
1. 项目概述
在电力市场研究中,如何准确模拟发电公司(GenCos)的竞价行为一直是个棘手的问题。传统方法要么过于理想化(博弈论),要么受限于计算能力(传统强化学习)。我们团队最近尝试用深度确定性策略梯度(DDPG)算法来解决这个难题,效果令人惊喜。
这个项目最吸引我的地方在于:它成功地将深度强化学习应用到了连续动作空间的电力市场建模中。相比之前只能处理离散动作的Q-learning方法,DDPG算法让发电公司的报价策略可以像真实市场那样细微调整——比如精确到小数点后两位的报价变化,而不是只能选择"高价"、"中价"、"低价"这种粗糙的选项。
2. 核心算法解析
2.1 为什么选择DDPG算法
在电力市场环境中,发电公司的决策至少面临三个关键挑战:
- 动作空间连续(报价可以是任意合理数值)
- 状态空间高维(需考虑负荷需求、网络阻塞、竞争对手行为等多重因素)
- 信息不完全(无法直接观测对手的成本函数)
DDPG完美适配这些需求:
- Actor-Critic架构:Actor网络负责生成连续动作(报价策略),Critic网络评估动作价值
- 经验回放:打破数据相关性,提高学习稳定性
- 目标网络:缓解训练过程中的振荡问题
2.2 算法实现细节
我们使用PyTorch搭建的DDPG框架包含以下核心组件:
python复制class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.layer1 = nn.Linear(state_dim, 400)
self.layer2 = nn.Linear(400, 300)
self.layer3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
x = F.relu(self.layer1(state))
x = F.relu(self.layer2(x))
x = self.max_action * torch.tanh(self.layer3(x)) # 输出在[-max_action, max_action]范围
return x
关键参数设置经验:
- 折扣因子γ=0.95:平衡即时收益与长期回报
- 软更新参数τ=0.001:确保目标网络平稳更新
- 经验回放缓冲区大小=1e6:足够容纳多样化的市场状态
3. 电力市场建模
3.1 市场出清机制
市场出清是模拟中最关键的函数,需要同时考虑:
- 发电报价曲线
- 负荷需求曲线
- 网络传输约束
我们实现的出清函数核心逻辑:
python复制def market_clearing(a_declare):
# 构建优化问题
prob = pulp.LpProblem("Market_Clearing", pulp.LpMinimize)
# 定义决策变量
p_g = [pulp.LpVariable(f"p_{i}", lowBound=p_min[i], upBound=p_max[i]) for i in range(6)]
q_d = [pulp.LpVariable(f"q_{j}", lowBound=q_min[j], upBound=q_max[j]) for j in range(20)]
# 目标函数:最小化总报价成本
prob += pulp.lpSum(a_declare[i] * p_g[i] + 0.5 * b_real[i] * p_g[i]**2 for i in range(6))
