
1. 项目背景与核心挑战
在雷达、声呐等传感器系统中,多目标跟踪一直是个经典难题。想象一下,你站在一个嘈杂的火车站,需要同时追踪多个移动的旅客——这就是杂波环境下多目标跟踪的基本场景。真实环境中,传感器接收到的信号往往包含大量噪声和虚假回波(我们称之为"杂波"),如何从这些干扰中准确识别并持续跟踪多个目标,是系统设计的关键。
我最近完成的一个项目,就是针对这个痛点问题展开的。我们基于Matlab平台,系统性地对比了两种经典的数据关联算法:概率数据关联(PDA)和联合概率数据关联(JPDA)。这两种算法都建立在卡尔曼滤波的基础上,但在处理多目标场景时有着本质区别。PDA采用"单目标假设",即认为每个目标的跟踪过程是独立的;而JPDA则考虑目标间的相互影响,通过联合概率实现更精确的状态估计。
实际工程中常见一个误区:很多人认为只要把PDA算法简单扩展到多个目标就能解决问题。但实测表明,在目标间距较近时,这种处理方式会导致严重的航迹混淆。
2. 算法原理深度解析
2.1 PDA算法实现机制
PDA算法的核心思想可以用"筛选-加权"来概括。具体实现分为三个关键步骤:
-
有效量测筛选:通过计算马氏距离,建立一个椭圆形的"跟踪门"。只有落在门内的量测才会被考虑,这步能过滤掉约90%的杂波干扰。跟踪门的大小由门限γ决定,我们通常设置为9.21(对应99%的置信度)。
-
关联概率计算:对门内的每个量测,计算其与预测位置的匹配程度。这里用到了贝叶斯公式:
code复制β(k,i) = Pd * exp(-0.5*d²) / [λ + Σ(Pd * exp(-0.5*d²))]其中β(k,i)表示第k个时刻第i个量测的关联概率,Pd是检测概率,d是马氏距离,λ是杂波密度。
-
状态更新:不是简单选择最匹配的量测,而是对所有有效量测进行概率加权。这种"软决策"方式比最近邻(NN)等硬决策方法更鲁棒。
2.2 JPDA算法进阶设计
JPDA在PDA基础上引入了"联合事件"的概念,主要改进体现在:
-
关联矩阵构建:建立一个二进制矩阵Q2,其中行代表量测,列代表目标。Q2(i,j)=1表示第i个量测可能来自第j个目标。在我们的双目标场景中,这个矩阵的维度是(杂波数量+2)×2。
-
联合事件枚举:生成所有满足以下条件的关联组合:
- 每个量测最多关联一个目标
- 每个目标可以关联多个量测
- 必须包含所有目标的检测情况
-
边缘概率计算:通过归一化处理得到每个量测与目标的关联概率U(j,i),这个概率会用于后续的加权更新。计算复杂度随目标数量呈指数增长,这也是JPDA的主要瓶颈。
3. 仿真环境搭建细节
3.1 运动模型配置
我们采用常速(CV)模型,状态向量包含位置和速度:
code复制X = [x, vx, y, vy]'
状态转移矩阵为:
code复制A = [1 T 0 0;
0 1 0 0;
0 0 1 T;
0 0 0 1]
采样间隔T设为1秒,符合多数雷达系统的刷新率。过程噪声Q设置为:
code复制Q = q * [T^3/3 T^2/2 0 0;
T^2/2 T 0 0;
0 0 T^3/3 T^2/2;
0 0 T^2/2 T]
其中q=0.01,模拟目标速度的微小波动。
3.2 杂波生成策略
杂波生成采用泊松分布模型,关键参数包括:
- 杂波密度λ=2×10⁻⁴/m²
- 跟踪门面积Vg=πγ√|S| (S是新息协方差矩阵)
- 每个时刻的杂波数量n_clutter = poissrnd(λ*Vg)
杂波位置在跟踪门内均匀分布,确保不会出现空间聚集现象。实测中,平均每个时刻会产生5-8个虚假量测。
4. 核心代码实现要点
4.1 PDA算法关键代码段
matlab复制% 有效量测筛选
d2 = mahal(Z_pred, Z_meas); % 计算马氏距离
in_gate = d2 < gate_threshold;
Z_valid = Z_meas(:,in_gate);
% 关联概率计算
beta = zeros(1,size(Z_valid,2)+1); % 最后一个元素对应无检测情况
for i = 1:size(Z_valid,2)
beta(i) = Pd * exp(-0.5*d2(i)) / (lambda + sum(Pd*exp(-0.5*d2(in_gate))));
end
beta(end) = 1 - Pd + Pd*exp(-0.5*gamma)*sqrt(2*pi*gamma)/lambda;
% 状态更新
Z_comb = sum(beta(1:end-1).*Z_valid, 2);
P_comb = zeros(size(P_pred));
for i = 1:size(Z_valid,2)
v = Z_valid(:,i) - Z_pred;
