
1. 目标检测基础概念解析
目标检测作为计算机视觉领域的核心任务之一,其本质是在图像中同时完成目标定位和分类两项工作。与简单的图像分类不同,目标检测需要回答三个关键问题:图像中有什么物体?这些物体在哪里?它们属于什么类别?
1.1 目标检测的核心要素
在实际应用中,目标检测的输出通常包含以下信息:
- 边界框坐标(Bounding Box):标记物体位置的矩形区域
- 类别标签(Class Label):识别物体的具体类别
- 置信度得分(Confidence Score):模型对检测结果的把握程度
以自动驾驶场景为例,系统需要准确检测出行人、车辆、交通标志等目标的位置和类别,才能做出正确的驾驶决策。这种能力使得目标检测成为许多AI应用的基础模块。
1.2 边界框的表示方法
边界框的表示主要有两种形式:
-
极坐标表示法:(x_min, y_min, x_max, y_max)
- 直接定义矩形框的左上角和右下角坐标
- 优点:直观易懂,计算IOU(交并比)方便
- 示例代码:
python复制# 极坐标表示示例 bbox = [100, 150, 300, 400] # x_min, y_min, x_max, y_max
-
中心点表示法:(x_center, y_center, width, height)
- 定义矩形框的中心点坐标和宽高
- 优点:便于进行尺度不变性变换
- 示例代码:
python复制# 中心点表示示例 bbox = [200, 275, 200, 250] # x_center, y_center, width, height
提示:在实际项目中,两种表示方法经常需要相互转换。建议编写专门的转换函数来统一处理。
1.3 主流目标检测数据集
1.3.1 PASCAL VOC数据集
PASCAL VOC(Visual Object Classes)是早期最具影响力的目标检测基准数据集:
- 包含20个常见物体类别
- 约11,000张训练图像
- 27,000个标注对象实例
- 提供物体类别标签和边界框标注

1.3.2 MS COCO数据集
MS COCO(Microsoft Common Objects in Context)是目前最全面的目标检测数据集:
- 80个物体类别
- 超过33万张图像
- 250万个标注实例
- 除边界框外还提供像素级分割标注
- 包含复杂的日常场景和遮挡情况

