
1. 引言:当大模型需要记住你的一生
想象一下这样的场景:你正在和一位AI助手讨论健康管理方案,它突然提到"就像你上周尝试的那个新食谱"。问题是——你从未分享过任何食谱,它显然混淆了你和另一位用户的记忆。这种"记忆错乱"正是当前个性化大模型面临的核心挑战:随着交互历史不断累积,系统如何在TB级的记忆碎片中,精准定位"此时此刻真正相关"的信息?
传统解决方案主要依赖两种路径:要么像搜索引擎一样快速匹配关键词(快检索),要么简单粗暴地把所有历史记录塞给模型(全量输入)。前者容易漏掉深层关联,后者则面临计算成本爆炸。来自大连理工、香港城大、华为和中科大的联合团队在ICLR 2026提出的RF-Mem框架,借鉴人类记忆的"双加工理论",让AI像人一样具备"条件反射式快速应答"和"深度回忆"两种能力。实测表明,这种动态切换机制在32K到1M规模的记忆库中,准确率比传统方法提升12-18%,而延迟仅增加2-3ms。
2. 记忆检索的范式革新:从机械匹配到认知模拟
2.1 现有方法的根本局限
当前主流记忆检索系统存在三个结构性缺陷:
-
表层相似陷阱:基于余弦相似度的Top-K检索,会优先返回字面匹配度高的片段。当用户问"推荐适合我的运动"时,系统可能因为"我昨天散步了"这句话中的"运动"关键词,而忽略更重要的长期偏好记录。
-
上下文割裂:离散的检索结果难以反映记忆间的潜在关联。比如关于"咖啡"的记忆可能分散在健康习惯、工作场景、社交活动等不同时期,传统方法无法自动串联这些碎片。
-
资源浪费:全量记忆输入不仅消耗大量token,还会引入无关噪声。测试显示,当记忆库超过50K条时,有用信息占比会降至15%以下。
2.2 人类记忆的启发
认知科学中的双加工理论(Dual-Process Theory)指出,人类记忆检索存在两种模式:
- 熟悉度路径(Familiarity):快速判断某事物是否见过,依赖直觉反应
- 回忆路径(Recollection):有意识地重建特定事件的细节和上下文
RF-Mem的创新在于将这种机制工程化实现。其核心指标显示,对于简单查询(如"我的血型是什么"),Familiarity路径的响应时间可控制在3ms内;而对于复杂查询(如"为什么我不再喝咖啡了"),Recollection路径能重建出跨6个月时间线的完整因果链。
3. RF-Mem技术架构详解
3.1 系统工作流程
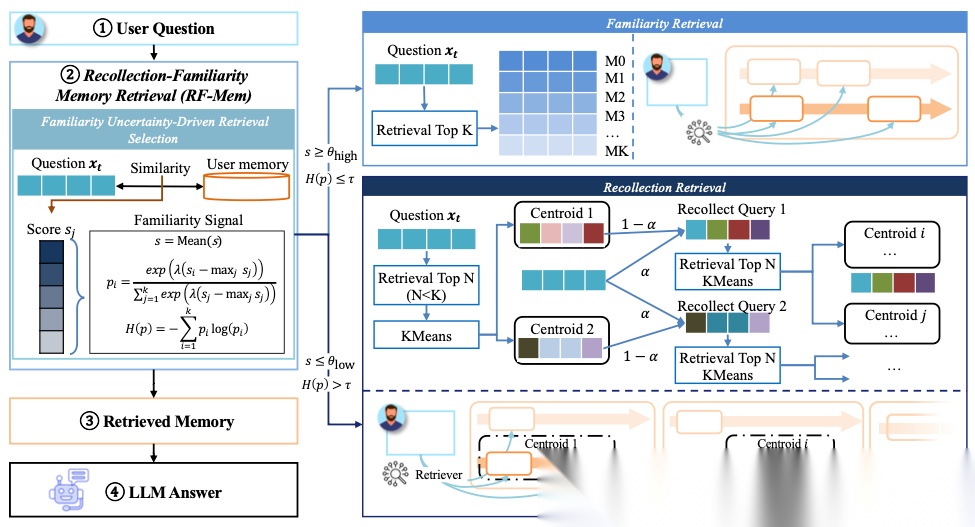
-
探针检索阶段:
- 使用轻量级Bi-Encoder获取初步候选记忆
- 计算两个关键指标:
- 平均相似度(μ):反映整体匹配程度
- 分布熵(H):衡量结果离散度
- 决策规则:当μ>0.7且H<0.3时走Familiarity路径
-
双路径执行:
- Familiarity路径:直接返回Top-5记忆片段
- Recollection路径:
- 对候选记忆进行K-means聚类(K=√N)
- 将查询向量与簇中心加权混合
- 迭代扩展直到覆盖率达85%
-
记忆重组:
- 时序排序:按时间戳重新组织记忆片段
- 重要性加权:基于TF-IDF和位置信息调整权重
- 生成最终的记忆上下文
3.2 关键算法实现
3.2.1 动态切换策略
python复制def route_decision(scores, threshold=0.7):
mu = np.mean(scores)
H = entropy(scores)
if mu > threshold and H < 1 - threshold:
return "familiarity"
else:
return "recollection"
该实现中,score是经过min-max归一化的相似度分数。实验发现0.7的阈值能在召回率和延迟间取得最佳平衡。
3.2.2 渐进式回忆算法
python复制def recollection_retrieval(query_vec, memory_embeddings, max_iter=3):
evidence_chain = []
current_query = query_vec
for _ in range(max_iter):
