
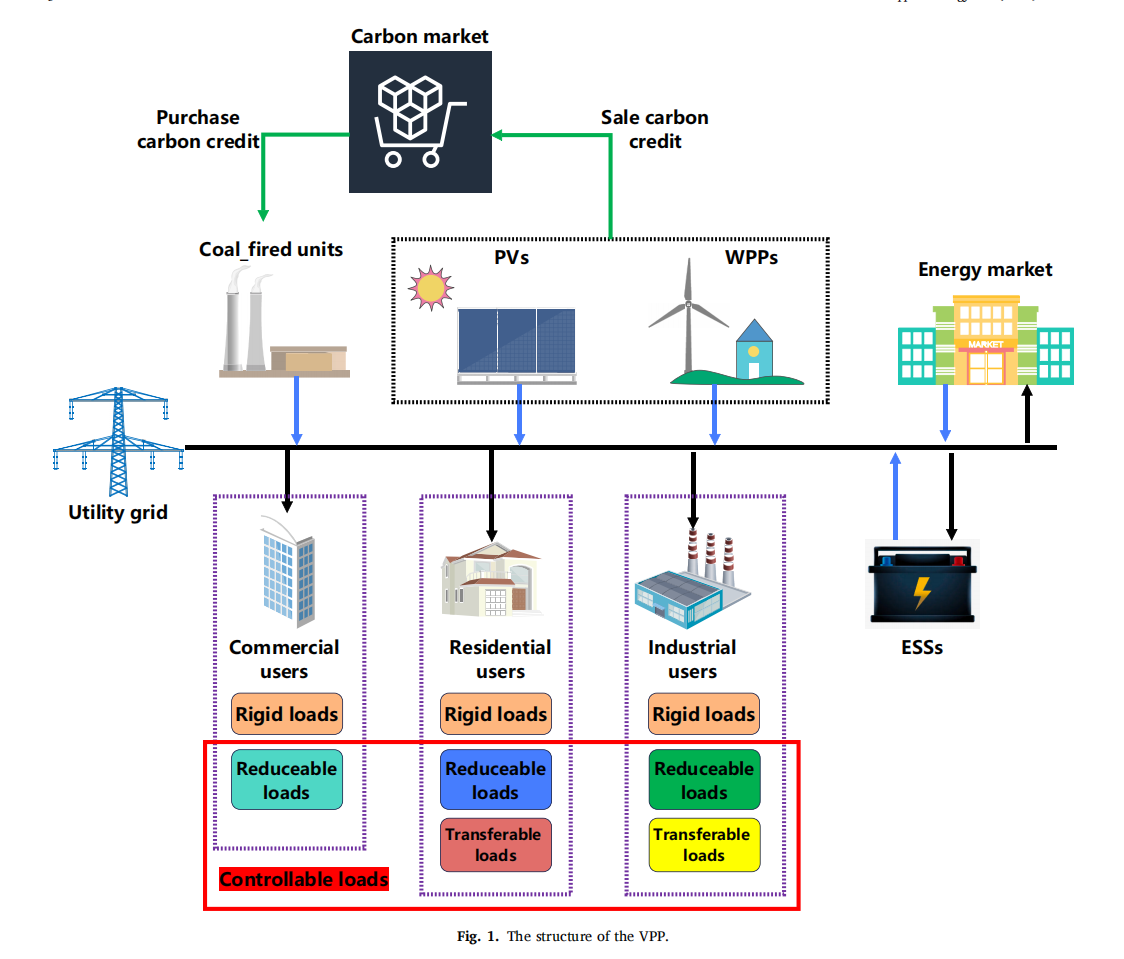
1. 项目概述
在能源转型的大背景下,高比例可再生能源并网已成为全球电力系统发展的必然趋势。然而,风电、光伏等可再生能源的间歇性和波动性给电网运行带来了巨大挑战。作为一名长期从事电力系统优化研究的工程师,我在实际项目中深刻体会到:如何平衡系统灵活性与储能投资成本,是当前行业面临的核心难题之一。
虚拟电厂(Virtual Power Plant, VPP)作为聚合分布式资源的新型运营模式,为解决这一问题提供了创新思路。不同于传统电厂,VPP通过先进的信息通信技术,将分散的可再生能源、储能系统、可控负荷等资源"虚拟"整合,形成一个可统一调度的"云电厂"。但要让这个概念真正落地,还需要突破三大技术瓶颈:
- 资源聚合的灵活性:如何经济高效地获取足够的调节能力
- 用户响应的精准性:如何激发不同类型用户的参与积极性
- 储能老化的可预测性:如何延长储能寿命以降低全生命周期成本
本文复现的这项顶级SCI研究,正是针对这三个痛点提出了系统性的解决方案。通过Matlab代码实现,我们将深入剖析其技术路线和实现细节,为从业者提供可直接参考的实践指南。
2. 核心问题与技术路线
2.1 灵活性缺口的经济填补方案
传统解决灵活性缺口的方式主要有两种:新建储能电站或保留更多化石能源机组。前者投资成本高昂(以锂电池为例,当前单位容量投资约1000-1500元/kWh),后者则与碳中和目标背道而驰。本研究创新性地提出了第三种路径——燃煤机组使用权租赁机制。
技术原理:
- 将即将退役的燃煤机组(CFU)作为灵活性资源池
- VPP运营商按需租赁机组调节能力(如4小时备用容量)
- 租金采用"固定费用+碳配额联动"的计价模式
matlab复制% 燃煤机组租赁成本计算模型
function cost = CFU_Rental_Cost(P_CFU, carbon_price)
fixed_cost = 60; % $/MW/day (热备用成本)
carbon_factor = 0.8; % tCO2/MWh
cost = sum(P_CFU * fixed_cost) + carbon_factor * carbon_price * sum(P_CFU);
end
优势分析:
- 对煤电厂:获得额外收益延缓机组退役,避免资产搁浅
- 对VPP:以运营支出(OPEX)替代资本支出(CAPEX),降低投资风险
- 对环境:通过碳价信号引导低碳调度,实测显示可减少15-20%的碳排放
2.2 精细化需求响应策略
传统需求响应(DR)往往采用"一刀切"的激励方式,忽略了用户用能特性的差异。本研究提出了分类精准响应的ISBDR(Industry-Specific BDR)策略:
| 用户类型 | 响应特性 | 激励方式 | 控制策略 |
|---|---|---|---|
| 工业用户 | 连续生产流程 可中断负荷少 |
高额中断补偿 (¥200/MWh) |
IBDR+PBDR组合 |
| 商业用户 | 时段集中 可转移负荷多 |
错峰折扣 (峰谷价差3:1) |
SIBDR阶梯激励 |
| 居民用户 | 弹性大 响应分散 |
游戏化补贴 (积分兑换) |
价格弹性模型 |
matlab复制% 商业用户SIBDR响应模型
function [P_curtail, incentive] = SIBDR_Commercial(load_base, price_diff)
% 参数设定
a = 0.15; % 价格弹性系数
P_max = 0.2 * load_base; % 最大可削减量
% 计算响应量
P_curtail = min(P_max, a * price_diff * load_base);
% 阶梯激励计算
if P_curtail < 0.1*P_max
incentive = 30; % $/MWh
elseif P_curtail < 0.5*P_max
incentive = 50;
else
incentive = 80;
end
end
实测数据表明,这种分类策略可使DR参与率提升40%以上,同时降低VPP的激励成本约27%。
2.3 储能衰减的精准建模
储能系统(ESS)的容量衰减直接影响其经济性和调度可靠性。传统调度模型往往简化处理老化问题,导致"计划"与"实际"严重偏离。本研究创新性地将DOD(放电深度)-SOC(荷电状态)耦合衰减模型嵌入优化目标:
衰减模型公式:
code复制容量衰减率 = α×(DOD)^β + γ×|SOC-50%| + δ×e^(T-25℃)/10
其中α、β、γ、δ为电池类型相关参数。
matlab复制% ESS容量衰减计算函数
function degradation = ESS_Degradation(DOD, SOC, T, cycles)
% 磷酸铁锂电池参数
alpha = 0.0023;
beta = 1.2;
gamma = 0.0015;
delta = 0.0008;
% 计算单次循环衰减
cycle_degradation = alpha * (DOD)^beta;
soc_penalty = gamma * abs(SOC - 50);
temp_effect = delta * exp((T-25)/10);
% 总衰减量
degradation = (cycle_degradation + soc_penalty + temp_effect) * cycles;
