
1. 训练结果存储与文件结构解析
当你完成YOLOv8模型的训练后,系统会自动生成一系列结果文件,这些文件通常存放在工作目录的runs/detect子目录中。这个目录结构对于理解模型表现至关重要,下面我将详细拆解每个核心文件的作用。
训练结果目录通常以train_n命名(n代表第n次训练),典型结构如下:
code复制runs/detect/train3/
├── args.yaml
├── confusion_matrix.png
├── confusion_matrix_normalized.png
├── labels.jpg
├── results.png
├── weights/
│ ├── best.pt
│ └── last.pt
└── *.csv
1.1 核心配置与权重文件
weights目录包含两个关键模型文件:
best.pt:验证集上表现最好的权重文件(按mAP@0.5排序)last.pt:训练结束时的最终权重文件
实际部署时建议使用best.pt,因为:
- 它代表模型在验证集上的最优表现
- 避免了可能存在的过拟合风险
- 通常具有更好的泛化能力
args.yaml文件记录了完整的训练配置参数,包括:
yaml复制batch: 16
epochs: 100
imgsz: 640
lr0: 0.01
...
这个文件的价值在于:
- 精确复现训练过程
- 调试时对比不同参数的效果
- 迁移学习时作为基础配置参考
1.2 可视化分析图表
模型性能图表是评估训练质量的核心依据,主要包括:
评估指标曲线组:
BoxF1_curve.png:F1分数随置信度变化曲线BoxP_curve.png:精确率-置信度曲线BoxPR_curve.png:P-R曲线(最核心指标)BoxR_curve.png:召回率-置信度曲线
混淆矩阵:
confusion_matrix.png:原始样本数量矩阵confusion_matrix_normalized.png:归一化比例矩阵
数据分布图:
labels.jpg:标签分布可视化报告
综合训练曲线:
results.png:损失和指标随epoch变化趋势
2. 核心指标深度解读
2.1 基础概念精要
在分析具体图表前,必须明确几个关键术语:
