAG
不同代理分工协作的复杂系统:
- 检索代理:负责知识查找
- 验证代理:核查事实准确性
- 生成代理:组织最终回答
- 协调代理:管理任务流程
3.2 性能优化实战技巧
3.2.1 检索优化
- 分块策略:尝试不同大小的文本块(如128/256/512token)
- 重叠设置:相邻块间保留10-15%内容重叠避免信息割裂
- 元数据过滤:利用文档类型、更新时间等字段缩小检索范围
3.2.2 提示工程
- 上下文组织:将最关键信息放在提示开头
- 指令设计:明确要求模型"基于以下上下文回答"
- 引用格式:要求标注具体来源便于验证
3.2.3 评估指标
建立全面的评估体系:
-
检索阶段:
- 召回率@K:前K个结果中包含正确答案的比例
- 平均排名:正确答案在结果中的平均位置
-
生成阶段:
- 事实准确性:人工评估内容正确性
- 引用准确性:验证引用是否支持生成内容
- 流畅度:语言自然程度评分
4. RAG系统实现指南
4.1 技术选型建议
4.1.1 开源工具链
-
嵌入模型:
- BGE(北京智源)
- E5(微软)
- GTE(阿里云)
-
向量数据库:
- Milvus:功能全面的开源选择
- Weaviate:支持混合检索
- Qdrant:性能优异的Rust实现
-
框架支持:
- LangChain:快速原型开发
- LlamaIndex:专业文档处理
- Haystack:生产级流水线
4.1.2 商业解决方案
-
全托管服务:
- Azure AI Search
- AWS Kendra
- Google Vertex AI
-
API服务:
- OpenAI的Assistants API
- Anthropic的Claude with Retrieval
4.2 典型实现代码示例
以下是使用Python构建基础RAG系统的核心代码框架:
python复制# 1. 文档处理与索引构建
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import FAISS
# 加载文档
loader = DirectoryLoader('./docs', glob="**/*.pdf")
documents = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=64
)
chunks = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-base-en")
vectorstore = FAISS.from_documents(chunks, embeddings)
vectorstore.save_local("faiss_index")
# 2. 检索增强生成
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# 初始化LLM
llm = OpenAI(temperature=0)
# 创建检索链
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
# 执行查询
query = "解释RAG技术如何解决大模型的幻觉问题?"
result = qa_chain({"query": query})
print(result["result"])
print("来源文档:", result["source_documents"])
4.3 企业级部署考量
4.3.1 安全与合规
- 访问控制:基于角色的知识库访问权限
- 数据脱敏:自动识别并处理敏感信息
- 审计日志:记录所有检索和生成操作
4.3.2 性能优化
- 缓存策略:对常见查询结果缓存
- 异步处理:耗时操作异步执行
- 负载均衡:多副本部署应对高并发
4.3.3 监控体系
- 质量监控:定期抽样评估回答准确性
- 性能监控:跟踪响应时间和资源使用
- 异常检测:自动识别异常查询模式
5. 前沿发展与趋势展望
5.1 新兴研究方向
- 动态RAG:实时更新知识库的流式处理架构
- 自优化RAG:通过用户反馈自动调整检索策略
- 多模态推理:结合文本、图像、音频的复合检索
5.2 技术融合趋势
- RAG+Fine-tuning:先用RAG收集数据再微调模型
- RAG+Agent:赋予AI自主检索决策能力
- RAG+边缘计算:在终端设备实现轻量级检索
5.3 行业应用场景
-
医疗健康:
- 结合医学文献的辅助诊断
- 个性化健康建议生成
-
金融服务:
- 实时市场分析报告
- 合规审查辅助
-
教育培训:
- 个性化学习内容推荐
- 自动生成测验题目
-
客户服务:
- 基于知识库的智能问答
- 对话式产品推荐
实践建议:从具体业务场景切入,先构建最小可行产品(MVP),再逐步扩展功能。例如,可以先在内部知识管理系统中实施RAG,验证效果后再推向客户-facing应用。
在实际部署RAG系统时,有几个关键经验值得注意:
- 知识库质量直接影响最终效果,需要建立严格的文档审核流程
- 不同的业务场景需要不同的检索策略,没有放之四海而皆准的方案
- 用户查询的意图识别往往比技术实现更具挑战性
- 持续监控和迭代优化比一次性完美设计更重要