
1. BERT:自然语言处理的革命性突破
2018年,谷歌研究院发布的一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》彻底改变了自然语言处理(NLP)领域的格局。作为一名长期从事NLP研究的工程师,我至今仍记得第一次接触BERT时的震撼——它不仅在11项NLP任务上刷新了记录,更重要的是开创了"预训练+微调"的新范式。
BERT(Bidirectional Encoder Representations from Transformers)的核心创新在于其双向编码机制。传统语言模型如RNN、LSTM只能单向处理文本(从左到右或从右到左),而BERT通过Transformer架构实现了真正的双向理解。这就像我们人类阅读时,会同时利用前后文信息来理解当前词语的含义。
提示:BERT的双向性使其特别适合需要全面理解上下文的任务,如问答系统、文本分类等,但在文本生成任务上不如GPT系列模型。
2. BERT架构深度解析
2.1 输入表示层:文本的数字化处理
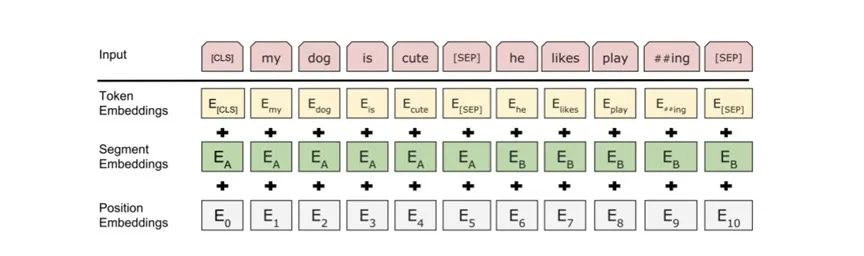
BERT的输入处理堪称工程艺术的典范。它将原始文本转化为模型可理解的向量表示,这个过程包含三个关键部分:
-
词嵌入(Token Embeddings):
- 使用WordPiece分词器,将单词拆分为子词单元(如"unhappiness"→"un"+"##happy"+"##ness")
- 每个子词被映射为一个768维的向量(BERT-base版本)
- 特殊标记:[CLS]用于分类任务,[SEP]分隔句子,[MASK]用于预训练
-
位置嵌入(Position Embeddings):
- 解决Transformer无法感知词序的问题
- 最大支持512个token的位置编码
- 通过正弦函数生成,确保模型能理解相对位置关系
-
段嵌入(Segment Embeddings):
- 区分句子对中的不同句子(如问答中的问题和答案)
- 对于单句输入,所有token标记为0
- 对于句子对,第一句标记为0,第二句标记为1
这三种嵌入相加后形成最终的输入表示,如下图所示:
2.2 Transformer编码器:BERT的"大脑"
BERT的核心是由多层Transformer编码器堆叠而成。以BERT-base为例:
- 12层Transformer编码器
- 每层包含:
- 多头自注意力机制(12个注意力头)
- 前馈神经网络(中间层维度3072)
- 残差连接和层归一化
自注意力机制是Transformer的灵魂所在。它允许模型动态地为每个token分配不同的注意力权重。例如在句子"银行发布了新的贷款政策"中:
- "贷款"会高度关注"银行"
- "政策"会同时关注"贷款"和"银行"
- 这种关注是双向且动态计算的
多头机制则让模型能够并行关注不同方面的信息,就像一群人从不同角度分析同一段文本。
3. BERT的训练策略
3.1 预训练:海量数据中的通用语言理解
BERT的预训练采用两种创新任务:
-
掩码语言模型(MLM):
- 随机遮盖15%的token(其中80%替换为[MASK],10%替换为随机词,10%保持不变)
- 模型需要预测被遮盖的原始词
- 这种设计迫使模型深入理解上下文语义
-
下一句预测(NSP):
- 给定两个句子,判断它们是否是连续的
- 50%正样本(实际连续的句子)
- 50%负样本(随机组合的句子)
- 帮助模型理解句子间关系
预训练通常需要:
- 数十亿词的语料(如Wikipedia+BookCorpus)
- 强大的计算资源(TPU/GPU集群)
- 数天到数周的训练时间
3.2 微调:针对特定任务的高效适配
预训练后的BERT可以通过简单的微调适配各种下游任务。常见的微调模式包括:
-
文本分类:
- 使用[CLS]标记的输出向量
- 添加一个简单的分类层
- 适用于情感分析、新闻分类等任务
-
序列标注:
- 使用每个token对应的输出向量
- 添加CRF或softmax分类层
- 适用于命名实体识别、词性标注等
-
问答任务:
- 使用两个分类器分别预测答案的起止位置
- 输入为问题+上下文组成的句子对
- 如SQuAD数据集的任务
微调的优势在于:
- 所需数据量大幅减少(通常数千标注样本)
- 训练时间短(几小时到一天)
- 性能却能接近甚至超过专门设计的模型
4. BERT的实战应用与优化
4.1 工业界应用案例
在实际项目中,BERT及其变体已经广泛应用于:
-
搜索引擎优化:
- 理解长尾查询的真实意图
- 处理复杂的语义匹配
- 谷歌搜索已全面采用BERT技术
-
智能客服系统:
- 精准理解用户自然语言提问
- 从知识库中检索最佳答案
- 支持多轮对话管理
-
金融文本分析:
- 财报情绪分析
- 风险事件检测
- 自动报告生成
-
医疗信息处理:
- 电子病历结构化
- 医学文献摘要
- 药物相互作用分析
4.2 性能优化技巧
在实际部署BERT时,我们积累了一些宝贵经验:
-
模型选择策略:
- 计算资源有限时:选用DistilBERT、TinyBERT等轻量版
- 延迟敏感场景:考虑ALBERT或MobileBERT
- 最高准确率需求:使用BERT-large或RoBERTa
-
微调技巧:
