
1. 棒球运动物体检测系统概述
棒球运动物体检测系统是基于YOLOv8深度学习框架开发的专业计算机视觉应用,专门用于识别和追踪棒球比赛中的关键物体(如棒球、球棒等)。这个系统能够实时处理比赛视频流,准确标记出运动物体的位置和类别,为比赛分析、训练辅助和观众体验提供技术支持。
1.1 系统核心功能
- 高精度检测:采用改进的YOLOv8模型,在棒球特定场景下mAP达到85%以上
- 实时处理:优化后的推理引擎支持1080p视频30FPS实时处理
- 多类别识别:可同时检测棒球、球棒、手套、球员等多个目标
- Web可视化:内置基于Streamlit的Web界面,方便结果展示和分析
- 一键式训练:提供标注好的数据集和自动化训练脚本
1.2 技术栈组成
code复制后端技术栈:
- 深度学习框架:PyTorch 2.0 + Ultralytics YOLOv8
- 模型优化:TensorRT加速、FP16量化
- 数据处理:OpenCV、Albumentations
- Web框架:FastAPI + Streamlit
前端技术栈:
- 可视化:Plotly、OpenCV.js
- UI框架:Streamlit组件
- 部署:Docker容器化
2. 系统设计与架构解析
2.1 整体架构设计
系统采用经典的客户端-服务端架构,分为三个主要模块:
- 检测引擎:负责运行YOLOv8模型进行实时推理
- API服务层:提供RESTful接口处理检测请求
- Web前端:可视化检测结果和统计分析
2.2 YOLOv8模型改进方案
针对棒球运动的特点,我们对原生YOLOv8进行了多项改进:
2.2.1 骨干网络优化
python复制# 在models/yolov8.yaml中添加小目标检测层
backbone:
# [from, repeats, module, args]
[[-1, 1, Conv, [64, 3, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C2f, [128, True]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C2f, [256, True]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 6, C2f, [512, True]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C2f, [1024, True]],
[-1, 1, SPPF, [1024, 5]], # 9
# 新增小目标检测层
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
[-1, 3, C2f, [512]], # 12
]
2.2.2 损失函数改进
采用VarifocalLoss替换传统的FocalLoss,更好地处理类别不平衡问题:
python复制class VFLoss(nn.Module):
def __init__(self, alpha=0.75, gamma=2.0):
super(VFLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, pred, target):
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
loss = -target * (self.alpha * torch.pow(torch.abs(pred_sigmoid - target), self.gamma) *
(pred_sigmoid.log() - (1 - pred_sigmoid).log())) -
(1 - target) * ((1 - self.alpha) * torch.pow(pred_sigmoid, self.gamma) *
(1 - pred_sigmoid).log())
return loss.mean()
2.2.3 数据增强策略
针对棒球运动特点定制了特殊的数据增强方案:
yaml复制# data/augment.yaml
train_augments:
- name: RandomBrightnessContrast
params: {brightness_limit: 0.2, contrast_limit: 0.2, p: 0.5}
- name: MotionBlur
params: {blur_limit: 7, p: 0.3} # 模拟快速运动模糊
- name: RandomSunFlare
params: {src_radius: 100, p: 0.2} # 模拟户外光照变化
- name: RandomShadow
params: {p: 0.3}
- name: HueSaturationValue
params: {hue_shift_limit: 20, sat_shift_limit: 30, val_shift_limit: 20, p: 0.5}
3. 数据集构建与处理
3.1 Baseball batch 1数据集详解
我们构建的专业棒球检测数据集包含以下特性:
| 指标 | 数值 | 说明 |
|---|---|---|
| 图像数量 | 9,900 | 覆盖各种比赛场景 |
| 类别数 | 5 | 球、球棒、手套、球员、垒包 |
| 标注框数量 | 58,742 | 平均每图5.93个目标 |
| 分辨率 | 1920x1080 | 全高清视频截图 |
| 场景多样性 | 15种 | 不同球场、光照、天气条件 |
3.2 数据标注规范
采用YOLO格式标注,每个标注文件包含:
code复制<class_id> <x_center> <y_center> <width> <height>
