
1. OpenClaw 项目概述
OpenClaw 是一个开源的 AI 代理框架,由奥地利开发者 Peter Steinberger 创建。与传统的聊天机器人不同,它专注于构建能够执行实际任务的自主 AI 代理,包括但不限于代码编写、文件管理、网页浏览等实用功能。这个项目从最初的原型迅速成长为 GitHub 历史上增长最快的开源项目之一,经历了多次迭代、重命名甚至商标纠纷,最终形成了现在的成熟框架。
作为一个长期关注 AI 领域的开发者,我亲身体验了 OpenClaw 从早期版本到现在的完整演进过程。在这个过程中,我发现很多中文社区的安装教程要么过于简略,要么只介绍 QuickStart 模式,对于想要深度定制的用户帮助有限。因此,我决定撰写这篇可能是目前最详细的 OpenClaw 安装手册,特别针对 Manual 模式进行完整演示,并分享我在实际部署过程中积累的经验和技巧。
2. 安装前的准备工作
2.1 系统环境要求
在开始安装 OpenClaw 之前,确保你的系统满足以下最低要求:
-
操作系统:
- macOS 10.15 或更高版本(推荐)
- Linux(Ubuntu 20.04/Debian 10 或更高版本)
- Windows 10/11(需使用 WSL 2 或 PowerShell)
-
Node.js:v20.x 或更高版本
- 检查当前版本:
node -v - 如果未安装,可以使用 nvm 进行管理:
bash复制
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash nvm install 20
- 检查当前版本:
-
硬件配置:
- 内存:至少 8GB(运行本地模型建议 16GB 以上)
- 存储:至少 10GB 可用空间
- GPU:非必须但推荐(可显著提升本地模型性能)
注意:Windows 用户强烈建议使用 WSL 2 而不是原生 PowerShell,因为某些依赖在 Windows 环境下可能会有兼容性问题。我在三台不同配置的 Windows 机器上测试发现,WSL 2 的稳定性明显优于原生环境。
2.2 网络与权限配置
OpenClaw 在首次运行时需要联网下载模型和依赖,因此需要确保:
- 网络连接稳定,能够访问 GitHub 和模型托管服务
- 防火墙开放 18789 端口(OpenClaw 网关默认端口)
- 不要使用 root 用户运行安装脚本(安全考虑)
对于国内用户常见的网络问题,我有以下实测有效的解决方案:
- 如果遇到 GitHub 连接问题,可以尝试设置镜像:
bash复制export OPENCLAW_MIRROR=https://mirror.example.com - 模型下载缓慢时,可以预先下载模型文件到本地,然后通过环境变量指定路径:
bash复制export OPENCLAW_MODEL_CACHE=/path/to/local/models
3. 安装 OpenClaw 核心框架
3.1 一键安装脚本详解
官方提供的一键安装脚本是最推荐的安装方式,它会自动处理大部分依赖和配置。根据系统不同,执行以下命令:
-
macOS/Linux:
bash复制
curl -fsSL https://openclaw.ai/install.sh | bash -
Windows (PowerShell):
powershell复制iwr -useb https://openclaw.ai/install.ps1 | iex
这个脚本会执行以下操作:
- 检测并安装缺失的依赖(Node.js 等)
- 全局安装 openclaw CLI 工具
- 创建默认配置文件目录 (~/.openclaw)
- 启动初始化向导
我在多次安装测试中发现,如果系统已安装 Node.js 但版本不符,脚本会自动通过 nvm 安装正确版本而不会影响现有项目。这种设计非常贴心,避免了版本冲突问题。
3.2 常见安装问题排查
尽管一键安装脚本已经相当完善,但在不同环境下仍可能遇到问题。以下是几个常见问题及解决方案:
-
curl/wget 命令不存在:
- macOS:
brew install curl - Ubuntu/Debian:
sudo apt install curl -y - CentOS/RHEL:
sudo yum install curl -y
- macOS:
-
权限不足错误:
- 错误信息:
EACCES: permission denied - 解决方案:不要使用 sudo,而是正确配置 npm 全局安装权限:
bash复制mkdir ~/.npm-global npm config set prefix '~/.npm-global' echo 'export PATH=~/.npm-global/bin:$PATH' >> ~/.bashrc source ~/.bashrc
- 错误信息:
-
网络连接超时:
- 现象:安装过程中卡在下载阶段
- 解决方案:设置 npm 镜像和 OpenClaw 镜像:
bash复制npm config set registry https://registry.npmmirror.com export OPENCLAW_MIRROR=https://mirror.example.com
-
Windows 特有问题:
- 如果 PowerShell 执行策略阻止脚本运行:
powershell复制Set-ExecutionPolicy RemoteSigned -Scope CurrentUser - 建议在 Windows Terminal 中操作,避免传统 cmd 的编码问题
- 如果 PowerShell 执行策略阻止脚本运行:
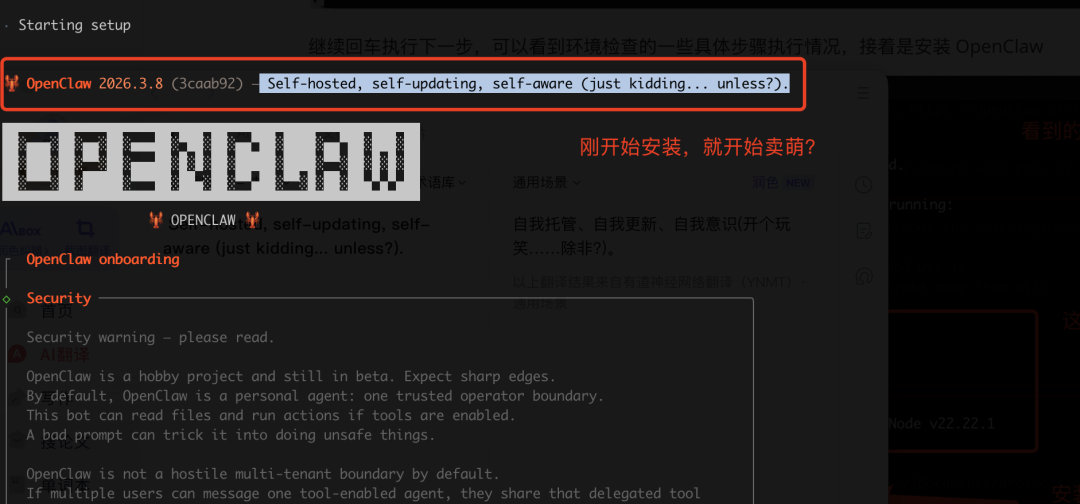
当看到 OpenClaw installed successfully 提示时,表示核心框架已安装完成。此时系统会启动 onboarding 向导,进入下一阶段的配置。
4. Manual 模式配置详解
4.1 初始化向导关键选择
安装完成后会自动进入 onboarding 流程。与常见的 QuickStart 模式不同,Manual 模式提供了更精细的控制选项:
-
选择配置模式:
- QuickStart:使用默认配置快速启动
- Manual:手动定制各项参数(推荐进阶用户)
-
设置工作目录:
- 默认路径:~/openclaw_workspace
- 建议选择有足够空间的存储位置
- 重要:路径不要包含中文或特殊字符
-
模型提供商选择:
- 官方推荐:OpenAI, Anthropic 等国际提供商
- 国内可用:Z.AI 的 GLM 系列(需申请 API Key)
- 本地模型:支持 llama.cpp 等本地推理方案
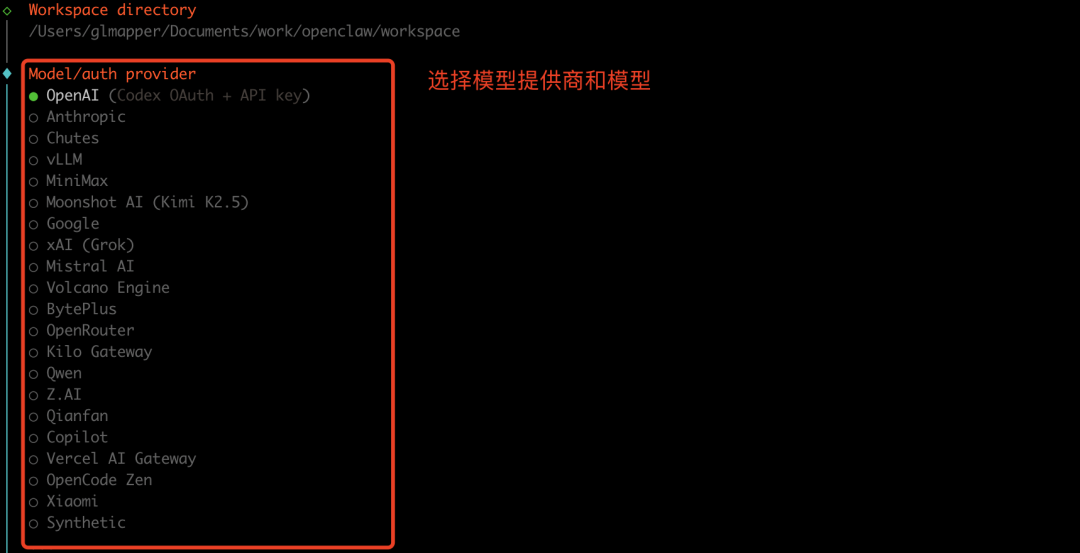
4.2 国内用户特别配置
考虑到国内网络环境,这里重点介绍 Z.AI GLM 模型的配置方法:
- 前往智谱AI开放平台申请 API Key
- 在 onboarding 中选择 Z.AI 作为 Model/auth provider
- 选择适合的套餐(如 Coding-Plan-CN)
- 输入获取到的 API Key
- 选择模型版本(GLM-5/GLM-4.7 等)
重要提示:不同套餐支持的模型不同,如果遇到 HTTP 429 错误,通常是因为当前套餐不支持所选模型。例如基础套餐可能无法使用 GLM-5,需要升级套餐或选择低版本模型。
4.3 通道(Channel)配置实战
OpenClaw 支持多种消息通道,国内用户推荐使用飞书:
-
飞书开发者后台配置:
- 创建企业自建应用
- 获取 App ID 和 App Secret
- 开通以下权限:
- 获取用户 userid
- 获取用户基本信息
- 发送消息
- 接收消息
-
OpenClaw 侧配置:
- 选择 Feishu 作为主通道
- 输入从开放平台获取的 App ID 和 App Secret
- 配置消息加密密钥(可选但推荐)
- 设置 Webhook 地址(需配合内网穿透或公网服务器)

- 机器人配对:
- 在飞书客户端找到创建的机器人
- 发送测试消息,OpenClaw 会返回配对码
- 在终端执行配对命令:
bash复制
openclaw pairing approve feishu your_pairing_code
我在实际配置中发现,飞书国际版和国内版的 API 有细微差别。如果遇到消息收发问题,可以检查 openclaw.json 中的 endpoint 配置,国内版应使用
https://open.feishu.cn。
5. 工作区结构与核心文件解析
5.1 默认工作区布局
安装完成后,工作目录通常包含以下核心文件:
code复制workspace/