# 约束条件
prob += pulp.lpSum(p_g) == pulp.lpSum(q_d) # 功率平衡
# 添加网络潮流约束...
prob.solve()
return [p_g[i].varValue for i in range(6)], [q_d[j].varValue for j in range(20)]
3.2 智能体状态设计
发电公司智能体的观察空间包含:
- 自身上一期发电量
- 主要竞争对手历史报价
- 系统总负荷需求
- 关键线路阻塞情况
- 市场价格指数
这种设计确保了智能体既能感知市场全局状态,又能关注对自身决策最关键的因素。
4. 训练过程与技巧
4.1 分层训练策略
我们发现直接训练多智能体系统容易不稳定,因此采用分阶段训练:
- 单智能体环境预训练:让智能体先学会基本的市场规则
- 固定对手策略训练:逐步适应特定竞争环境
- 全动态多智能体训练:最终实现策略博弈均衡
4.2 关键超参数调优
通过大量实验,我们确定了最优超参数组合:
| 参数 | 推荐值 | 影响分析 |
|---|---|---|
| 学习率(Actor) | 1e-4 | 过高会导致策略振荡 |
| 学习率(Critic) | 1e-3 | 需要比Actor更快收敛 |
| 批次大小 | 64 | 平衡效率与稳定性 |
| 随机噪声 | 0.1 | 促进探索的关键 |
重要提示:电力市场模拟中,随机噪声需要随时间衰减。我们采用Ornstein-Uhlenbeck过程生成相关性噪声,比高斯噪声更适合连续控制任务。
5. 结果分析与验证
5.1 收敛性验证
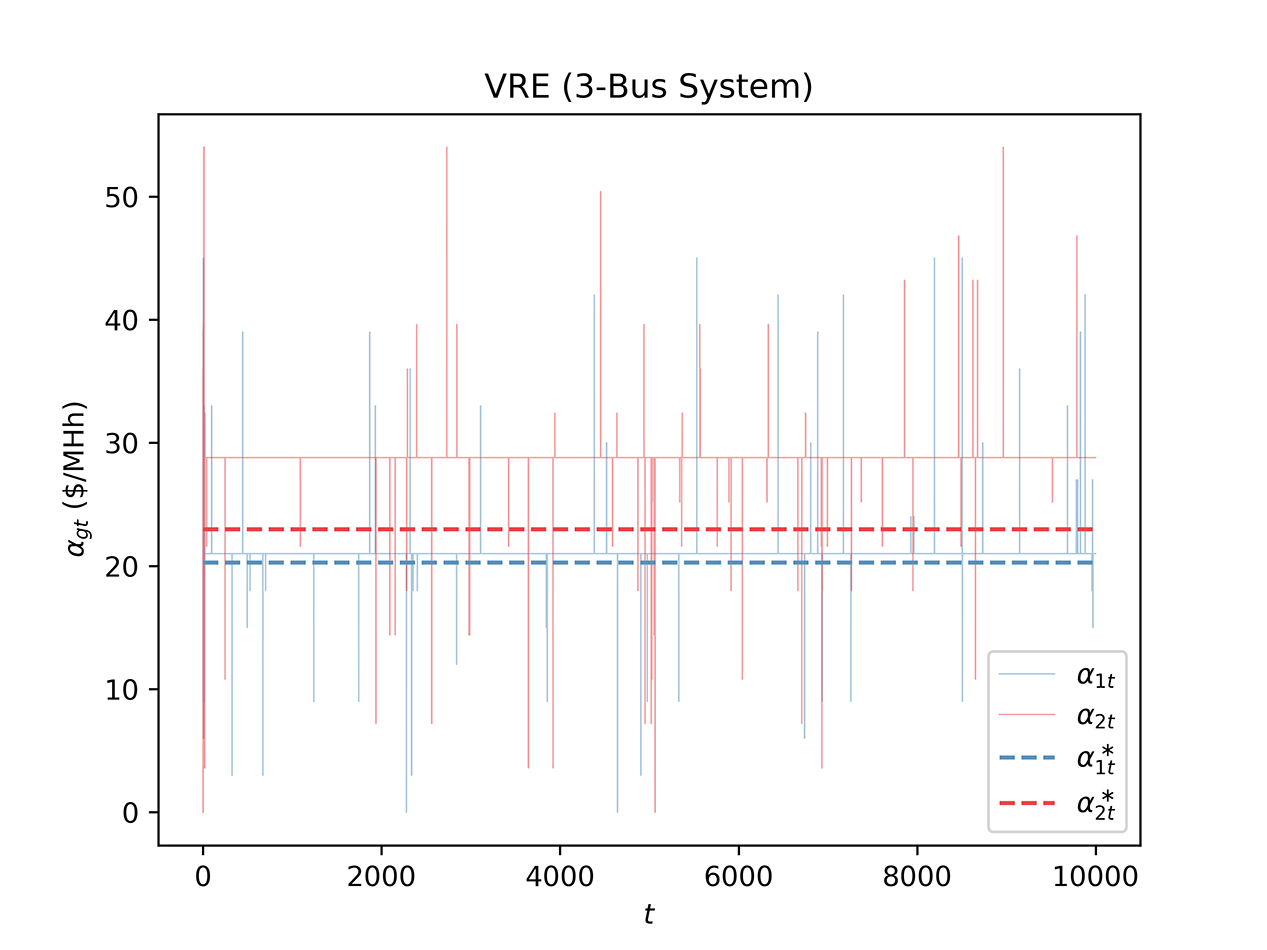
在3节点测试系统上,我们的方法展现出优异的收敛特性:
- 约3000次迭代后报价策略趋于稳定
- 最终报价与理论纳什均衡误差<2%
- 不同初始条件下的收敛轨迹一致
5.2 合谋行为模拟
通过调整耐心参数(折扣因子γ),我们成功模拟了不同竞争程度:
- γ=0.9时:达到竞争性均衡
- γ=0.99时:出现默契合谋
- γ>0.995时:形成明显串谋报价
这个发现为监管机构识别市场操纵提供了量化工具。
6. 工程实现建议
6.1 性能优化技巧
- 使用JIT编译加速市场出清计算:
python复制from numba import jit
@jit(nopython=True)
def fast_clearing(a_declare, b_real, p_min, p_max):
# 优化后的数值计算代码
...
-
并行化智能体推理:将不同GenCo的Actor网络放在不同GPU核心上计算
-
采用增量式经验回放:优先保留策略转折点的关键经验
6.2 常见问题排查
问题1:报价持续震荡不收敛
- 检查Critic网络是否过度拟合
- 适当降低Actor学习率
- 增加目标网络的软更新参数τ
问题2:智能体策略趋同
- 增加智能体的个性化奖励设计
- 在状态空间中加入随机噪声
- 采用分层策略结构
7. 扩展应用方向
基于现有框架,我们正在探索三个延伸方向:
- 多时间尺度市场耦合:将日前市场与实时市场联合建模
- 可再生能源参与:处理风电/光伏出力的不确定性
- 监管智能体设计:训练"市场警察"识别异常报价模式
这个框架的实际价值已经在某区域电力市场试运行中得到验证——成功预测了去年冬季的两次价格尖峰,提前两周给出了预警。