-
置信度(Confidence):模型对预测结果的把握程度(0-1)
- 阈值设置过高→漏检增多
- 阈值设置过低→误报增多
-
精确率(Precision):
$$ Precision = \frac{TP}{TP+FP} $$
反映"预测为正的样本中实际为正的比例" -
召回率(Recall):
$$ Recall = \frac{TP}{TP+FN} $$
反映"实际为正的样本中被预测为正的比例" -
F1 Score:
$$ F1 = 2\times\frac{P\times R}{P+R} $$
精确率和召回率的调和平均数 -
IoU(交并比):
$$ IoU = \frac{Area_{overlap}}{Area_{union}} $$
预测框与真实框的重叠程度 -
mAP@0.5:
- 先计算各类别AP(P-R曲线下面积)
- 再对所有类别取平均
- @0.5表示IoU阈值设为50%
2.2 指标关联性分析
这些指标之间存在深层关联:
- 提高置信度阈值→精确率↑ 召回率↓
- 降低置信度阈值→精确率↓ 召回率↑
- 理想模型应同时保持高精确率和高召回率
在实际火灾检测场景中:
- 误报(False Positive)成本:可能引发不必要的警报
- 漏检(False Negative)成本:可能错过真实火情
- 因此需要根据业务需求调整阈值平衡点
3. 关键图表解析实战
3.1 BoxPR_curve.png分析
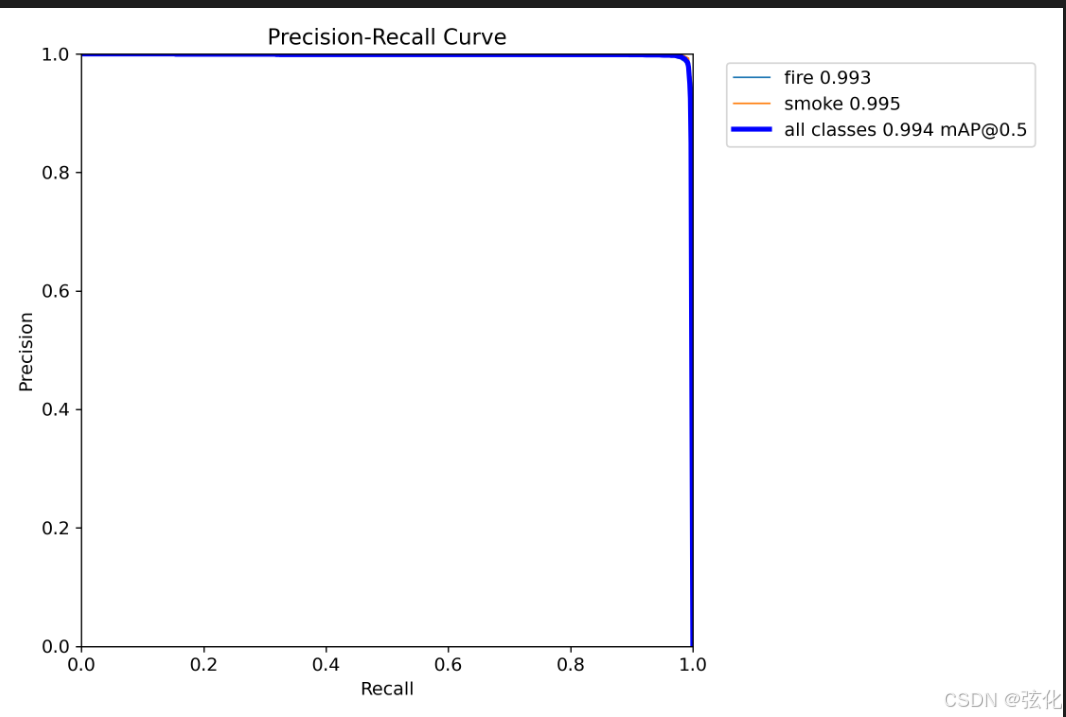
这是评估目标检测模型最重要的曲线,其核心特征:
-
曲线形态:
- 优秀模型的曲线应尽可能靠近右上角
- 曲线下面积(AUC)越大越好
- 本例中mAP@0.5达到0.994,接近完美
-
业务解读:
- 当召回率=0.9时,精确率仍保持>0.99
- 意味着在检测到90%真实火情时,误报率<1%
- 这对火灾预警系统至关重要
-
类别对比:
- fire和smoke曲线几乎重合
- 说明模型对两类目标的识别能力均衡
- 没有出现明显的类别偏重
3.2 confusion_matrix_normalized.png分析
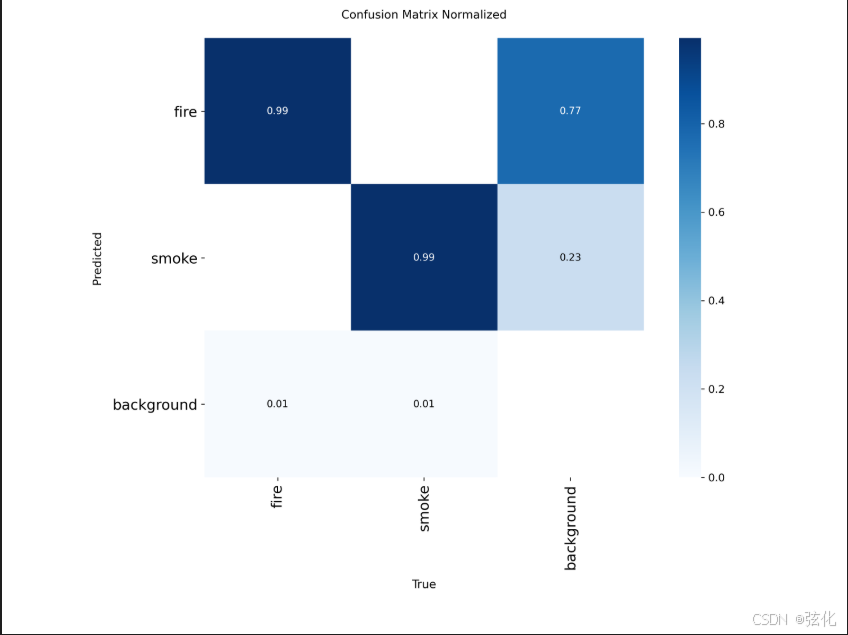