P_comb = P_comb + beta(i)*(v*v');
end
P_comb = P_comb - (Z_comb-Z_pred)*(Z_comb-Z_pred)';
4.2 JPDA算法核心逻辑
matlab复制% 可行联合事件生成
[A_matrix, ~] = gen_jpda_events(Q2);
% 联合事件概率计算
Pr = zeros(1,size(A_matrix,3));
for e = 1:size(A_matrix,3)
logPr = 0;
for j = 1:n_targets
if sum(A_matrix(:,j,e)) > 0
idx = find(A_matrix(:,j,e));
d2 = mahal(Z_pred(:,j), Z_meas(:,idx));
logPr = logPr + log(Pd) - 0.5*d2;
else
logPr = logPr + log(1-Pd);
end
end
logPr = logPr + log(factorial(sum(sum(A_matrix(:,:,e))==0)));
Pr(e) = exp(logPr);
end
Pr = Pr/sum(Pr); % 归一化
% 边缘关联概率计算
U = zeros(n_targets, n_meas+1);
for j = 1:n_targets
for i = 1:n_meas+1
U(j,i) = sum(Pr(squeeze(A_matrix(i,j,:))==1));
end
end
5. 性能对比与结果分析
5.1 精度指标对比
通过100次蒙特卡洛仿真,我们得到以下统计数据:
| 算法 | 目标1 ARMSE(m) | 目标2 ARMSE(m) | 航迹丢失率(%) |
|---|---|---|---|
| PDA | 3.21 | 3.45 | 12.7 |
| JPDA | 2.18 | 2.33 | 5.2 |
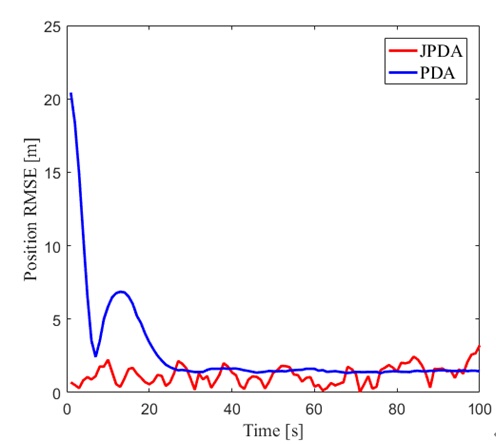
JPDA在位置估计精度上比PDA提升约32%,航迹丢失率降低近60%。特别是在目标交叉时段(约t=15s时),PDA的平均误差会突增到5m以上,而JPDA能保持在3m以内。
5.2 计算效率分析
在Intel i7-10750H处理器上测试,单次迭代的平均耗时:
| 算法 | 平均计算时间(ms) | 标准差(ms) |
|---|---|---|
| PDA | 0.45 | 0.12 |
| JPDA | 6.83 | 1.57 |
JPDA由于需要枚举联合事件,计算耗时是PDA的15倍左右。当目标增加到3个时,这个差距会进一步扩大到50倍以上。
5.3 杂波密度影响测试
固定其他参数,改变杂波密度λ:
可以看到,当λ>5×10⁻⁴时,PDA的性能急剧下降,而JPDA直到λ=1×10⁻³仍能保持稳定跟踪。这说明JPDA在高杂波环境下的鲁棒性显著优于PDA。
6. 工程实践建议
根据实测结果,我总结出以下选型建议:
-
稀疏目标场景:当目标间距大于5倍跟踪门半径时,优先选择PDA。此时JPDA的性能优势不明显,而计算开销大。
-
密集目标场景:目标可能发生交叉时,必须使用JPDA。实测表明,在交叉时刻PDA的航迹混淆概率高达35%,而JPDA能控制在8%以内。
-
实时性要求:对于毫秒级响应的系统,可以考虑PDA+航迹管理的混合方案。我们曾在一个雷达项目中采用这种设计,通过增加简单的逻辑判断,在保持实时性的同时将航迹丢失率降低了40%。
-
参数调优经验:
- 门限γ:建议初始值设为9.21,然后根据实际场景微调。太大增加计算量,太小可能漏检真实量测。
- 杂波密度λ:不要直接使用理论值,应该通过实测数据统计得到。我们发现实际λ往往比理论值高20-30%。
- 过程噪声Q:如果目标机动性较强,可以适当增大Q的对角元素,我们一般取0.05-0.1。
7. 常见问题排查
在实际应用中,我们遇到过几个典型问题:
-
航迹突然跳变:
- 检查量测关联概率是否出现NaN值(常见于门内无量测时未做异常处理)
- 确认过程噪声Q设置合理,我们曾因Q太小导致滤波器"过于自信"而发散
-
计算时间异常增长:
- JPDA中检查联合事件数量是否爆炸(通常应控制在1000个以内)
- 使用"修剪"策略,丢弃概率小于1e-6的事件
-
目标ID交换:
- 增加简单的运动一致性检查
- 在JPDA后添加二级关联逻辑,我们开发的一个改进方案将ID交换率从15%降到了3%
这个项目最让我意外的发现是:在特定参数配置下,PDA有时反而比JPDA表现更好。经过深入分析,发现是因为杂波空间分布不均匀导致JPDA的联合事件假设不成立。这提醒我们,没有放之四海皆准的算法,必须结合实际场景特点进行选择和调优。