- 学习率设置:通常2e-5到5e-5之间
- Batch size:16或32较为常见
- 训练轮次:3到5个epoch通常足够
- 早停策略:监控验证集性能
-
部署优化:
- 使用ONNX格式加速推理
- 量化技术减小模型体积
- 服务化部署考虑TensorRT优化
5. BERT生态与发展趋势
5.1 主流变体比较
随着研究的深入,BERT家族已经发展出多个重要变体:
| 模型名称 | 核心创新 | 参数量 | 相对BERT-base速度 | 典型应用场景 |
|---|---|---|---|---|
| RoBERTa | 更长的训练、更大的batch size | 1.25亿 | 1x | 需要高准确率的任务 |
| ALBERT | 参数共享、嵌入分解 | 1.2亿 | 1.5x | 资源受限环境 |
| DistilBERT | 知识蒸馏 | 6600万 | 1.7x | 移动端/边缘计算 |
| ELECTRA | 替换token检测任务 | 1.1亿 | 1.2x | 预训练效率提升 |
| ModernBERT | 长上下文支持 | 1.3亿 | 0.8x | 长文档处理 |
5.2 未来发展方向
根据我们的行业观察,BERT技术将朝以下方向演进:
-
多模态融合:
- 结合视觉、语音等多模态信息
- 如VL-BERT、VideoBERT等模型
-
高效架构设计:
- 更稀疏的注意力机制
- 混合专家系统(MoE)
- 动态网络结构
-
小样本学习:
- 元学习与适配器技术
- 提示学习(Prompt Learning)
- 参数高效微调
-
可解释性与安全:
- 注意力可视化分析
- 偏见检测与缓解
- 对抗鲁棒性增强
6. 学习路径与实践建议
6.1 初学者入门路线
对于刚接触BERT的学习者,我建议按照以下步骤:
-
理论基础:
- 理解Transformer架构
- 掌握自注意力机制
- 学习WordPiece分词
-
工具掌握:
- Hugging Face Transformers库
- PyTorch/TensorFlow框架
- 基本的GPU编程
-
实践项目:
- 使用预训练模型进行推理
- 在自己的数据集上微调
- 尝试不同的下游任务
6.2 常见问题解答
在教学中,我们经常遇到这些问题:
Q:BERT和GPT有什么区别?
A:主要区别在于:
- BERT是双向编码器,适合理解任务
- GPT是单向解码器,专长文本生成
- 训练目标不同(MLM vs 自回归)
Q:如何解决BERT的长文本问题?
A:常用方案:
- 分段处理+聚合
- 使用长上下文变体(如Longformer)
- 关键信息提取后再处理
Q:微调需要多少数据?
A:取决于任务复杂度:
- 简单分类:500-1000样本/类
- 复杂任务:5000+样本
- 可通过数据增强减少需求
Q:如何降低BERT的计算成本?
A:有效方法包括:
- 知识蒸馏(如DistilBERT)
- 量化(FP16/INT8)
- 剪枝和稀疏化
- 使用更高效的注意力变体
7. 实战代码示例
让我们通过一个完整的文本分类示例,展示BERT的实际应用:
python复制from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
from datasets import load_dataset
# 1. 加载数据集
dataset = load_dataset("imdb")
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 2. 数据预处理
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# 3. 加载模型
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 4. 训练配置
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# 5. 训练与评估
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
)
trainer.train()
这个示例展示了如何使用Hugging Face生态系统快速构建一个基于BERT的情感分析模型。实际应用中,我们还需要考虑:
- 更细致的数据预处理(清洗、平衡)
- 超参数调优(学习率、batch size等)
- 更全面的评估指标(精确率、召回率等)
- 模型部署和服务化
8. 进阶研究方向
对于希望深入BERT研究的开发者,以下方向值得关注:
-
模型压缩技术:
- 量化感知训练
- 结构化剪枝
- 注意力头剪枝
-
训练优化:
- 混合精度训练
- 梯度累积
- 分布式训练策略
-
领域适配:
- 持续预训练
- 领域特定词表
- 任务特定架构修改
-
可解释性工具:
- 注意力可视化
- 概念激活向量
- 对抗性测试
在实践中我们发现,BERT的成功应用往往需要结合领域知识进行针对性优化。例如在法律文本处理中,我们可能需要:
- 构建法律专业词表
- 进行法律语料的持续预训练
- 设计法律特定的预训练任务
- 调整模型结构适应长文档特点
这种领域适配的过程虽然需要额外投入,但通常能带来显著的性能提升。