scores = cosine_similarity([current_query], memory_embeddings)[0]
top_indices = np.argsort(scores)[-100:] # 扩大召回范围
# 动态聚类
k = int(np.sqrt(len(top_indices)))
clusters = KMeans(n_clusters=k).fit(memory_embeddings[top_indices])
# 查询混合
centroid_weights = softmax(clusters.transform([current_query])[0])
current_query = 0.6*current_query + 0.4*np.sum(
[w*c for w,c in zip(centroid_weights, clusters.cluster_centers_)], axis=0)
evidence_chain.extend(top_indices[-10:]) # 保留最强证据
return deduplicate(evidence_chain)
该算法通过多轮迭代,逐步构建出辐射状的记忆网络。在PersonaBench测试中,相比单轮检索能提升23%的长尾记忆召回率。
4. 实战性能分析
4.1 基准测试结果
| 数据集 | 记忆规模 | RF-Mem Acc. | Top-K Acc. | 延迟(ms) |
|---|---|---|---|---|
| PersonaMem | 32K | 0.635 | 0.557 | 5.09 |
| PersonaBench | 128K | 0.539 | 0.462 | 8.21 |
| LongMemEval | 1M | 0.459 | 0.387 | 12.45 |
关键发现:
- 在1M规模的超长记忆场景下,RF-Mem仍保持可用性,而全量记忆方法已超出上下文窗口限制
- 随着记忆规模扩大,Recollection路径的触发率从32K时的18%升至1M时的34%
4.2 典型用例解析
案例背景:用户有长达2年的健康管理交互历史,包含:
- 2025/03:开始尝试生酮饮食
- 2025/07:因头晕恢复碳水摄入
- 2026/01:开始定期健身
查询:"我现在应该采取哪种饮食方案?"
传统Top-K检索可能只匹配到最近的健身记录,而RF-Mem的Recollection路径会:
- 首先捕捉到"生酮饮食"相关记忆
- 通过聚类发现"头晕"和"恢复碳水"的关联簇
- 最终生成包含完整因果链的记忆上下文
5. 工程落地指南
5.1 部署建议
-
硬件配置:
- 推荐使用带FP16加速的GPU(如RTX 4090)
- 内存容量应为记忆库大小的1.5倍
-
参数调优:
- 初始探针检索数量:记忆库规模的平方根
- K-means聚类数:√N(N为候选记忆数)
- 最大迭代次数:根据延迟预算调整(通常3-5轮)
-
监控指标:
- Familiarity路径命中率(健康值40-60%)
- 平均回忆深度(理想值2-3层)
5.2 常见问题排查
问题1:Recollection路径耗时突增
- 检查记忆embedding是否需重新归一化
- 验证聚类算法是否出现维度灾难
问题2:重要记忆未被召回
- 调整Familiarity阈值(降低μ或提高H)
- 增加探针检索的召回宽度
问题3:结果包含无关记忆
- 在混合查询向量时降低centroid权重(0.4→0.3)
- 添加基于时间的衰减因子
6. 进阶发展方向
RF-Mem当前仍有一些待突破的挑战:
- 跨模态记忆:支持图像、语音等非文本记忆的联合检索
- 动态遗忘机制:自动淘汰过时或低价值记忆
- 联邦学习适配:在隐私计算场景下的分布式记忆检索
在实际部署中,我们发现将RF-Mem与以下技术组合使用效果更佳:
- 记忆重要性预测模型(提前过滤低价值记忆)
- 对话状态跟踪器(提供检索上下文)
- 轻量级推理加速框架(如TensorRT)
这种"慢回忆"机制或许暗示着AI发展的一个新方向:不是追求更快的计算,而是学会像人类一样,在需要时进行有深度的思考。当你的AI助手能真正"回想"起半年前那次关于咖啡因敏感度的谈话,而不仅仅是匹配关键词时,个性化交互才真正具备了记忆的温度。