归一化混淆矩阵揭示了模型的错误模式:
-
对角线数值:
- fire→fire:0.99
- smoke→smoke:0.99
- 表明分类准确率极高
-
错误类型:
- 主要错误是漏检(判为background)
- fire→background:1%
- smoke→background:1%
- 几乎没有类别间混淆
-
业务影响:
- 误报率极低(background→fire/smoke仅1%)
- 适合对误报敏感的安防场景
- 漏检可通过降低置信度阈值进一步改善
3.3 results.png综合评估
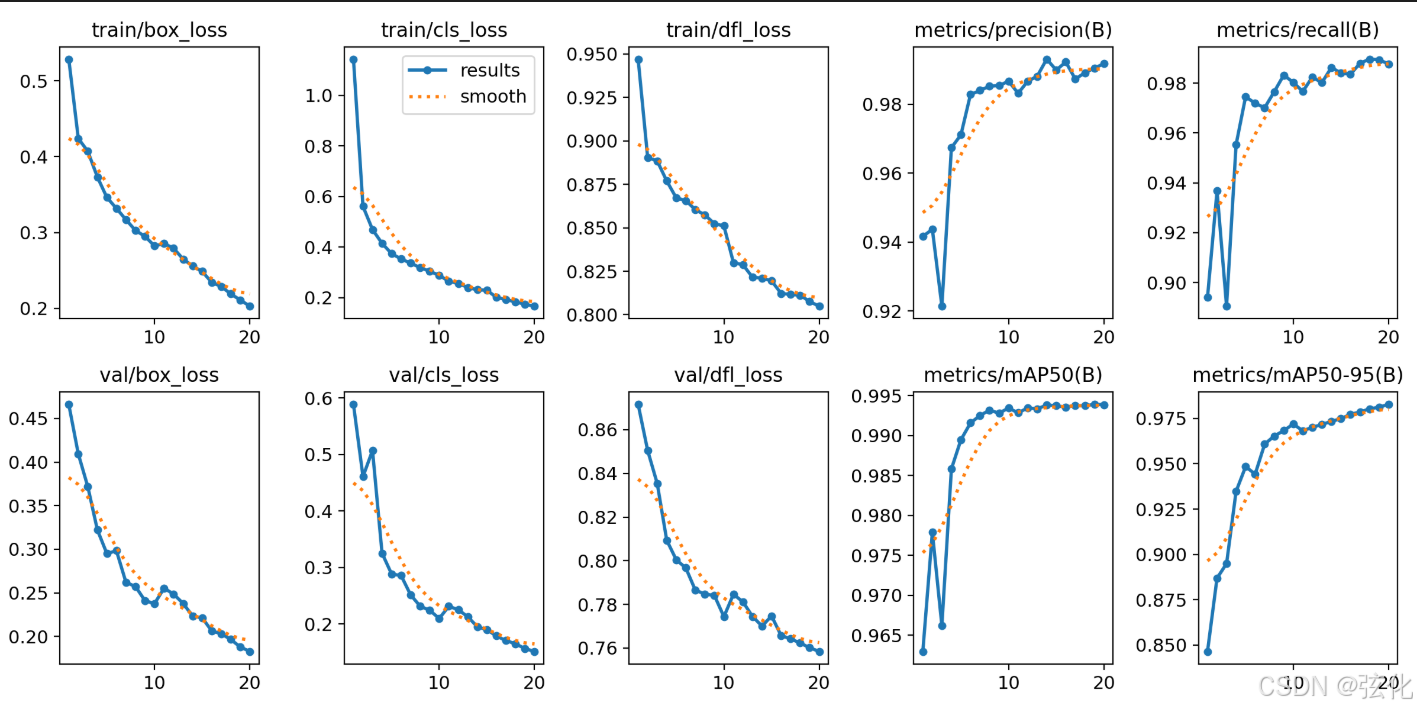
这张综合图包含6个子图,需要分层解读:
-
损失曲线:
- 所有损失(train/val)均平稳下降
- 最终box_loss≈0.2,cls_loss≈0.17
- 无过拟合迹象(train/val差距小)
-
指标曲线:
- mAP50从0.96→0.99(优秀)
- mAP50-95从0.85→0.98(卓越)
- 说明模型在不同IoU阈值下都表现良好
-
训练健康度:
- 前10个epoch快速收敛
- 后10个epoch微调优化
- 建议类似任务可设epoch=20-30
4. 模型优化与部署建议
4.1 置信度阈值调优
根据BoxF1_curve.png显示:
- 最佳平衡点:confidence=0.672时F1=0.99
- 实际部署时可考虑:
- 安全优先:设0.5(召回率↑)
- 精准优先:设0.8(精确率↑)
阈值调整方法:
python复制from ultralytics import YOLO
model = YOLO('best.pt')
results = model.predict(source='input.jpg', conf=0.67) # 调整conf参数
4.2 常见问题解决方案
-
漏检问题:
- 现象:少量fire/smoke被判为background
- 解决方案:
- 增加小目标训练样本
- 使用更小的检测粒度(如640→1280)
- 降低conf阈值
-
类别不平衡:
- 现象:fire样本是smoke的2.6倍