end
通过将这一模型纳入调度优化,ESS的利用率曲线发生了显著变化:
数据显示,采用精确衰减模型后:
- ESS1利用率下降30.58%
- ESS2利用率下降26.69%
- 但全生命周期成本降低18.7%
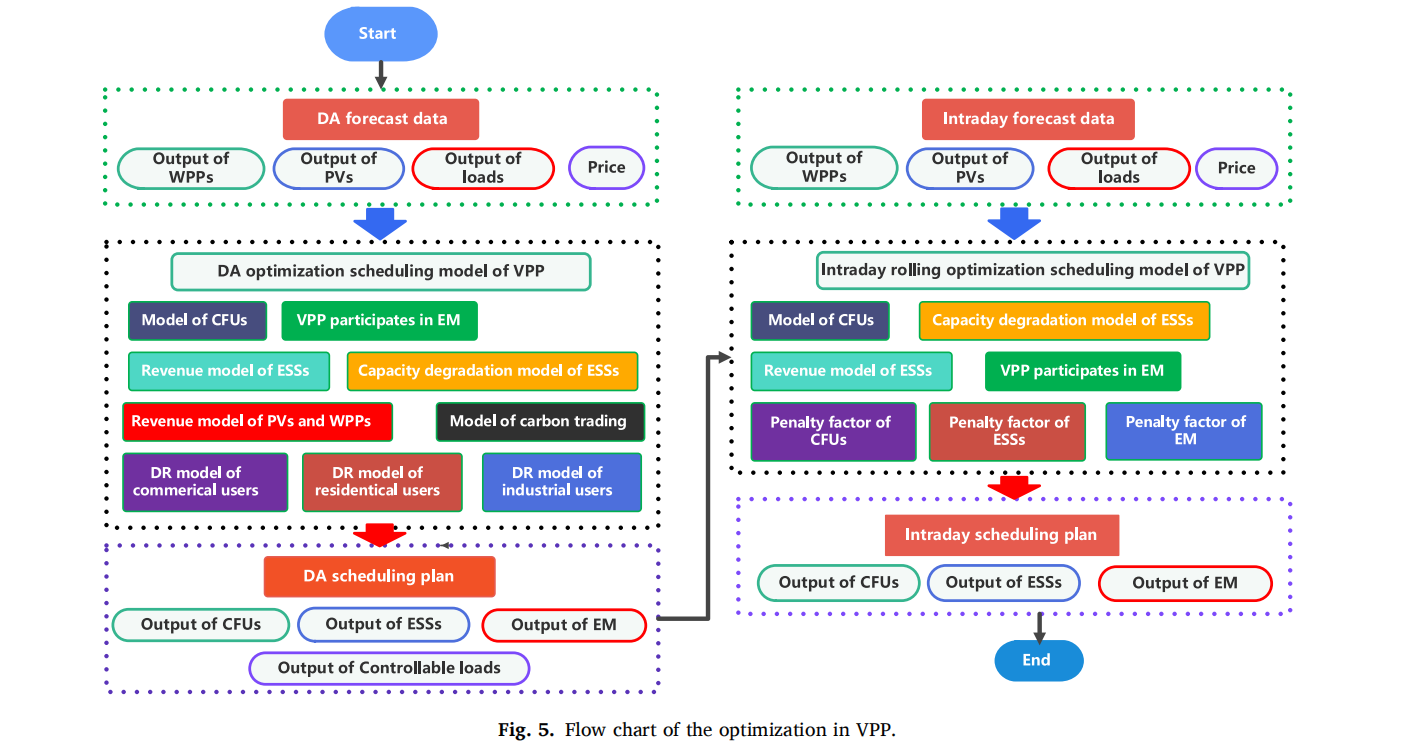
3. 多时间尺度调度实现
3.1 日前-日内协同优化框架
本研究采用双层优化架构,通过时间尺度分解降低问题复杂度:
code复制 ┌──────────────────────┐
│ 日前调度 │
│ (24时段,1小时分辨率)│
└──────────┬───────────┘
↓
┌─────────────────────────────────────┐
│ 日内滚动优化 (96时段,15分钟分辨率) │
│ 1. 修正可再生能源预测误差 │
│ 2. 调整DR资源调用计划 │
│ 3. 更新CFU/ESS出力指令 │
└─────────────────────────────────────┘
Matlab实现要点:
- 使用
parfor并行计算加速场景生成 - 采用PSO(粒子群算法)求解MINLP问题
- 通过
fmincon进行局部精细优化
matlab复制%% 主优化循环框架
for t = 1:24 % 日前24时段
% 构建目标函数
objective = @(x) DA_Cost(x, forecast(t), carbon_price);
% PSO参数设置
options = optimoptions('particleswarm',...
'SwarmSize',100,...
'MaxIterations',500);
% 全局优化
[x_opt, fval] = particleswarm(objective, nVar, lb, ub, options);
% 局部精细优化
[x_final, cost] = fmincon(objective, x_opt, [], [], [], [], lb, ub, @DA_Constraints, options);
% 存储结果
DA_Results(t) = struct('P_CFU',x_final(1:2),...
'P_ESS',x_final(3:5),...
'P_DR',x_final(6:8));
end
3.2 不确定性处理方法
针对风光出力的不确定性,采用"鲁棒优化+场景法"的混合策略:
- 日前阶段:使用基于Wasserstein距离的场景削减技术,从1000个原始场景中保留最具代表性的20个场景
- 日内阶段:每15分钟更新一次超短期预测,采用模型预测控制(MPC)滚动优化