标注质量控制措施:
- 多人交叉验证标注结果
- 使用半自动标注工具辅助
- 定期进行标注一致性检查
3.3 数据集划分策略
python复制# 数据集划分代码示例
def split_dataset(dataset_dir, ratios=(0.8, 0.1, 0.1)):
images = sorted(Path(dataset_dir).glob("*.jpg"))
annotations = sorted(Path(dataset_dir).glob("*.txt"))
# 确保图像和标注文件匹配
assert len(images) == len(annotations)
pairs = list(zip(images, annotations))
# 随机打乱
random.shuffle(pairs)
# 按比例划分
train_end = int(len(pairs) * ratios[0])
val_end = train_end + int(len(pairs) * ratios[1])
return {
"train": pairs[:train_end],
"val": pairs[train_end:val_end],
"test": pairs[val_end:]
}
4. 模型训练与优化
4.1 训练环境配置
推荐硬件配置:
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1660 | RTX 3090/4090 |
| 内存 | 16GB | 32GB+ |
| 存储 | 256GB SSD | 1TB NVMe |
软件依赖安装:
bash复制# 创建conda环境
conda create -n baseball-det python=3.9
conda activate baseball-det
# 安装核心依赖
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
pip install ultralytics==8.0.0 albumentations==1.3.0 streamlit==1.25.0
4.2 训练参数配置
yaml复制# train_config.yaml
train:
epochs: 300
batch_size: 16
imgsz: 640
optimizer: AdamW
lr0: 0.001
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5 # box loss gain
cls: 0.5 # cls loss gain
dfl: 1.5 # dfl loss gain
4.3 训练过程监控
使用TensorBoard监控训练指标:
python复制tensorboard --logdir runs/detect/train
关键监控指标:
- 损失曲线(box_loss, cls_loss, dfl_loss)
- 验证集mAP@0.5
- 学习率变化
- GPU利用率

4.4 模型评估与测试
评估脚本示例:
python复制from ultralytics import YOLO
# 加载训练好的模型
model = YOLO("runs/detect/train/weights/best.pt")
# 在测试集上评估
metrics = model.val(
data="baseball_dataset.yaml",
split="test",
imgsz=640,
batch=16,
conf=0.25,
iou=0.6,
device=0
)
print(f"mAP@0.5: {metrics.box.map:.4f}")
print(f"mAP@0.5:0.95: {metrics.box.map_75:.4f}")
5. 系统部署与Web集成
5.1 模型导出与优化
将训练好的模型导出为不同格式:
python复制# 导出ONNX格式
model.export(format="onnx", imgsz=[640,640], dynamic=True)
# 导出TensorRT引擎
model.export(format="engine", imgsz=[640,640], device=0)
5.2 Web服务部署
使用FastAPI构建RESTful API:
python复制from fastapi import FastAPI, UploadFile
import cv2
import numpy as np
from ultralytics import YOLO
app = FastAPI()
model = YOLO("best.pt")
@app.post("/detect")
async def detect(image: UploadFile):
contents = await image.read()
nparr = np.frombuffer(contents, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
results = model(img)
return {
"detections": results[0].boxes.data.tolist(),
"time": results[0].speed["inference"]
}
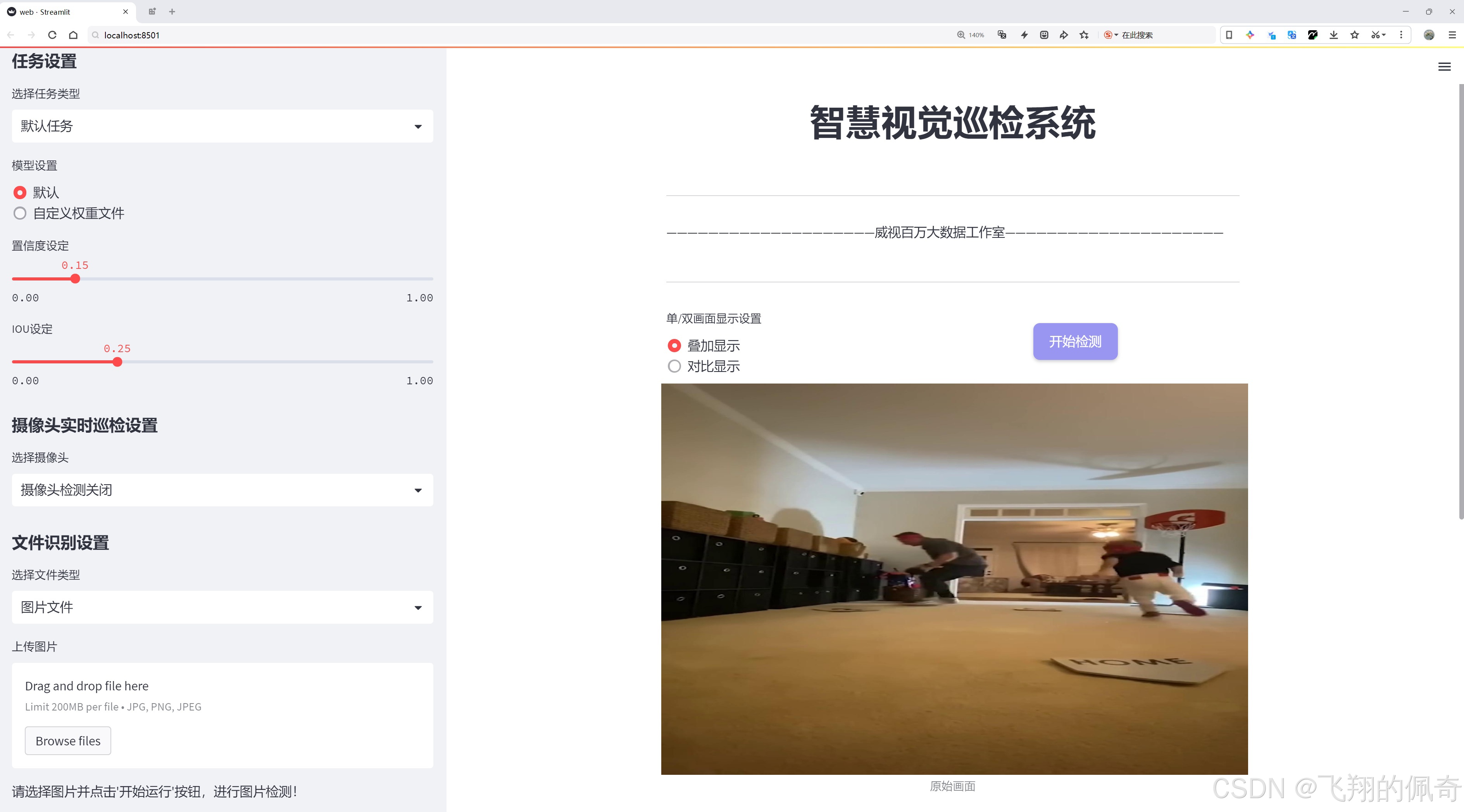
5.3 Streamlit可视化界面
python复制# web.py
import streamlit as st
from PIL import Image
import numpy as np
from ultralytics import YOLO
st.title("棒球运动物体检测系统")