在实际项目中,COCO数据集因其规模和多样性成为模型性能评估的黄金标准。许多SOTA(State-of-the-Art)模型都在COCO上报告其性能指标。
2. 目标检测的核心评价指标
2.1 IoU(交并比)
IoU(Intersection over Union)是衡量预测框与真实框重合程度的重要指标:
code复制IoU = Area of Overlap / Area of Union

在实际应用中:
- IoU > 0.5 通常被认为是有效检测
- 更严格的任务(如人脸检测)可能要求 IoU > 0.7
- 计算代码示例:
python复制def calculate_iou(box1, box2): # box格式:[x1,y1,x2,y2] x1 = max(box1[0], box2[0]) y1 = max(box1[1], box2[1]) x2 = min(box1[2], box2[2]) y2 = min(box1[3], box2[3]) intersection = max(0, x2-x1) * max(0, y2-y1) area1 = (box1[2]-box1[0])*(box1[3]-box1[1]) area2 = (box2[2]-box2[0])*(box2[3]-box2[1]) union = area1 + area2 - intersection return intersection / union
2.2 mAP(平均精度均值)
mAP(mean Average Precision)是目标检测中最核心的评价指标:
-
首先计算每个类别的AP(Average Precision):
- 在不同置信度阈值下计算精确率(Precision)和召回率(Recall)
- 绘制PR曲线并计算曲线下面积
-
对所有类别的AP取平均得到mAP
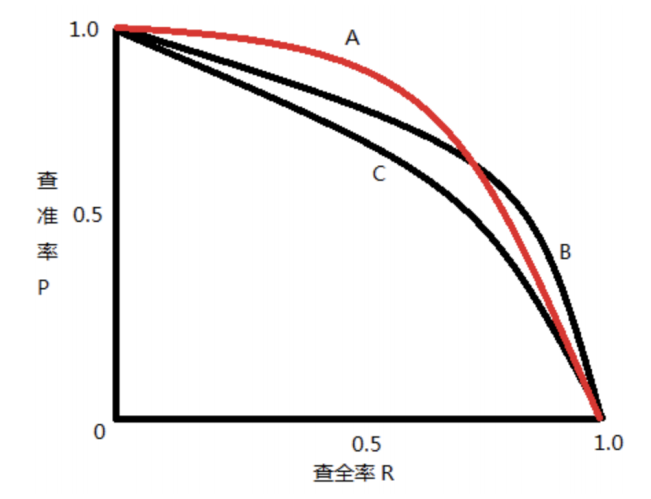
在COCO评估中,还细分为:
- mAP@0.5: IoU阈值为0.5时的mAP
- mAP@0.5:0.95: IoU阈值从0.5到0.95(步长0.05)的平均mAP
2.3 NMS(非极大值抑制)
NMS(Non-Maximum Suppression)是后处理中去除冗余检测框的关键算法:
算法步骤:
- 按置信度分数对所有检测框排序
- 选择分数最高的框,保留
- 计算该框与其余框的IoU,删除IoU大于阈值的框
- 重复步骤2-3直到处理完所有框