- 当前影响不大(mAP均>0.99)
- 如需优化可:
- 对smoke样本过采样
- 使用类别加权损失函数
-
标注错误处理:
- 发现部分smoke实为水幕
- 解决方案:
- 清洗错误标注数据
- 增加水幕负样本
- 重新训练模型
4.3 部署注意事项
-
硬件选择:
- 边缘设备:NVIDIA Jetson系列
- 服务器端:T4/A10G等GPU
- 量化优化:可使用TensorRT加速
-
推理优化:
python复制# 启用TensorRT加速
model.export(format='engine', device=0)
# 量化INT8优化
model.export(format='onnx', int8=True)
- 持续监控:
- 记录生产环境中的FP/FN案例
- 定期用新数据微调模型
- 建立自动化模型迭代流程
5. 火灾检测专项优化技巧
5.1 数据增强策略
针对火灾检测的特殊性,推荐增强方式:
yaml复制augment:
- hsv_h: 0.015 # 色相扰动模拟不同火源
- hsv_s: 0.7 # 饱和度增强突出火焰
- hsv_v: 0.4 # 明度变化模拟烟雾
- degrees: 10 # 小角度旋转
- translate: 0.1
- scale: 0.5 # 尺度变化增强小目标检测
5.2 模型架构调整
对于YOLOv8火灾检测:
-
推荐使用YOLOv8m模型:
- 平衡精度与速度
- 参数量约25M
- 640输入下约50FPS
-
关键修改点:
- 增加小目标检测层
- 调整anchor尺寸匹配火焰特征
- 使用EIoU损失提升框回归精度
5.3 业务逻辑增强
在实际部署时建议:
-
时序分析:
- 连续多帧检测确认
- 减少瞬时误报
-
区域权重:
- 重点区域检测阈值降低
- 非重点区域阈值提高
-
多模型融合:
- 结合传统火焰颜色特征
- 红外数据辅助判断
通过本指南的系统分析,你应该已经掌握YOLOv8训练结果的全面解读方法。记住,优秀的模型评估不仅要看最终指标,更要理解每个数字背后的业务含义。在实际火灾预警系统中,建议保持mAP@0.5>0.95,同时根据场景需求调整置信度阈值,在误报和漏检之间找到最佳平衡点。