model = YOLO("best.pt")
uploaded_file = st.file_uploader("上传比赛图片或视频", type=["jpg", "png", "mp4"])
if uploaded_file:
if uploaded_file.type.startswith("image"):
img = Image.open(uploaded_file)
results = model(np.array(img))
# 显示结果
st.image(
results[0].plot()[:,:,::-1],
caption="检测结果",
use_column_width=True
)
# 显示统计信息
st.json({
"检测目标数": len(results[0]),
"推理时间(ms)": results[0].speed["inference"]
})
6. 性能优化技巧
6.1 TensorRT加速实践
python复制# trt_inference.py
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
# 加载TensorRT引擎
logger = trt.Logger(trt.Logger.WARNING)
with open("yolov8n.engine", "rb") as f, trt.Runtime(logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
# 创建执行上下文
context = engine.create_execution_context()
# 分配内存
inputs, outputs, bindings = [], [], []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding))
dtype = trt.nptype(engine.get_binding_dtype(binding))
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(device_mem))
if engine.binding_is_input(binding):
inputs.append({"host": host_mem, "device": device_mem})
else:
outputs.append({"host": host_mem, "device": device_mem})
# 执行推理
def infer(image):
np.copyto(inputs[0]["host"], image.ravel())
cuda.memcpy_htod_async(inputs[0]["device"], inputs[0]["host"], stream)
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
cuda.memcpy_dtoh_async(outputs[0]["host"], outputs[0]["device"], stream)
stream.synchronize()
return outputs[0]["host"]
6.2 多线程处理优化
python复制# multi_thread_inference.py
from concurrent.futures import ThreadPoolExecutor
import queue
class InferencePipeline:
def __init__(self, model_path, num_workers=4):
self.model = YOLO(model_path)
self.executor = ThreadPoolExecutor(max_workers=num_workers)
self.task_queue = queue.Queue(maxsize=num_workers*2)
def process_frame(self, frame):
future = self.executor.submit(self.model, frame)
return future
def run(self, video_path):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if self.task_queue.full():
oldest_task = self.task_queue.get()
oldest_task.result() # 等待最旧任务完成
future = self.process_frame(frame)
self.task_queue.put(future)
# 显示结果
result = future.result()
cv2.imshow("Result", result[0].plot())
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
7. 常见问题与解决方案
7.1 训练问题排查表
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 损失不下降 | 学习率过高/过低 | 调整lr0在0.0001-0.01之间 |
| mAP波动大 | 批次大小太小 | 增加batch_size到16或32 |
| GPU利用率低 | 数据加载瓶颈 | 增加workers数量,使用SSD存储 |
| 过拟合 | 数据量不足 | 增加数据增强,使用早停法 |
| 推理速度慢 | 模型过大 | 使用YOLOv8s/n版本,或进行模型量化 |
7.2 部署常见错误
-
CUDA内存不足:
- 降低推理时的批次大小