实现代码示例:
python复制def nms(boxes, scores, threshold):
# boxes: [N,4], scores: [N]
keep = []
order = scores.argsort()[::-1]
while order.size > 0:
i = order[0]
keep.append(i)
ious = calculate_iou(boxes[i], boxes[order[1:]])
inds = np.where(ious <= threshold)[0]
order = order[inds + 1]
return keep
注意:NMS阈值的选择需要平衡召回率和精度。过高的阈值会导致漏检,过低则会产生重复检测。
3. 两阶段检测器:R-CNN系列
3.1 R-CNN:开创性工作
R-CNN(Region-based CNN)是首个成功将CNN应用于目标检测的算法,其流程如下:
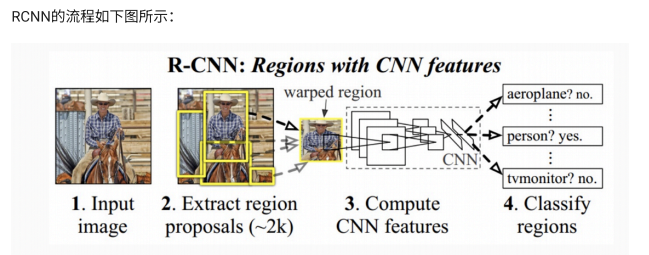
3.1.1 关键技术细节
-
区域提议生成(Selective Search):
- 基于颜色、纹理、大小等特征合并相似区域
- 每张图像生成约2000个候选区域
- 候选区域形状不规则,需要变形为固定尺寸(通常227×227)
-
特征提取:
- 使用预训练CNN(如AlexNet)提取4096维特征
- 特征保存到磁盘供后续使用
- 微调CNN时,将ImageNet的1000类输出改为N+1类(N个目标类+背景)
-
分类器训练:
- 为每个类别训练独立的SVM分类器
- 正样本:与真实框IoU>0.3的提议区域
- 负样本:IoU<0.3的区域
-
边界框回归:
- 训练线性回归模型修正提议框位置
- 输入:CNN提取的特征
- 输出:边界框的平移和缩放参数
3.1.2 R-CNN的局限性
-
计算冗余:
- 每个候选区域独立通过CNN,重复计算严重
- VGG16处理一张图像需要47秒(GPU)
-
存储问题:
- 5000张图像的特征文件可达数百GB
-
训练复杂:
- 需要分阶段训练CNN、SVM和回归器
- 微调与SVM训练的正负样本定义不一致
3.2 Fast R-CNN:效率提升
Fast R-CNN针对R-CNN的低效问题进行了重要改进:

3.2.1 核心创新
-
ROI Pooling:
- 整图通过CNN得到特征图
