
1. 广告竞价环境建模的现状与挑战
在数字广告领域,自动出价技术已经成为广告主实现营销目标的核心工具。当前主流的自动出价算法(如基于线性规划、PID控制器或强化学习的方法)虽然能够在一定程度上模拟竞价环境,但它们都存在一个根本性缺陷——场景泛化能力不足。这些方法通常针对特定广告场景(如搜索广告、展示广告或视频广告)进行优化,当部署到其他场景时,性能往往大幅下降。
这种局限性源于几个关键因素:首先,不同广告场景的数据结构差异显著,包括时间序列数据、点数据、离散数据和连续数据的混合;其次,竞价环境本质上是一个多智能体博弈系统,变量间的依赖关系随时间动态变化;最后,竞价数据特有的"零膨胀"分布(由于未赢得曝光导致的零值过多)与传统神经网络假设的正态分布不符。这些因素共同导致了现有方法难以构建通用的竞价环境模型。
2. Bid2X模型的核心设计理念
2.1 基础模型视角的创新
Bid2X的创新之处在于首次将基础模型(Foundation Model)的概念引入竞价环境建模。与传统的"一个场景一个模型"范式不同,基础模型通过在大量多样化数据上预训练,能够捕捉不同场景背后的通用规律。这类似于自然语言处理中的大型语言模型,通过海量文本学习语言的通用表征,然后可以适配到各种下游任务。
在广告竞价场景中,这种通用规律包括:
- 边际收益递减:出价增加带来的效果提升会逐渐减缓
- 时间邻近性:相近时间段的竞价行为具有相关性
- 周期性:广告效果会呈现天/周级别的重复模式
- 成本效益原则:高性价比的曝光通常带来更好的广告效果
2.2 三大技术挑战的解决方案
针对前文提到的三大挑战,Bid2X提出了系统性的解决方案:
2.2.1 异构数据统一编码
模型设计了双路径嵌入机制:
- 历史数据路径:将每个变量(如成本、点击量)独立编码为序列嵌入,保留变量特性
- 当天数据路径:将每个时间步的所有变量值编码为一个Token,捕捉时间动态性