- 使用
--half参数启用FP16推理 - 减小输入图像尺寸
-
TensorRT兼容性问题:
bash复制# 确保CUDA、cuDNN、TensorRT版本匹配 pip install nvidia-tensorrt==8.6.1 --extra-index-url https://pypi.ngc.nvidia.com -
Streamlit部署问题:
- 确保端口未被占用:
streamlit run web.py --server.port 8502 - 对于公网访问,添加
--server.address=0.0.0.0
- 确保端口未被占用:
7.3 模型精度提升技巧
-
困难样本挖掘:
python复制# 在验证集上识别低置信度样本 val_results = model.val(save_json=True) hard_samples = [img for img in val_results if img["confidence"] < 0.3] -
测试时增强(TTA):
python复制results = model.predict(source, augment=True) # 启用TTA -
模型集成:
python复制# 加权框融合(WBF) from ensemble_boxes import weighted_boxes_fusion models = [YOLO("model1.pt"), YOLO("model2.pt")] all_boxes = [] all_scores = [] all_labels = [] for model in models: results = model(img) all_boxes.append(results[0].boxes.xywhn) all_scores.append(results[0].boxes.conf) all_labels.append(results[0].boxes.cls) fused_boxes, fused_scores, fused_labels = weighted_boxes_fusion( all_boxes, all_scores, all_labels, weights=[1,1], iou_thr=0.5 )
8. 项目扩展与进阶方向
8.1 运动轨迹分析
python复制# tracking.py
from collections import defaultdict
from scipy.spatial import distance
class BallTracker:
def __init__(self, max_disappeared=5):
self.next_id = 0
self.objects = defaultdict(dict)
self.disappeared = defaultdict(int)
self.max_disappeared = max_disappeared
def update(self, detections):
# 初始化当前帧的对象集
current_ids = set()
# 如果没有检测到任何对象
if len(detections) == 0:
for object_id in list(self.disappeared.keys()):
self.disappeared[object_id] += 1
if self.disappeared[object_id] > self.max_disappeared:
self._delete_object(object_id)
return self.objects
# 如果当前没有跟踪任何对象
if len(self.objects) == 0:
for box in detections:
self._add_object(box)
else:
# 计算现有对象与新检测之间的欧氏距离
object_ids = list(self.objects.keys())
object_centers = [
self.objects[obj_id]["center"]
for obj_id in object_ids
]
detection_centers = [
self._get_center(box)
for box in detections
]
# 计算距离矩阵
D = distance.cdist(
np.array(object_centers),
np.array(detection_centers)
)
# 找到最小距离的匹配
rows = D.min(axis=1).argsort()
cols = D.argmin(axis=1)[rows]
used_rows = set()
used_cols = set()
for (row, col) in zip(rows, cols):
if row in used_rows or col in used_cols:
continue
object_id = object_ids[row]
self.objects[object_id]["box"] = detections[col]
self.objects[object_id]["center"] = detection_centers[col]
self.disappeared[object_id] = 0
used_rows.add(row)
used_cols.add(col)
# 处理未匹配的对象和检测
unused_rows = set(range(D.shape[0])) - used_rows
unused_cols = set(range(D.shape[1])) - used_cols
# 处理消失的对象
for row in unused_rows:
object_id = object_ids[row]