- 将候选区域映射到特征图上
- 使用最大池化将不同大小的ROI转换为固定尺寸(如7×7)
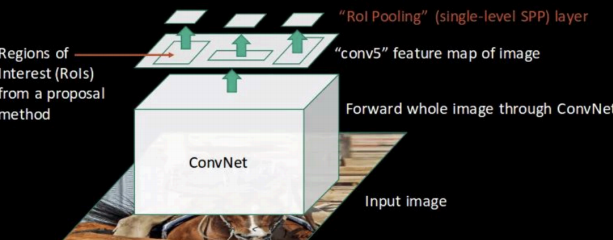
-
多任务损失:
- 分类和回归统一在一个网络中
- 损失函数 = 分类损失 + 回归损失
- 端到端训练,无需分阶段
-
全连接加速:
- 使用SVD分解全连接层参数
- 在精度损失很小的情况下大幅减少计算量
3.2.2 性能对比
| 指标 | R-CNN | Fast R-CNN | 提升幅度 |
|---|---|---|---|
| 训练时间(小时) | 84 | 9.5 | 8.8x |
| 测试时间(秒/图) | 47 | 0.32 | 146x |
| mAP(%) | 66.0 | 66.9 | +0.9 |
3.3 Faster R-CNN:端到端检测
Faster R-CNN通过引入RPN(Region Proposal Network)实现了真正的端到端检测:
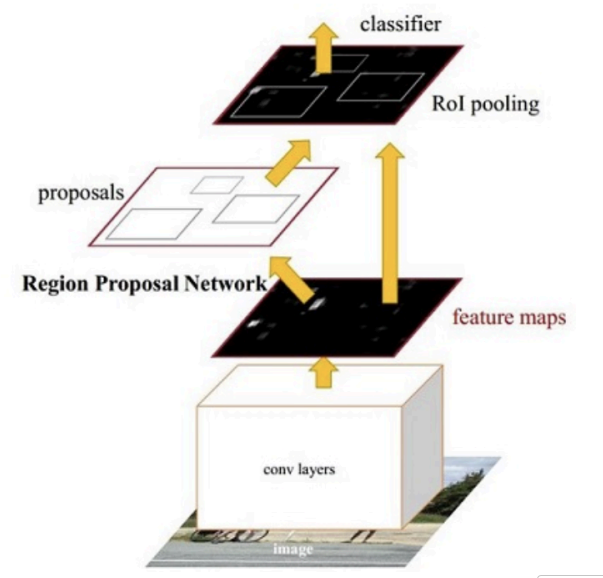
3.3.1 RPN网络详解
RPN的核心思想是"锚点"(Anchor)机制:
-
锚点设计:
- 每个位置设置k个不同尺度和长宽比的锚点(通常k=9)
- 典型配置:尺度[8,16,32],长宽比[0.5,1,2]
- 对于H×W的特征图,共产生H×W×k个锚点
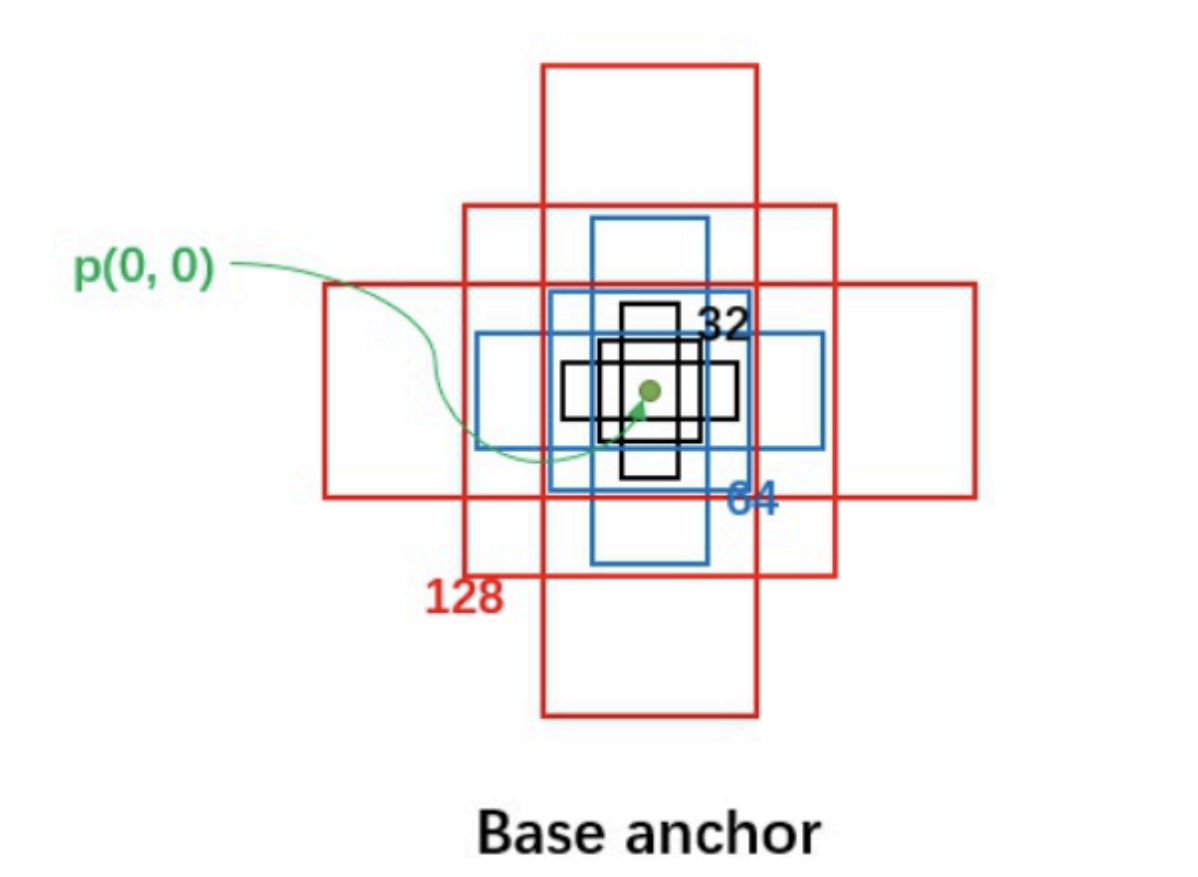
-
双任务学习:
- 分类分支:判断锚点是否包含物体(二分类)
- 回归分支:预测边界框调整参数(Δx,Δy,Δw,Δh)
-
损失函数:
code复制L({pi},{ti}) = (1/Ncls)∑Lcls(pi,pi*) + λ(1/Nreg)∑pi*Lreg(ti,ti*)- pi:锚点i是物体的预测概率
- pi*:真实标签(1=正样本,0=负样本)
- ti:预测的边界框参数
- ti*:真实的边界框参数
3.3.2 FPN特征金字塔
现代Faster R-CNN常结合FPN(Feature Pyramid Network)提升多尺度检测能力:
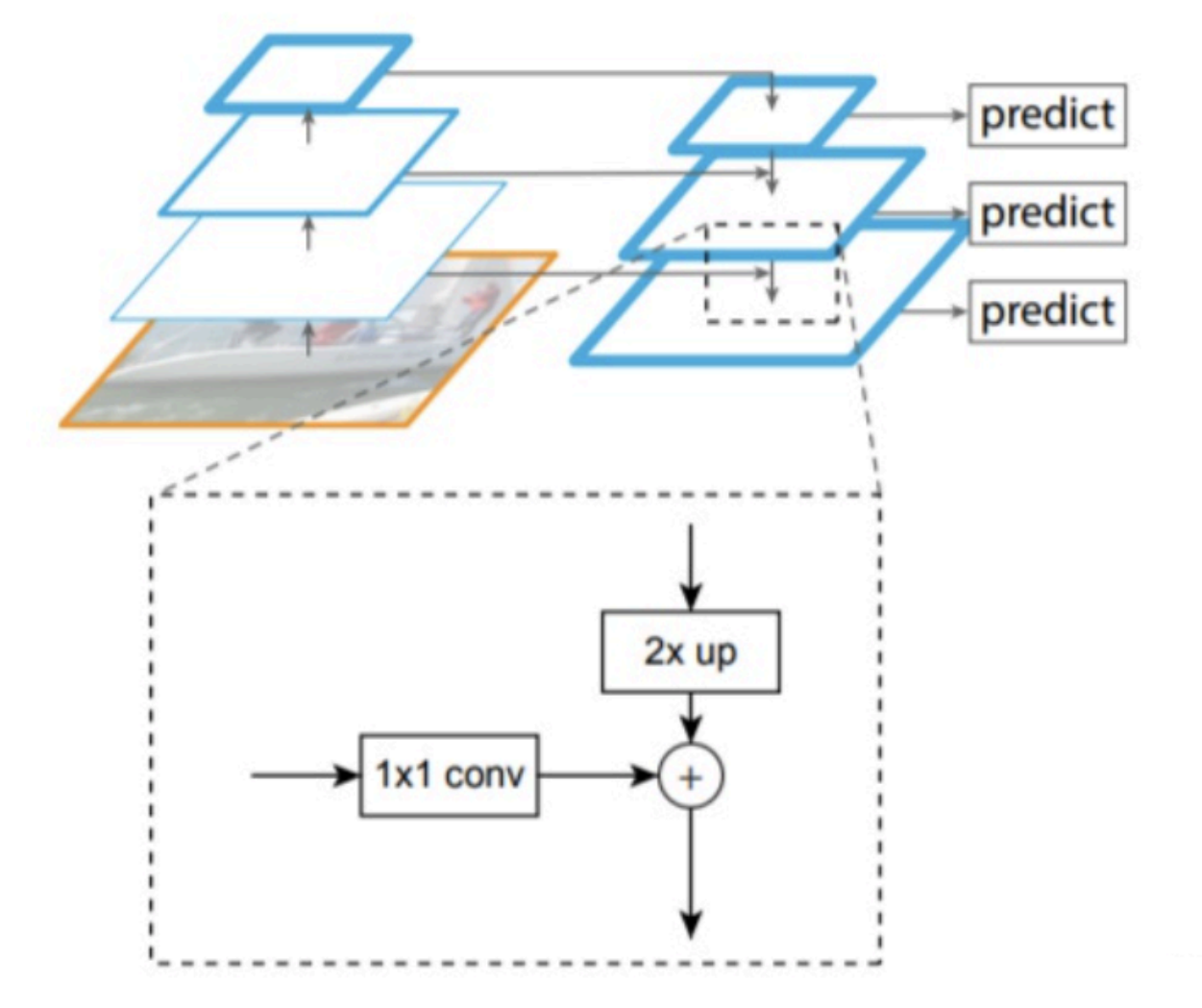
FPN的核心特点:
- 自顶向下路径:将高层语义信息传递到低层
- 横向连接:融合不同分辨率的特征
- 分层预测:不同尺度的ROI分配到不同层处理
3.3.3 性能优势
