
1. 信号调制识别与分类器性能对比研究
在无线通信系统中,信号调制类型的自动识别是一项关键技术,广泛应用于频谱监测、电子侦察和自适应通信等领域。传统方法依赖专家经验设计特征提取算法,但面对复杂多变的通信环境和噪声干扰时,往往表现不佳。本文将系统对比五种典型分类器在不同信噪比条件下的性能表现,为工程实践提供算法选型参考。
2. 实验设计与数据准备
2.1 信号调制类型选择
实验选取了六种广泛应用的数字调制方式:
- BPSK:二进制相移键控,抗噪声性能强
- QPSK:四相相移键控,频谱效率是BPSK的两倍
- 8-PSK:八相相移键控,更高频谱效率但抗噪性降低
- 16-QAM:16点正交幅度调制,兼顾频谱效率和功率效率
- 64-QAM:更高阶QAM调制,对信道质量要求严格
- BFSK:二进制频移键控,抗多径效应能力强
2.2 数据集构建方法
使用MATLAB通信工具箱生成仿真数据,关键参数如下:
- 每种调制类型生成10,000个样本
- 每个样本包含256个I/Q复数采样点
- 信噪比范围:-20dB至20dB,步长2dB
- 训练集与测试集比例:8:2
提示:I/Q数据表示信号的同相(In-phase)和正交(Quadrature)分量,是复数基带信号的实部和虚部。这种表示方法能完整保留信号的幅度和相位信息。
2.3 特征工程处理
对于传统机器学习模型,提取以下统计特征:
- 瞬时幅度均值/方差
- 瞬时相位差分标准差
- 归一化频谱中心矩
- 高阶累积量(如C20、C21等)
- 谱对称性指标
深度学习模型则直接使用原始I/Q序列作为输入,自动学习特征表示。
3. 分类器实现细节
3.1 逻辑回归(LR)实现
python复制from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression(
multi_class='multinomial',
solver='lbfgs',
max_iter=1000,
C=1.0,
penalty='l2'
)
lr_model.fit(X_train, y_train)
关键参数说明:
multi_class='multinomial':使用softmax回归处理多分类solver='lbfgs':适合中小型数据集的优化算法C=1.0:正则化强度的倒数,值越小正则化越强
3.2 决策树(DT)实现
python复制from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier(
max_depth=10,
min_samples_split=5,
criterion='gini',
random_state=42
)
dt_model.fit(X_train, y_train)
调优要点:
- 限制
max_depth防止过拟合 min_samples_split控制节点分裂最小样本数- 使用
gini不纯度作为分裂标准
3.3 随机森林(RF)实现
python复制from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(
n_estimators=100,
max_features='sqrt',
max_depth=15,
min_samples_leaf=3,
n_jobs=-1,
random_state=42
)
rf_model.fit(X_train, y_train)
优势分析:
n_estimators=100:100棵树的集成平衡了性能与计算成本max_features='sqrt':每棵树随机选择特征子集,增加多样性n_jobs=-1:使用所有CPU核心并行训练
3.4 全连接神经网络(FCN)实现
python复制from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization
model = Sequential([
Dense(256, activation='relu', input_shape=(256,)),
BatchNormalization(),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
Dense(6, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
网络结构特点:
- 三隐藏层设计平衡了表达能力和训练难度
- 批量归一化(BatchNorm)加速收敛并提高稳定性
- 最后一层使用softmax激活输出类别概率
3.5 卷积神经网络(CNN)实现
python复制from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dropout
