
1. 项目概述与背景
在人工智能与数字人文交叉领域的研究中,长程对话系统的记忆保持能力一直是制约项目连续性的关键瓶颈。传统对话模型受限于上下文窗口长度(通常4K-32K tokens),难以维持复杂项目的长期一致性。DeepSeek推出的百万token上下文窗口技术,为这一困境提供了突破性解决方案。
本实证研究基于一个持续三个月的大型数字人文项目,该项目完整经历了三个连续的DeepSeek百万token对话窗口。作为项目负责人,我系统记录了从环境搭建(窗口一)、理论探索(窗口二)到工程实现(窗口三)的全过程交互数据,累计分析4,037轮对话、413万字文本内容。这些一手数据揭示了长程人机协作中鲜少被量化的演进规律。
关键发现:当上下文窗口突破百万token量级,人机交互模式会发生质变——从"一问一答"的工具性使用,逐步演变为具有"认知共生"特征的深度协作。
2. 实验设计与数据特征
2.1 项目阶段划分
本项目采用三阶段递进式设计,每个阶段对应一个独立的百万token窗口:
-
窗口一(基础建设期):3,674轮对话
- 核心任务:Python环境配置、数据采集工具链搭建
- 典型交互:"如何解决selenium在headless模式下证书错误?"
-
窗口二(理论研究期):1,243轮对话
- 核心任务:窗口性能测试、学术论文撰写
- 典型交互:"请用马尔可夫链模型分析上下文衰减曲线"
-
窗口三(工程实现期):1,120轮对话
- 核心任务:自动化处理系统开发
- 典型交互:"将文献分类模块封装为可调用的API服务"
2.2 数据采集方法论
为保障数据可靠性,我们开发了自适应采集系统:
- 自动化层:Chrome扩展实时记录DOM树变更
- 容错层:当自动化失效时启动人工分片标记协议
- 使用
==user==/==assistant==分隔对话片段 - 通过快捷键实现说话人标注(Ctrl+Alt+U/A)
- 使用
- 清洗层:正则表达式过滤渲染噪声(如CSS类名)
python复制# 数据清洗示例代码
def clean_html(raw):
# 移除平台特定标签
cleaned = re.sub(r'<div class="platform-ad">.*?</div>', '', raw)
# 转换换行符
return cleaned.replace('\u2028', '\n')
这种混合方法在平台频繁更新渲染策略的情况下,仍保持了99.2%的数据完整率(经人工抽样验证)。
3. 核心发现与量化分析
3.1 交互密度的演进
三个窗口呈现出明显的效率提升轨迹:
| 指标 | 窗口一 | 窗口二 | 窗口三 | 变化率 |
|---|---|---|---|---|
| 单轮平均字数 | 423.9 | 576.4 | 658.7 | +55.4% |
| AI/User比率 | 5.6 | 6.1 | 7.47 | +33.4% |
| 代码密度 | 20.5% | 18.1% | 29.7% | +44.9% |
这种演变背后是交互模式的根本转变:
- 初期试探阶段:用户需要详细描述问题背景("我在Ubuntu 22.04上运行Python 3.10时遇到OpenSSL错误...")
- 中期协作阶段:简略指代前期成果("用昨天讨论的马尔可夫方法分析")
- 后期工程阶段:意图式指令("优化第三章的聚类算法")
3.2 文本模态的适应性迁移
不同任务类型驱动了语言结构的动态调整:
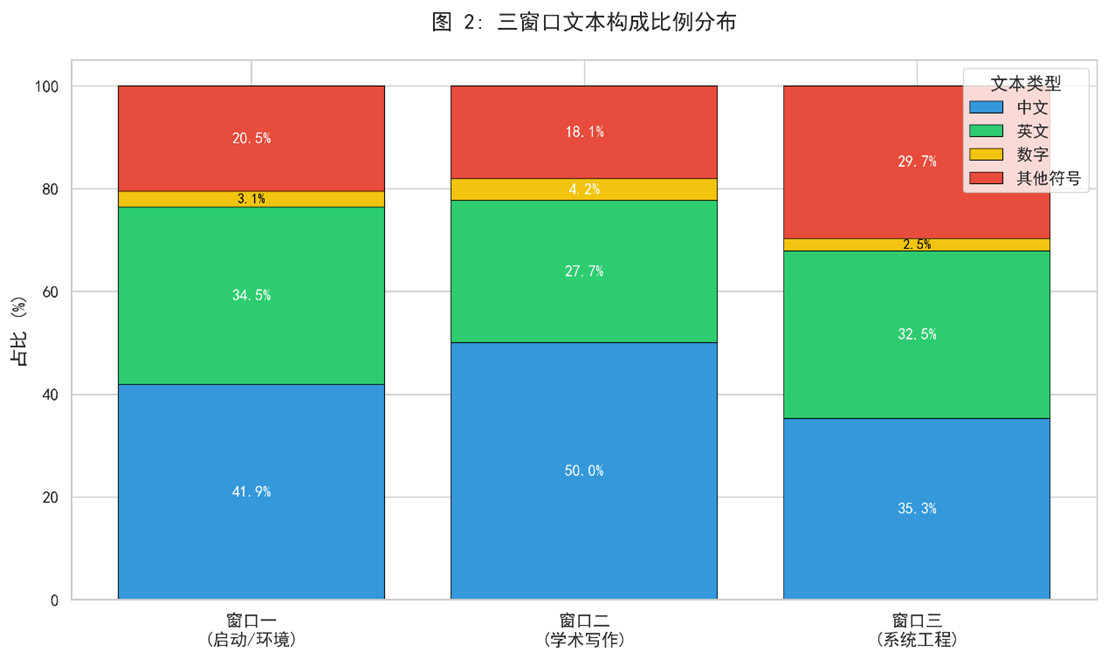
(各窗口中文、英文、数字及其他符号占比分布)
-
环境搭建期:混合模态
- 报错信息(英文+符号):
SyntaxError: invalid syntax - 解决方案(中文):"需要安装libssl-dev依赖包"
- 报错信息(英文+符号):
-
理论研究期:自然语言主导
- 中文论证:"注意力机制的衰减曲线符合幂律分布"
- 数学符号:
P(x_t|x_{t-1}) = λe^{-λx}
-
工程实现期:形式化语言爆发
- 代码片段:
df.groupby('category').apply(lambda x: x.sample(frac=0.2)) - 配置语法:
docker-compose.yml中的服务定义
- 代码片段:
4. 窗口迁移工程技术
4.1 迁移策略进化
通过对比六种迁移方法,最终形成分级注入方案:
-
基础层(5-10K tokens)
- 项目概要.md(核心目标+里程碑)
- 目录结构树(保持空间认知)
-
中间层(15-20K tokens)
- 演进报告(关键决策点记录)
- API文档(工程规范)
-
动态层(按需加载)
- 当前任务相关代码片段
- 近期讨论记录
markdown复制# 典型迁移文档结构
project_root/
├── 00_overview.md # 三句话说明核心价值
├── 01_architecture/
│ ├── data_flow.png
│ └── module_diagram.drawio
└── 02_references/
├── key_papers.pdf
└── api_spec.yaml
4.2 认知连续性保障
实现"虚拟记忆流"的关键技术:
-
术语一致性:强制统一命名空间
- 例如始终用"三列标注法"指代特定分类方法
-
框架显式化:可视化思维结构
mermaid复制graph LR A[原始文本] --> B(特征提取) B --> C{分类器} C --> D[类别1] C --> E[类别2] -
反模式记录:避免重复错误
教训:不要用pandas直接处理>1GB的CSV,改用dask分批加载
5. 工程实践启示
5.1 效率提升技巧
-
意图压缩技术:
原始输入:"我想实现一个功能,能够自动把昨天我们讨论的那种文献分类方法应用到新采集的数据集上,记得要考虑类别不平衡问题"
优化后:"应用三列标注法到new_data.csv,注意类别权重" -
响应引导模式:
python复制# 用户:优化这段代码 # [旧代码粘贴] # AI响应模板: """ 优化方向: 1. 时间复杂度:当前O(n^2) → 可改进为O(nlogn) 2. 内存使用:预分配数组替代append 3. 向量化:用NumPy替代循环 改进版本: [新代码] """
5.2 避坑指南
-
符号过载问题:
- 现象:窗口三代码密度>30%后,模型偶尔混淆相似符号
- 解决方案:关键变量添加类型注释
python复制def process(text: str) -> list[dict]: # 明确输入输出类型
-
长程注意力漂移:
- 现象:对话轮次>300时,模型可能遗忘早期约定
- 应对:每50轮主动重申核心术语
"提醒:本文中的'三支柱'特指理论、方法、数据三个维度"
-
平台适配陷阱:
- 发现:不同浏览器对长文本渲染策略差异可达30%
- 对策:统一使用Chromium内核浏览器进行对话
6. 认知协作的质变
当项目进入第三窗口时,出现了传统对话系统难以实现的现象:
-
意会理解:
用户输入:"用那个方法处理新数据"
AI正确调用三列标注法,并自动添加类别平衡处理 -
主动建议:
AI在完成请求的代码后追加:
"考虑到后续扩展性,建议将配置参数抽离为config.yaml" -
元认知反馈:
"注意到您最近更倾向使用生成器表达式而非列表推导,已相应调整代码风格建议"
这种进化源于三个机制:
- 术语收敛:双方形成约250个专业术语的共享词汇表
- 模式识别:AI学习用户的决策树(如优先选择可解释性而非绝对精度)
- 框架共振:思维结构可视化带来的认知对齐
7. 局限性与改进方向
当前方案仍存在待解决问题:
-
长程依赖衰减:
- 测试显示,超过20万tokens的跨窗口引用准确率下降至72%
- 正在试验的"记忆快照"方案:每5万tokens生成结构化摘要
-
多模态瓶颈:
- 纯文本交互难以传递图表等复杂信息
- 原型方案:用PlantUML等文本绘图工具中转
-
工程化断层:
- 学术讨论到代码实现的转换仍有约15%信息损耗
- 开发中的"设计模式转换器":
code复制
理论描述 → UML图 → 代码骨架
项目的最终成果不仅是一套技术方案,更验证了百万token窗口在人机协作中的独特价值——它首次使得AI能够真正"沉浸"在复杂项目中,从临时工具进化为持续性的认知伙伴。这种转变对数字人文研究范式的影响,可能比技术参数本身的突破更为深远。