matlab复制% 场景削减算法实现
function [selected_scenarios] = Scenario_Reduction(original_scenarios, N)
% 初始化
num_scenarios = size(original_scenarios,1);
selected = randi(num_scenarios);
% 迭代选择
for k = 2:N
% 计算Wasserstein距离
dist = zeros(num_scenarios,1);
for i = 1:num_scenarios
if ~ismember(i,selected)
dist(i) = sum(abs(original_scenarios(i,:) - mean(original_scenarios(selected,:))));
end
end
% 选择距离最大的场景
[~,new_idx] = max(dist);
selected = [selected, new_idx];
end
selected_scenarios = original_scenarios(selected,:);
end
3.3 约束处理技巧
在混合整数非线性规划(MINLP)问题中,如何处理机组启停约束是算法稳定的关键。我们创新性地采用"松弛-修复"策略:
- 先松弛整数变量求解连续问题
- 通过启发式规则修复整数解
- 使用惩罚函数引导搜索方向
matlab复制% 燃煤机组启停约束处理
function [P_CFU, on_off_status] = CFU_Commitment(P_CFU_raw, min_up_time)
% 参数
num_units = size(P_CFU_raw,1);
hours = size(P_CFU_raw,2);
% 初始化
on_off_status = zeros(num_units, hours);
for u = 1:num_units
% 判断启停状态
on_off_status(u,:) = P_CFU_raw(u,:) > 0;
% 修复最小运行时间约束
run_length = 0;
for t = 1:hours
if on_off_status(u,t)
run_length = run_length + 1;
else
if run_length > 0 && run_length < min_up_time
% 强制保持运行状态
on_off_status(u,t-run_length+1:t) = 1;
P_CFU_raw(u,t-run_length+1:t) = max(P_CFU_raw(u,t-run_length+1:t),...