-
速度大幅提升:
- RPN替代Selective Search,提案生成仅需10ms
- 整体检测速度达到5fps(VGG16)
-
精度提高:
- COCO mAP@0.5:0.95达到42.7%
- 对小物体检测效果显著改善
-
完全端到端:
- 单一卷积网络统一提案生成和目标检测
- 简化训练流程,提升模型一致性
4. 实践建议与经验分享
4.1 模型选型考量
在实际项目中,选择R-CNN系列模型时需要考虑:
-
精度优先场景:
- 选择Faster R-CNN with FPN
- 使用ResNet-101等强大backbone
- 适当增加训练迭代次数
-
速度敏感场景:
- 使用轻量级backbone(如MobileNet)
- 减少RPN提案数量(如从300减至100)
- 考虑量化压缩模型
-
小目标检测:
- 必须使用FPN结构
- 增大输入图像分辨率
- 调整anchor的尺度设置
4.2 训练技巧
-
数据增强策略:
- 随机水平翻转(基本)
- 多尺度训练(短边随机缩放)
- 颜色抖动(亮度、对比度等)
-
正负样本平衡:
- RPN中按IoU划分正负样本
- 困难样本挖掘(OHEM)
- 分类损失使用focal loss缓解类别不平衡
-
学习率调度:
- 热身(Warmup)策略
- 余弦退火学习率
- 分层学习率(backbone较小)
4.3 常见问题排查
-
验证集表现差:
- 检查训练/验证数据分布是否一致
- 确认数据增强没有过度
- 验证标注质量
-
损失震荡:
- 适当降低学习率
- 增大batch size
- 检查梯度裁剪
-
过拟合:
- 增加正则化(Dropout, Weight decay)
- 使用更多训练数据
- 早停(Early Stopping)
4.4 部署优化
-
模型压缩:
- 知识蒸馏(使用大模型指导小模型)
- 通道剪枝(移除不重要的滤波器)
- 量化(FP32→INT8)
-
推理加速:
- TensorRT优化
- 使用C++实现部署
- 多batch并行处理
-
内存优化:
- 使用ROI对齐替代ROI池化
- 优化特征图缓存
- 分块处理超大图像
在实际项目中,我们通常需要根据具体硬件条件和实时性要求,在模型精度和推理速度之间找到平衡点。Faster R-CNN虽然不再是速度最快的检测模型,但其优秀的检测精度和成熟的生态体系,使其在许多对精度要求较高的场景中仍然是首选方案。