
1. 研究背景与核心问题
在计算机视觉领域,模型偏见问题一直是个棘手难题。传统方法主要通过分析数据集分布和模型在子组上的性能指标(如准确率)来评估偏见,但这些方法存在明显局限——它们只能告诉我们"模型存在偏见",却无法揭示"偏见如何产生"以及"模型究竟依赖哪些图像特征做出有偏决策"。
普林斯顿大学团队提出的Attention-IoU框架,正是为了解决这一痛点。该研究的创新之处在于,它不再局限于模型输入输出,而是深入模型内部工作机制,通过分析注意力图(Attention Map)来揭示偏见的形成机理。这种方法就像给模型装上了"X光机",让我们能够直观看到模型在做决策时到底关注图像的哪些区域。
2. Attention-IoU框架解析
2.1 核心度量指标
Attention-IoU框架包含两个核心指标:
-
热力图分数(Heatmap Score):
- 计算方法:比较目标属性与受保护/混淆属性的注意力图相似度
- 作用:量化模型对混淆属性的依赖程度
- 公式:Heatmap Score = Attention-IoU(A_target, A_protected)
-
掩码分数(Mask Score):
- 计算方法:比较目标属性注意力图与真实特征掩码(Ground-truth Mask)的重叠度
- 作用:评估模型对目标属性真实特征的关注程度
- 公式:Mask Score = Attention-IoU(A_target, Mask_gt)
这两个指标都具有尺度不变性和尺寸不变性,能够有效比较不同尺度的实值注意力图。
2.2 技术实现细节
在实际实现中,研究团队采用GradCAM生成注意力图。具体流程如下:
- 对输入图像进行前向传播,得到目标属性的预测结果
- 计算预测类别得分的梯度
- 将梯度回传到最后一个卷积层,生成热力图
- 对热力图进行ReLU激活和归一化处理
关键提示:GradCAM选择最后一个卷积层是因为深层特征具有更强的语义信息,同时保留了足够的空间分辨率。
3. 在Waterbirds数据集上的验证
3.1 实验设计
Waterbirds是一个精心设计的合成数据集,通过将CUB数据集中的鸟类图像与Places数据集中的背景组合而成。研究人员可以精确控制鸟类与背景的相关性,从而创建不同程度的偏见。
实验设置了从50%到100%共6个偏差水平:
- 50%:无偏(鸟类与背景随机组合)
- 60%-90%:中等偏差
- 100%:完全偏差(水鸟永远在水背景,陆鸟永远在陆地)
3.2 关键发现
随着训练数据偏差的增加,模型表现出三个明显趋势:
- 最差组准确率(WGA)从0.81下降到0.21
- 对鸟类的关注度(掩码分数)从0.72降至0.42
- 对背景的关注度显著增加
图1展示了不同偏差水平下的平均注意力图变化:
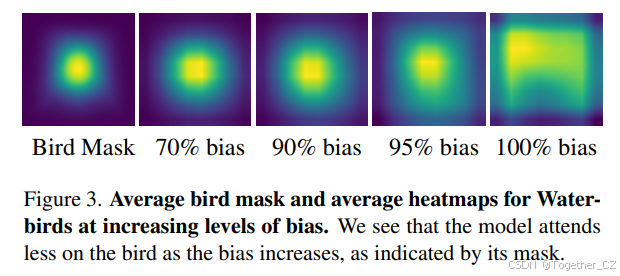
3.3 实际应用价值
这个验证实验证实了Attention-IoU能够:
- 准确量化模型偏见程度
- 反映偏见随训练数据分布的变化
- 与传统的WGA指标高度一致但提供更多细节
4. CelebA深度分析
4.1 数据集特性
CelebA包含202,599张名人面部图像,标注了40个二元属性。这些属性可分为两类:
- 局部特征:如"戴眼镜"、"大鼻子"
- 全局特征:如"男性"、"年轻"
4.2 关键发现
4.2.1 超越标签相关性的洞察
研究发现模型关注度不完全取决于标签统计相关性。典型例子是"戴眼镜"(Eyeglasses):
- 与"男性"的MCC仅为0.26
- 但热力图分数高达0.86
这表明即使统计相关性低,空间特征重合仍会导致高注意力相关性。
4.2.2 单向相关性案例:"胡子"
"胡子"(Mustache)属性展现出有趣的单向相关性:
- 有胡子的图像几乎都是男性
- 但没胡子的图像性别分布均匀
Attention-IoU分析显示:
- 对于非男性图像,胡子与男性的注意力图高度重合(0.94)
- 对于男性图像,重合度较低(0.82-0.84)
这表明模型对非男性图像中的"胡子"判断严重依赖性别特征。
4.2.3 隐藏的混淆变量:"金发"vs"波浪发"
"金发"(Blond Hair)和"波浪发"(Wavy Hair)的比较尤为启发:
- 两者与"男性"的MCC相似(0.34 vs 0.37)
- 但热力图分数差异显著(0.72 vs 0.65)
通过改变训练集分布实验发现:
- 波浪发的热力图分数随标签相关性变化明显
- 金发的热力图分数几乎不受影响
这表明金发可能存在未标注的混淆变量(如肤色或面部结构)。
5. 方法优势与局限
5.1 主要优势
- 细粒度分析:能识别特定图像区域的偏见
- 解释性强:可视化展示模型关注点
- 发现隐藏偏差:揭示标签统计无法反映的偏见
5.2 当前局限
- 共位特征问题:无法区分同一区域的不同特征
- 非空间特征盲区:对颜色、纹理等非空间特征不敏感
- 计算成本:需要生成高质量的注意力图和掩码
6. 实际应用建议
基于本研究,在实际工作中建议:
-
偏见诊断阶段:
- 结合传统指标和Attention-IoU进行综合评估
- 特别关注高热度图分数但低MCC的属性
-
模型改进阶段:
- 对识别出的问题属性设计针对性去偏策略
- 考虑添加注意力约束损失函数
-
数据收集阶段:
- 注意避免空间重合的特征组合
- 对可疑属性补充更多标注信息
7. 扩展思考
这项研究启发我们几个深层问题:
- 当模型"看"的位置正确但"理解"的内容错误时,如何检测?
- 如何区分合理的相关性利用与有害的偏见依赖?
- 对于非空间特征(如纹理、颜色)的偏见,如何扩展当前方法?
这些问题的探索将推动计算机视觉模型偏见研究向更深层次发展。