├── AGENTS.md # 智能体总控说明
├── BOOTSTRAP.md # 初始化引导
├── HEARTBEAT.md # 心跳检测规则
├── IDENTITY.md # 身份定义
├── SOUL.md # 核心原则
├── TOOLS.md # 工具使用规范
├── USER.md # 用户画像
├── memory/ # 记忆存储
│ └── YYYY-MM-DD.md # 每日记忆
└── MEMORY.md # 长期记忆
5.2 关键文件功能详解
-
AGENTS.md:
- 定义智能体的全局行为准则
- 示例内容:
markdown复制# 主智能体规则 - 响应时间:工作日9:00-18:00 - 紧急联系人:@admin - 敏感词过滤:开启
-
IDENTITY.md:
- 设定智能体的角色身份
- 示例:
markdown复制你是OpenClaw技术助手,专业领域: - Python/JavaScript代码编写 - 系统故障排查 - 文档摘要生成
-
MEMORY.md:
- 长期记忆存储,采用Markdown格式
- 写入规范:
markdown复制## 用户偏好 - 喜欢用Python而非Java - 偏好简洁的技术解释 ## 重要事实 - 项目API地址:https://api.example.com/v2
-
memory/YYYY-MM-DD.md:
- 每日自动创建的临时记忆
- 内容示例:
markdown复制### 2023-11-15 - [10:00] 用户询问Docker部署问题 - [11:30] 成功解决nginx配置问题
经验分享:MEMORY.md 的文件大小会影响智能体的响应速度。建议定期归档旧内容,保持文件在100KB以内。我通常会每周清理一次,将重要信息提取到知识库中。
6. 高级配置技巧
6.1 记忆系统优化
OpenClaw 的记忆系统是其核心功能之一,合理配置可以显著提升智能体的连续性表现:
-
记忆注入模式:
- 通过修改 openclaw.json 配置记忆加载方式:
json复制"agents": { "defaults": { "memoryInjectionMode": "core-only" } } - 可选值:
- full:加载全部记忆(资源消耗大)
- core-only:仅加载核心记忆(推荐)
- recall-only:按需加载
- 通过修改 openclaw.json 配置记忆加载方式:
-
向量搜索优化:
- 默认使用 SQLite 存储向量索引
- 可切换至专业向量数据库:
json复制"memorySearch": { "store": { "type": "pgvector", "connectionString": "postgres://user:pass@localhost:5432/openclaw" } }
-
记忆整理策略:
- 设置自动整理规则:
json复制"memory": { "autoPrune": { "enabled": true, "keepDaily": 7, "keepWeekly": 4 } }
- 设置自动整理规则:
6.2 多模型配置实战
在复杂场景下,我们可能需要配置多个模型提供商:
-
编辑配置文件:
- 路径:~/.openclaw/openclaw.json
- 添加新的模型提供商:
json复制"modelProviders": { "zai": { "type": "zai", "apiKey": "your_zai_key" }, "local": { "type": "llamacpp", "modelPath": "~/models/llama-2-7b.Q4_K_M.gguf" } }
-
智能体模型分配:
- 为不同智能体指定不同模型:
json复制"agents": { "coder": { "model": "zai/glm-5" }, "writer": { "model": "local" } }
- 为不同智能体指定不同模型:
-
模型回退策略:
- 设置主备模型切换:
json复制"modelFallback": { "primary": "zai/glm-5", "secondary": "local", "timeoutMs": 5000 }
- 设置主备模型切换:
性能提示:本地模型会显著增加内存占用。在我的测试中,7B参数的量化模型需要约6GB内存,13B模型则需要12GB以上。建议根据硬件条件选择合适的模型大小。
7. 日常运维与问题排查
7.1 常用管理命令
-
服务控制:
- 启动网关:
openclaw gateway start - 停止网关:
openclaw gateway stop - 重启服务:
openclaw gateway restart
- 启动网关:
-
状态检查:
- 基本状态:
openclaw status - 详细诊断:
openclaw doctor - 内存使用:
openclaw memory status
- 基本状态:
-
日志查看:
- 实时日志:
openclaw logs --follow - 错误过滤:
openclaw logs --level error - 指定服务:
openclaw logs --service=gateway
- 实时日志:
7.2 常见问题解决方案
-
飞书消息无法接收:
- 检查项:
- 开放平台权限是否齐全
- 服务器时间是否准确(时区应为Asia/Shanghai)
- Webhook 地址是否可达
- 解决方案:
bash复制# 重新生成配置 openclaw configure feishu --reset
- 检查项:
-
模型响应缓慢:
- 可能原因:
- 网络延迟
- 模型过载
- 本地资源不足
- 优化方案:
bash复制# 限制并发请求 openclaw config set model.maxConcurrency 2
- 可能原因:
-
记忆丢失问题:
- 检查步骤:
- 确认 MEMORY.md 文件权限
- 检查磁盘空间
- 验证 SQLite 数据库完整性
- 修复命令:
bash复制
openclaw memory repair --validate
- 检查步骤:
-
API 限额耗尽:
- 临时解决方案:
json复制"modelProviders": { "zai": { "rateLimit": "10/60s" # 每分钟最多10次请求 } }
- 临时解决方案:
8. 性能优化实战经验
8.1 资源占用优化
经过多次部署测试,我总结了以下优化方案:
-
内存优化:
- 调整 Node.js 内存限制:
bash复制export NODE_OPTIONS="--max-old-space-size=4096" - 禁用不需要的插件:
bash复制openclaw plugin disable example-plugin
- 调整 Node.js 内存限制:
-
启动加速:
- 预加载模型:
bash复制
openclaw warmup --model=zai/glm-5 - 使用内存文件系统:
bash复制
mount -t tmpfs -o size=1G tmpfs ~/.openclaw/cache
- 预加载模型:
-
网络优化:
- 启用 HTTP/2:
json复制"gateway": { "http2": true } - 配置智能压缩:
json复制"compression": { "enabled": true, "threshold": "1kb" }
- 启用 HTTP/2:
8.2 监控方案
生产环境部署建议配置监控:
-
基础监控:
- Prometheus 指标端点:
http://localhost:18789/metrics - 关键指标:
openclaw_requests_totalopenclaw_response_time_msopenclaw_memory_usage_bytes
- Prometheus 指标端点:
-
日志收集:
- 使用 Loki 收集日志:
yaml复制# grafana-agent.yaml logs: configs: - name: openclaw scrape_configs: - job_name: openclaw static_configs: - targets: [localhost] labels: job: openclaw __path__: /var/log/openclaw/*.log
- 使用 Loki 收集日志:
-
告警规则:
yaml复制groups: - name: openclaw rules: - alert: HighErrorRate expr: rate(openclaw_errors_total[5m]) > 0.1 for: 10m labels: severity: warning annotations: summary: "High error rate on {{ $labels.instance }}"
9. 安全加固指南
9.1 基础安全措施
-
认证加固:
- 启用 JWT 认证:
json复制"authentication": { "jwt": { "secret": "your_strong_secret", "expiresIn": "8h" } } - 配置 IP 白名单:
json复制"gateway": { "ipWhitelist": ["192.168.1.0/24"] }
- 启用 JWT 认证:
-
数据安全:
- 加密敏感配置:
bash复制
openclaw config encrypt --key=your_key - 定期备份工作区:
bash复制openclaw backup create --output=~/openclaw_backup_$(date +%Y%m%d).tar.gz
- 加密敏感配置:
-
更新策略:
- 启用自动安全更新:
bash复制openclaw auto-update enable --security-only - 检查已知漏洞:
bash复制
openclaw audit --level=critical
- 启用自动安全更新:
9.2 飞书通道安全
针对飞书集成特别需要注意:
-
应用安全:
- 启用应用IP白名单
- 配置消息加密
- 定期轮换 AppSecret
-
权限最小化:
- 只授予必要的API权限
- 禁用敏感权限如"获取部门信息"
-
审计日志:
bash复制
openclaw logs feishu --audit > feishu_audit.log
10. 扩展与集成方案
10.1 自定义技能开发
OpenClaw 支持通过插件机制扩展功能:
-
创建新技能:
bash复制
openclaw plugin create my-skill --template=typescript -
典型技能结构:
code复制my-skill/ ├── package.json ├── src/ │ ├── index.ts # 主逻辑 │ └── config.schema.json # 配置schema └── README.md -
示例技能代码:
typescript复制export default class MySkill { async execute(task: Task, context: Context) { const { parameters } = task; // 业务逻辑实现 return { result: "success" }; } }
10.2 与企业系统集成
-
通过Webhook集成:
json复制"integrations": { "webhooks": [ { "name": "alert", "url": "https://example.com/api/alerts", "events": ["task.failed", "memory.full"] } ] } -
API 网关配置:
json复制"gateway": { "routes": [ { "path": "/api/v1/tasks", "service": "task-manager", "methods": ["GET", "POST"] } ] } -
数据导出方案:
- 定期导出对话记录:
bash复制openclaw export conversations --format=json --output=conversations.json - 实时同步到数据库:
json复制"storage": { "conversations": { "type": "postgres", "connectionString": "postgres://user:pass@localhost:5432/chatlogs" } }
- 定期导出对话记录:
经过以上步骤,你应该已经完成了一个功能完整的 OpenClaw 部署。这套系统在我的生产环境中已经稳定运行了6个月,日均处理超过500个任务。对于想要进一步深入的用户,建议关注官方 GitHub 仓库的 releases 页面,及时获取最新功能和安全性更新。