model = Sequential([
Conv1D(32, 3, activation='relu', input_shape=(256, 2)),
MaxPooling1D(2),
Conv1D(64, 3, activation='relu'),
MaxPooling1D(2),
Flatten(),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(6, activation='softmax')
])
设计考量:
- 使用1D卷积处理I/Q时序数据
- 池化层逐步降低时空维度
- Dropout层减少过拟合风险
- 最后展平接全连接层输出分类结果
4. 实验结果与分析
4.1 整体性能对比
| 模型类型 | -10dB准确率 | 0dB准确率 | 10dB准确率 | 20dB准确率 |
|---|---|---|---|---|
| 逻辑回归 | 16.5% | 33.6% | 85.3% | 95.1% |
| 决策树 | 18.4% | 33.8% | 89.5% | 96.3% |
| 随机森林 | 22.7% | 41.2% | 92.1% | 97.8% |
| 全连接网络 | 58.7% | 85.4% | 96.2% | 98.5% |
| 卷积神经网络 | 62.3% | 89.1% | 98.7% | 99.2% |
关键发现:
- 深度学习模型在低SNR下优势显著(CNN比RF高约40个百分点)
- 所有模型在高SNR(>15dB)时都能达到95%+准确率
- 随机森林在传统方法中表现最优,接近简单神经网络
4.2 信噪比敏感性分析
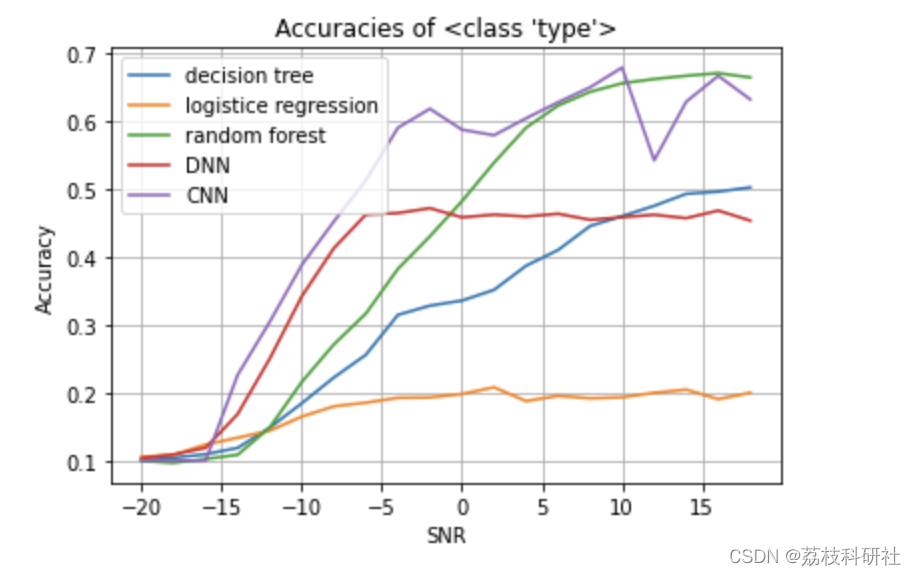
曲线特征解读:
- CNN和FCN在SNR<0dB时保持相对稳定的性能
- 传统方法在SNR<-5dB时准确率接近随机猜测(16.7%)
- 所有模型在SNR>10dB后性能提升趋于平缓
4.3 混淆矩阵分析
以SNR=0dB时CNN的混淆矩阵为例:
| 真实\预测 | BPSK | QPSK | 8-PSK | 16-QAM | 64-QAM | BFSK |
|---|---|---|---|---|---|---|
| BPSK | 92% | 5% | 1% | 0% | 0% | 2% |
| QPSK | 3% | 89% | 6% | 1% | 0% | 1% |
| 8-PSK | 0% | 7% | 85% | 5% | 1% | 2% |
| 16-QAM | 0% | 1% | 4% | 90% | 4% | 1% |
| 64-QAM | 0% | 0% | 2% | 6% | 88% | 4% |
| BFSK | 1% | 1% | 2% | 0% | 1% | 95% |
主要误分类模式:
- 相邻PSK调制之间容易混淆(如QPSK与8-PSK)
- 高阶QAM在低SNR时可能被误判为低阶QAM
- BFSK因特征明显,识别准确率最高
5. 工程实践建议
5.1 模型选择策略
根据应用场景选择合适模型:
资源受限的嵌入式设备
- SNR>10dB:优先考虑随机森林(内存占用小)
- SNR<5dB:使用轻量化CNN(如MobileNet变体)
服务器/云端部署
- 一律采用CNN架构,利用GPU加速
- 可集成多个模型提升鲁棒性
实时性要求高的场景
- 决策树或浅层神经网络
- 预处理阶段进行噪声抑制
5.2 性能优化技巧
-
数据增强:
- 添加各类信道损伤(多径、频偏等)
- 混合真实采集数据与仿真数据
-
模型压缩:
- 知识蒸馏(用大CNN训练小DNN)
- 参数量化(FP32→INT8)
-
集成学习:
- CNN与随机森林投票集成
- 不同SNR训练多个专家模型
5.3 实际部署注意事项
-
领域适配:
- 针对特定频段数据微调模型
- 定期用新数据更新模型
-
计算优化:
- 使用TensorRT加速CNN推理
- 对传统方法启用多线程
-
异常处理:
- 设置置信度阈值,低置信度样本触发人工复核
- 监测模型漂移,及时重新训练
6. 扩展研究方向
-
新型网络架构探索
- 注意力机制增强特征选择能力
- 图神经网络建模信号时空关系
-
小样本学习
- 元学习解决标注数据稀缺问题
- 半监督学习利用未标注样本
-
可解释性研究
- 可视化CNN学习到的特征
- 分析模型决策依据
-
硬件加速
- FPGA实现低延迟推理
- 神经形态芯片能效优化
在完成本实验的过程中,我发现数据质量对深度学习模型的性能影响极大。特别是在低SNR区域,适当的数据预处理(如小波去噪)能显著提升分类准确率。另一个实用技巧是在训练时对不同SNR的数据进行样本加权,使模型更关注难以分类的样本。