这种设计巧妙地解决了不同类型数据(时间序列vs点数据、离散vs连续)的统一表示问题。具体实现时,对历史数据采用变量级嵌入投影,对当天数据则采用时间步级嵌入,并通过精细的掩码机制防止信息泄露。
2.2.2 动态依赖关系建模
Bid2X创新性地提出了双重注意力机制:
- 变量注意力:将不同变量的嵌入作为Token,学习变量间的相关性图谱
- 时间注意力:将不同时间步的嵌入作为Token,采用因果掩码捕捉时间依赖性
这种设计使得模型能够同时理解"在某一时刻,哪些变量相互影响"以及"同一变量如何随时间演变"。特别地,时间注意力采用严格的下三角掩码矩阵,确保预测时不会窥见未来信息,符合实际业务场景。
2.2.3 零膨胀分布处理
针对竞价数据中大量零值的特性,模型设计了零膨胀投影层:
- 二元分类器预测目标值是否为零
- 回归器预测非零时的具体数值
- 联合优化分类损失(交叉熵)和回归损失(MSE)
这种设计使模型能够显式地处理零值过多的问题,而不是简单地将它们视为异常值。理论分析表明,这种结构可以确保预测结果收敛到真实的零膨胀分布。
3. 模型架构与技术实现细节
3.1 整体架构设计
Bid2X采用编码器-解码器结构,但进行了针对性创新:
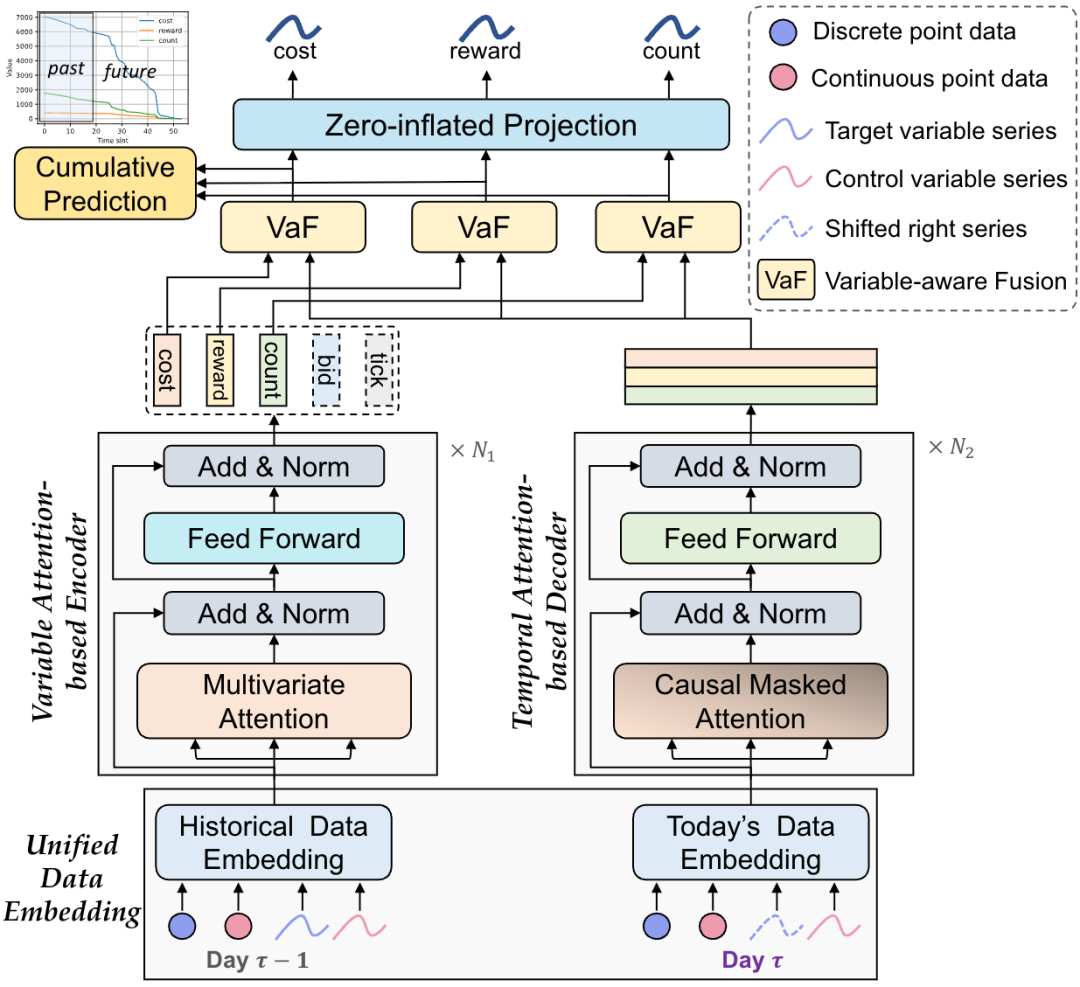
- 编码器:基于变量注意力的Transformer块,处理历史数据
- 解码器:基于时间注意力的Transformer块,处理当天数据
- 融合模块:变量感知的门控机制,动态整合两种表征
- 输出层:零膨胀投影+累积预测辅助任务
3.2 关键技术创新点
3.2.1 变量感知融合机制
传统多模态融合通常采用简单拼接或加权求和,而Bid2X设计了更精细的融合策略:
- 从变量注意力编码器提取目标变量相关表征
- 为每个目标变量生成独立的融合门控信号
- 使用Sigmoid门控制时间表征的融合程度
数学表示为:
code复制g_i = σ(MLP([h_i^{var}, H^{time}]))
h_i^{fuse} = g_i ⊙ h_i^{var} + (1-g_i) ⊙ H^{time}
