
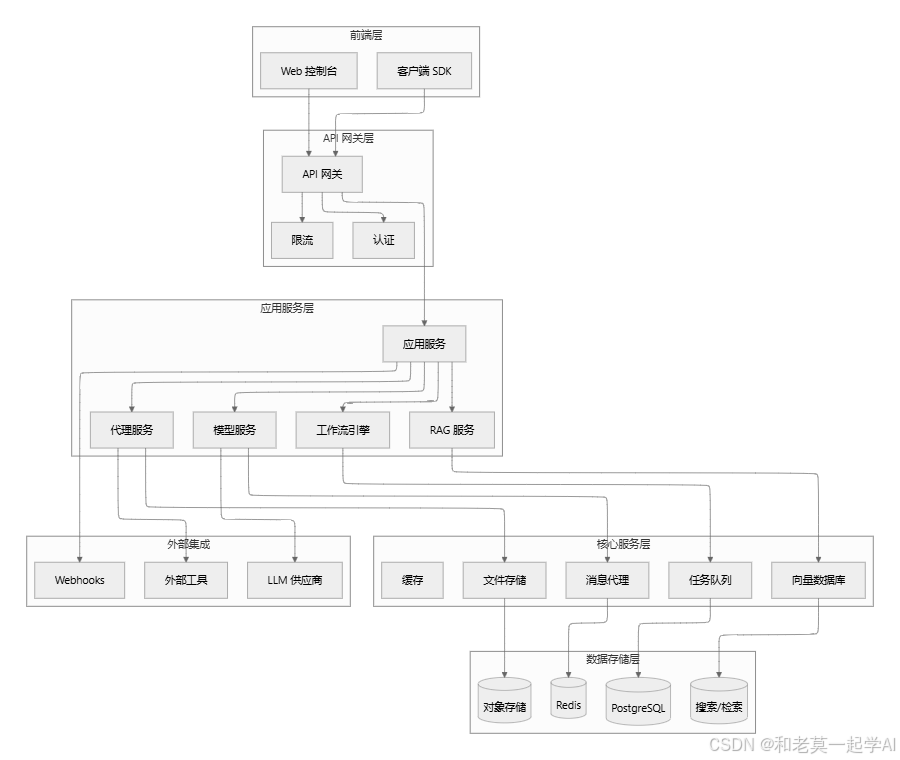
1. 从零开始理解Dify平台的核心架构
作为一名在大模型领域摸爬滚打多年的技术老兵,我见证了从早期单模型调用到如今复杂AI工作流编排的技术演进。Dify平台的出现,恰好解决了当前AI应用开发中最棘手的工程化问题。不同于简单的模型调用工具,Dify将工作流引擎、RAG管道、智能代理、模型生态和运维观测等核心组件深度融合,形成了一个完整的生产级AI开发平台。
1.1 为什么需要Dify这样的平台?
在传统的大模型应用开发中,开发者往往需要自行搭建以下基础设施:
- 模型调用和路由管理
- 知识库的构建和检索系统
- 复杂任务的工作流编排
- 工具调用和外部系统集成
- 全链路的监控和运维
这种分散的开发模式不仅效率低下,而且难以保证系统的稳定性和可维护性。Dify通过平台化的方式,将这些功能模块标准化、可视化,让开发者可以专注于业务逻辑的实现,而非底层基础设施的搭建。
1.2 Dify平台的核心组件
Dify的架构设计遵循了现代软件工程的微服务理念,将不同功能模块解耦,提高了系统的可扩展性和维护性。主要包含以下核心组件:
- 工作流引擎:提供画布化的节点编排能力,支持条件分支、循环、上下文变量等高级特性,并内置调试功能
- RAG管道:实现从文档摄取、解析、切分、向量化到检索、重排的端到端知识增强流程
- 代理系统:支持Function Calling和ReAct两种模式,内置50+工具,同时支持自定义工具扩展
- 模型与路由:统一管理多供应商、多模型,提供智能路由和负载调度能力