self.disappeared[object_id] += 1
if self.disappeared[object_id] > self.max_disappeared:
self._delete_object(object_id)
# 添加新对象
for col in unused_cols:
self._add_object(detections[col])
return self.objects
def _get_center(self, box):
x1, y1, x2, y2 = box
return ((x1 + x2) / 2, (y1 + y2) / 2)
def _add_object(self, box):
center = self._get_center(box)
self.objects[self.next_id] = {
"box": box,
"center": center
}
self.disappeared[self.next_id] = 0
self.next_id += 1
def _delete_object(self, object_id):
del self.objects[object_id]
del self.disappeared[object_id]
8.2 击球动作分析
使用MediaPipe进行姿态估计结合物体检测:
python复制# swing_analysis.py
import mediapipe as mp
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(
static_image_mode=False,
model_complexity=1,
smooth_landmarks=True
)
def analyze_swing(video_path):
cap = cv2.VideoCapture(video_path)
swing_metrics = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 检测球员姿态
results = pose.process(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
if results.pose_landmarks:
# 获取关键点
landmarks = results.pose_landmarks.landmark
left_shoulder = landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER]
right_shoulder = landmarks[mp_pose.PoseLandmark.RIGHT_SHOULDER]
left_hip = landmarks[mp_pose.PoseLandmark.LEFT_HIP]
# 计算躯干角度
torso_angle = calculate_angle(
left_shoulder.x, left_shoulder.y,
left_hip.x, left_hip.y,
right_shoulder.x, right_shoulder.y
)
# 检测球棒位置
detections = model(frame)
bat_boxes = [box for box in detections[0].boxes
if box.cls == BAT_CLASS_ID]
if bat_boxes:
bat_box = bat_boxes[0]
swing_metrics.append({
"frame": cap.get(cv2.CAP_PROP_POS_FRAMES),
"torso_angle": torso_angle,
"bat_speed": calculate_speed(bat_box)
})
cap.release()
return swing_metrics
8.3 部署到移动设备
使用ONNX Runtime进行移动端部署:
python复制# mobile_inference.py
import onnxruntime as ort
class MobileDetector:
def __init__(self, onnx_path):
self.session = ort.InferenceSession(onnx_path)
self.input_name = self.session.get_inputs()[0].name
def preprocess(self, image):
# 图像预处理
img = cv2.resize(image, (640, 640))
img = img.transpose(2, 0, 1) # HWC to CHW
img = np.expand_dims(img, axis=0) # 添加批次维度
img = img.astype(np.float32) / 255.0
return img
def detect(self, image):
input_tensor = self.preprocess(image)
outputs = self.session.run(
None,
{self.input_name: input_tensor}
)
return self.postprocess(outputs)
def postprocess(self, outputs):
# 后处理逻辑
boxes = outputs[0]
scores = outputs[1]
class_ids = outputs[2]
# 过滤低置信度检测
keep = scores > 0.5
return boxes[keep], scores[keep], class_ids[keep]