其中⊙表示逐元素乘法。这种设计保持了不同目标变量的预测路径相对独立,增强了模型的表达能力。
3.2.2 自监督辅助任务
除了主预测任务,模型还增加了两个辅助任务:
- 零膨胀预测:联合优化分类和回归损失
- 累积效果预测:预测从当前时刻到活动结束的累积效果
这些任务不仅提供了额外的监督信号,更重要的是使模型能够从不同时间尺度理解竞价环境。特别是累积预测任务,强制模型建立长期视角,避免过度拟合短期波动。
3.3 训练策略与优化
模型采用多任务联合训练框架:
code复制L_total = L_zip + λL_cfp
其中λ是平衡超参数。实际训练中发现:
- 渐进式训练(先预训练编码器)能提升稳定性
- 梯度裁剪对处理数据异质性很重要
- 学习率热启有助于避免早期过拟合
在淘宝广告场景的实际部署中,模型使用超过1亿条竞价轨迹进行训练,batch size设置为1024,采用AdamW优化器,在8张A100 GPU上训练约2天收敛。
4. 实验评估与实际效果
4.1 离线实验设置
评估使用了淘宝广告平台的8个真实数据集:
- 覆盖搜索广告、推荐广告、展示广告等不同场景
- 包含1亿+竞价轨迹,300万+竞价记录
- 评估指标:MAE(平均绝对误差)、RMSE(均方根误差)
基线方法包括:
- 传统时间序列模型(ARIMA、Prophet)
- 深度学习模型(LSTM、Transformer)
- 专用竞价模型(RL-Bid、LP-Bid)
- 基础模型版Informer
4.2 主要实验结果
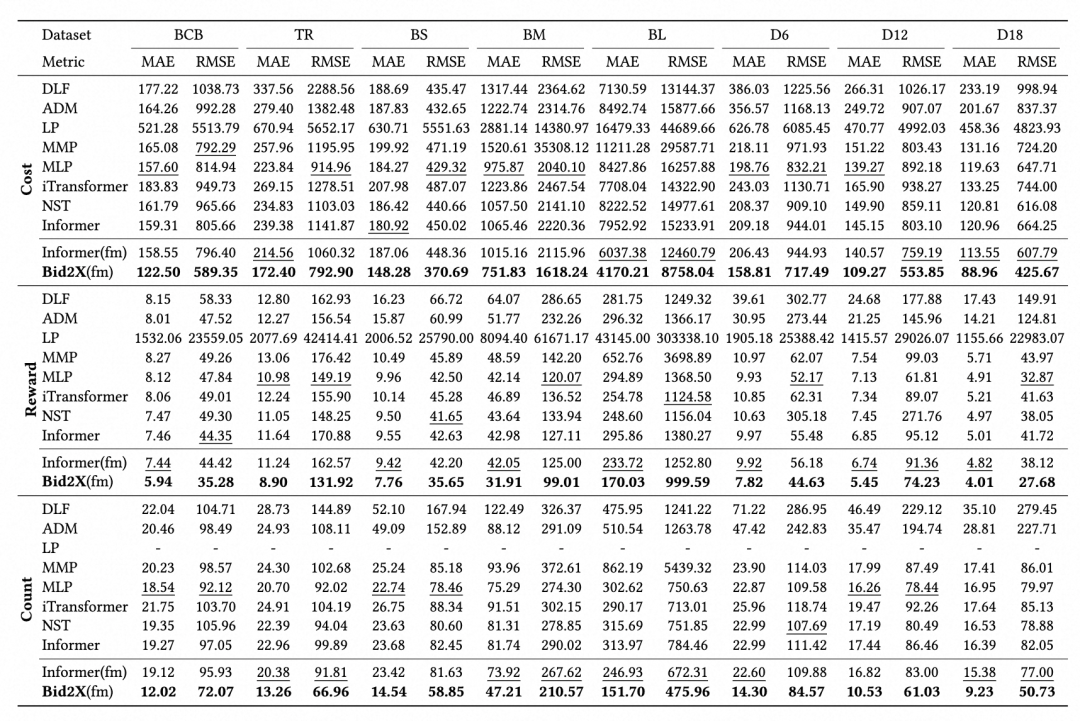
关键发现:
- Bid2X在所有数据集上均优于基线方法,MAE平均降低23.7%
- 在数据分布差异大的场景(如BL数据集),优势更明显(提升31.2%)
- 基础模型版Informer表现优于传统方法,但仍不及Bid2X
4.3 消融实验分析
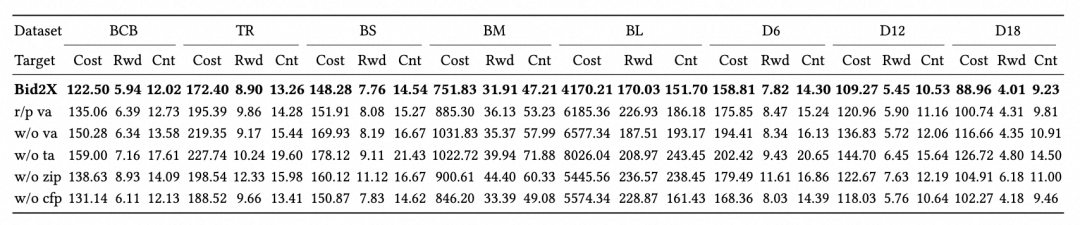