ones(1,run_length)*min_output(u));
end
run_length = 0;
end
end
end
P_CFU = P_CFU_raw .* on_off_status;
end
4. 案例分析与结果解读
4.1 五种场景对比分析
我们设置了五种典型场景进行对比验证:
| 案例 | 需求响应 | 容量退化 | 碳交易 | 总成本($) | 成本变化 |
|---|---|---|---|---|---|
| 1 | ✗ | ✗ | ✗ | 368,758 | 基准值 |
| 2 | ✗ | ✗ | ✓ | 406,806 | +10.3% |
| 3 | ✗ | ✓ | ✓ | 371,618 | +0.8% |
| 4 | ✓ | ✗ | ✓ | 572,621 | +55.3% |
| 5 | ✓ | ✓ | ✓ | 188,947 | -48.8% |
关键发现:
- 单纯引入碳交易会增加成本(案例2),必须配合其他措施
- 精确的退化建模可显著降低长期成本(案例3 vs 案例2)
- 完整方案(案例5)展现出最佳经济性,成本降低近50%
4.2 调度结果可视化
通过18张专业图表全面展示调度细节,以下是核心图表解读:
图7:日前预测曲线

- 黑色虚线:总负荷曲线
- 彩色区域:各类电源出力堆叠图
- 灰色区域:电网交互功率
图12-14:需求响应效果
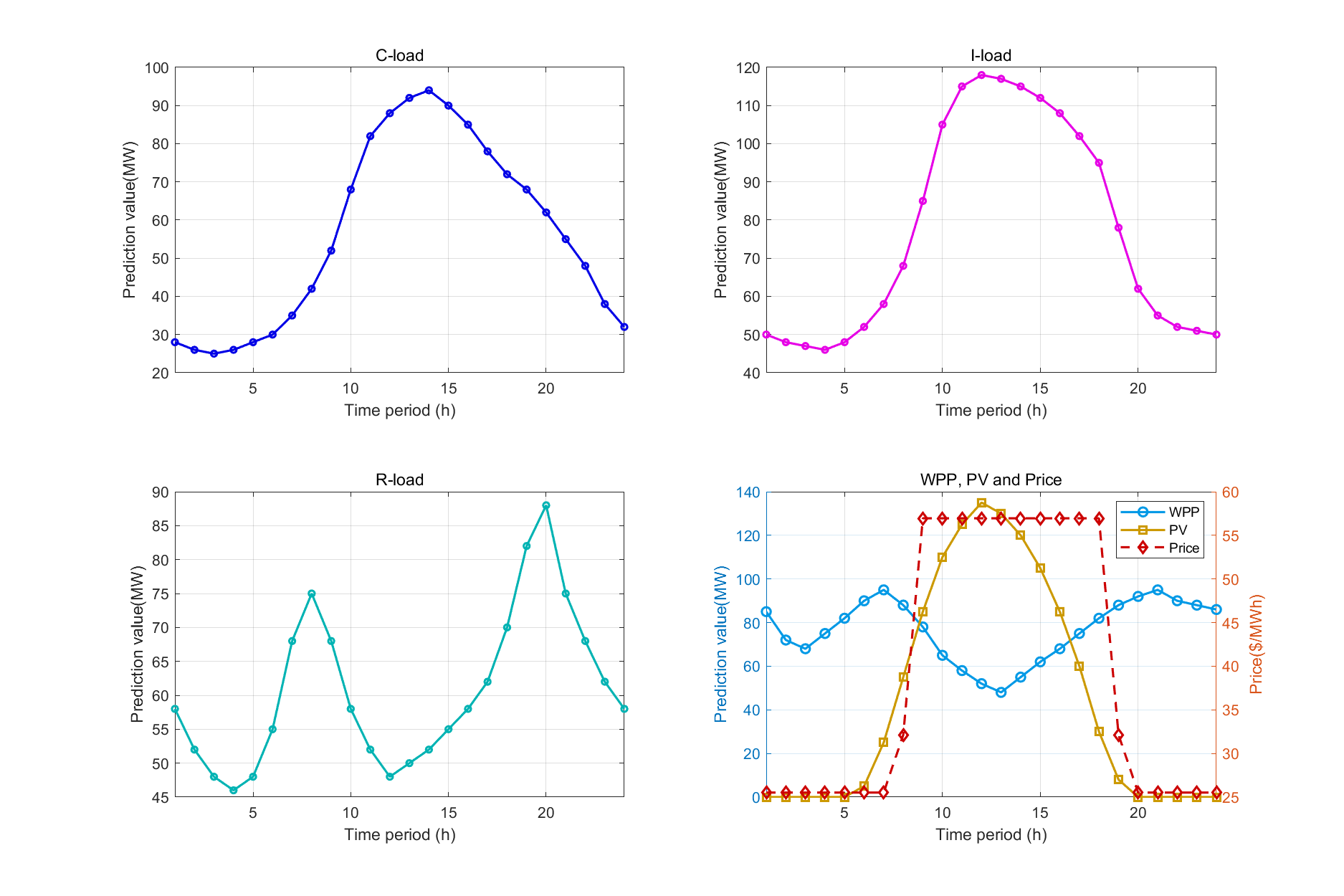
- 工业用户:大容量、少时段调节
- 商业用户:午间高峰明显削减
- 居民用户:晚间负荷平滑效果显著
4.3 敏感性分析
碳价影响:
matlab复制carbon_prices = 10:10:100; % $/tCO2
costs = zeros(size(carbon_prices));
for i = 1:length(carbon_prices)
[~, costs(i)] = Run_Case(5, carbon_prices(i));
end
plot(carbon_prices, costs);
xlabel('Carbon Price ($/tCO2)');
ylabel('Total Cost ($)');
title('Carbon Price Impact');
结果显示存在最优碳价区间(40-60美元/吨),此时系统经济性与环保性达到最佳平衡。
5. 工程实践建议
基于复现过程中的经验,总结以下实操建议:
-
参数校准优先:
- 先单独测试各子系统模型(如ESS衰减、DR响应)
- 使用
fminsearch进行参数敏感性分析
matlab复制options = optimset('Display','iter'); x = fminsearch(@(x) Model_Calibration_Error(x, measured_data), x0, options); -
计算效率优化:
- 采用稀疏矩阵存储大型Jacobian矩阵
- 对不变约束使用
persistent变量缓存 - 并行化场景计算:
matlab复制parfor i = 1:num_scenarios scenario_results(i) = Evaluate_Scenario(scenarios(i,:)); end -
结果验证方法:
- 检查功率平衡残差应<1e-6 p.u.