各组件贡献度:
- 变量注意力:对MAE影响最大(移除后性能下降18.3%)
- 时间注意力:尤其在动态强的场景关键
- 零膨胀处理:对点击率预测等稀疏指标尤为重要
- 累积预测:提升长期预测稳定性
4.4 在线A/B测试结果
在淘宝广告平台部署后,关键指标提升:
- GMV(总交易额):+4.65%
- ROI(投资回报率):+2.44%
- 预算消耗效率:+3.12%
- 曝光质量:CTR提升1.87%

值得注意的是,这些提升是在不增加广告主预算的前提下实现的,完全通过更智能的出价策略分配预算。实际业务中,这意味着平台可以为广告主创造更多价值,同时改善用户体验(减少低效曝光)。
5. 扩展分析与应用前景
5.1 模型的可扩展性
作为基础模型,Bid2X展现出良好的scaling law特性:
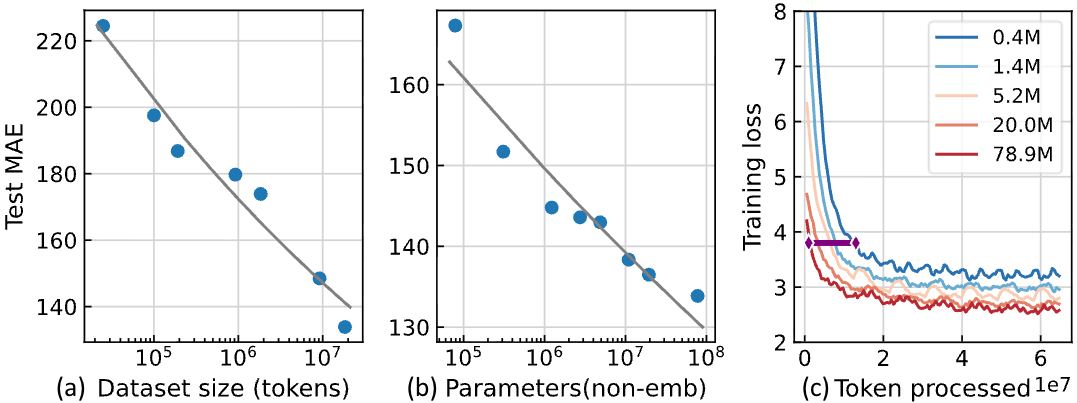
- 模型性能随数据量增加持续提升(未出现平台期)
- 更大模型具有更高样本效率(达到相同性能所需数据更少)
- 训练损失收敛速度与模型规模正相关
这表明Bid2X架构适合继续扩大规模,未来可以通过增加参数量和训练数据进一步提升性能。
5.2 实际部署考量
在工业级系统部署时,需要特别关注:
- 实时性要求:预测延迟需控制在50ms以内
- 解决方案:模型轻量化、缓存机制
- 数据新鲜度:竞价环境变化快,需要持续更新
- 解决方案:增量学习pipeline
- 冷启动问题:新广告主/活动缺乏历史数据
- 解决方案:元学习+跨活动迁移
5.3 未来研究方向
基于Bid2X的成功,我们认为有几个有前景的方向:
- 多模态基础模型:整合文本、图像等广告内容信息
- 因果推理能力:区分相关性和因果性,避免虚假关联
- 可解释性工具:帮助运营人员理解模型决策
- 联邦学习框架:在保护数据隐私的前提下联合建模
在实际业务中,我们已经开始探索将这些技术与Bid2X结合,初步结果显示在长尾场景有显著提升。