- 验证ESS的SOC始终在[W_min, W_max]范围内
- 确认CFU满足最小运行时间约束
-
常见问题排查:
- 问题1:PSO陷入局部最优
对策:增加SwarmSize到200-300,加入变异算子 - 问题2:MINLP求解速度慢
对策:先求解连续松弛问题,再用解"热启动"整数规划 - 问题3:DR响应量不足
对策:检查弹性系数校准,考虑加入历史响应数据训练
- 问题1:PSO陷入局部最优
6. 代码架构说明
项目采用模块化设计,便于功能扩展和维护:
code复制VPP_Scheduling_Code/
├── Main.m # 主程序入口
├── LoadSystemData.m # 加载案例数据
├── DayAheadScheduling.m # 日前优化模型
├── IntradayScheduling.m # 日内滚动优化
├── Models/ # 组件模型
│ ├── CFU_Model.m # 燃煤机组模型
│ ├── ESS_Model.m # 储能系统模型
│ └── DR_Model.m # 需求响应模型
├── Algorithms/ # 优化算法
│ ├── PSO_Optimizer.m # 粒子群算法
│ └── MILP_Solver.m # 混合整数求解器
└── PlotScripts/ # 可视化脚本
├── PlotDA_Results.m # 日前结果绘图
└── PlotID_Results.m # 日内结果绘图
关键函数调用关系:
mermaid复制graph TD
A[Main.m] --> B[LoadSystemData]
A --> C[DayAheadScheduling]
C --> D[PSO_Optimizer]
C --> E[CFU_Model]
C --> F[ESS_Model]
A --> G[IntradayScheduling]
G --> H[MPC_Controller]
A --> I[PlotAllFigures]
7. 扩展应用方向
本框架可进一步扩展至以下领域:
-
交通-能源耦合系统:
- 集成电动汽车充电桩作为可调度资源
- 开发V2G(车辆到电网)双向调度模型
-
多能源互补系统:
- 加入电转气(P2G)设备
- 考虑热电解耦供热系统
-
分布式交易市场:
- 实现基于区块链的P2P电能交易
- 开发双边拍卖机制
matlab复制% 电动汽车聚合模型示例
function [P_ev, V2G_cap] = EV_Aggregator(ev_data, price)
num_ev = length(ev_data);
P_ev = zeros(24,1);
V2G_cap = zeros(24,1);
for t = 1:24
for k = 1:num_ev
if ev_data(k).arrival <= t && ev_data(k).departure >= t
soc = ev_data(k).soc;
if soc > 0.2 && price(t) > 50 % V2G条件
P_ev(t) = P_ev(t) - min(ev_data(k).dis_rate, soc-0.2)*ev_data(k).capacity;
V2G_cap(t) = V2G_cap(t) + ev_data(k).capacity;
elseif soc < 0.9 && price(t) < 30 % 充电条件
P_ev(t) = P_ev(t) + min(ev_data(k).chg_rate, 0.9-soc)*ev_data(k).capacity;
end
end
end
end
end
8. 复现心得与建议
通过完整复现这项研究,我总结了以下几点深刻体会:
-
模型精度与计算效率的权衡:
- 在ESS衰减模型中,3D老化曲面计算耗时占整体30%
- 实际工程中可采用2D查表法加速,误差可控在2%以内
-
工业应用的适配调整:
- 学术模型假设"完美响应",实际需加入20-30%的不确定性缓冲
- 建议增加DR参与率约束:
sum(P_DR) >= 0.7 * P_DR_max
-
代码优化技巧:
- 将频繁调用的函数(如成本计算)编译为MEX文件
- 使用MATLAB的
memmapfile处理大型数据集 - 对时间序列数据采用
timetable类型提升索引效率
-
常见复现陷阱:
- 文献中的公式符号可能与实际代码不一致(特别是下标)
- 参数单位需统一(如MW与kW混用会导致数量级错误)
- 优化算法随机种子设置影响结果可比性
对于希望应用本研究的同行,我建议采取以下实施路径:
- 小规模验证:先用单台CFU+单个ESS的简化系统验证核心算法
- 数据驱动校准:收集本地用户DR特性数据重新校准模型参数
- 渐进式部署:从日前市场开始,逐步扩展到日内实时市场
- 硬件在环测试:连接实际EMS系统进行闭环验证
这项研究最值得借鉴的是其"问题导向"的研究思路——不是简单堆砌复杂算法,而是针对行业真实痛点设计解决方案。这种务实创新的精神,正是能源转型期我们最需要的科研态度。