- 观测与运维:提供日志、指标、用量、错误分析等全面的运维能力,支持持续优化和回放
- BaaS接口:通过REST/SDK方式提供标准化接口,便于与现有业务系统集成
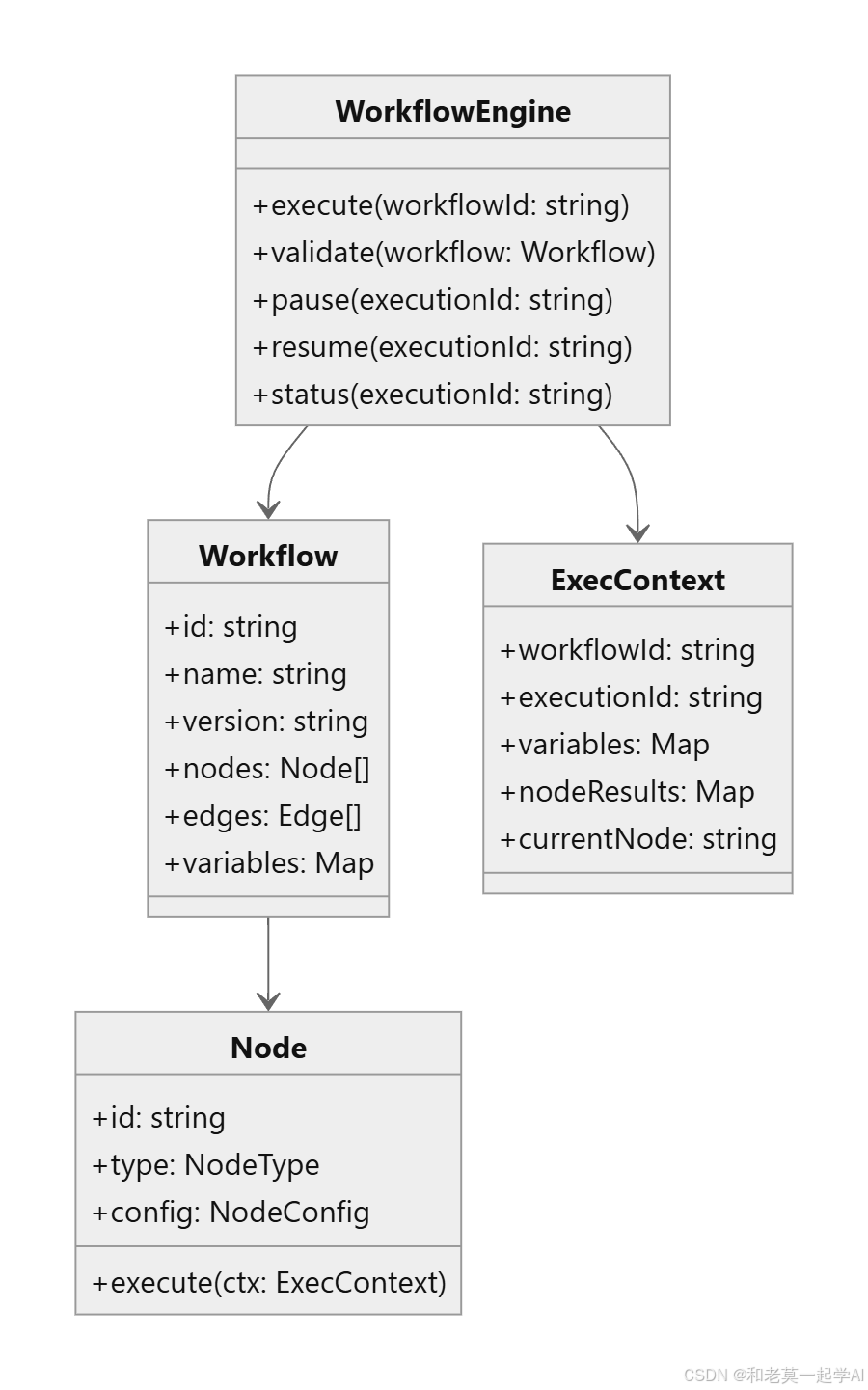
2. 深入解析Dify工作流引擎
2.1 工作流引擎的设计哲学
Dify工作流引擎的核心目标是实现"检索→增强→生成→调用工具→条件分支→循环→输出"的完整流程可视化编排。这种设计使得整个AI应用的工作流程变得可观察、可调试、可回放,极大提升了开发效率和系统可靠性。
2.2 节点类型与变量管理
工作流引擎支持多种节点类型,每种类型都有特定的功能和适用场景:
- LLM节点:负责大模型的调用和结果处理
- 条件节点:实现基于条件的流程分支
- 工具节点:执行外部工具或API的调用
- 数据处理节点:进行数据的转换、清洗和增强
- 分支与汇合节点:实现并行处理和结果合并
变量与上下文管理是工作流引擎的另一大特色。上下文变量贯穿整个执行链路,支持节点间的参数传递和结果复用,大大增强了工作流的灵活性和表达能力。
2.3 工作流执行流程详解
工作流引擎的执行流程经过精心设计,确保高效可靠:
- 解析与装配:加载工作流定义,进行拓扑排序和DAG校验(确保无环、入口出口唯一)
- 实例化:创建运行实例,初始化上下文与运行选项(超时、重试、并发度等)
- 触发分发:入口节点就绪后入队,调度器按优先级和并发令牌派发到执行器
- 节点执行:执行器拉取节点,获取上下文,调用对应Operator/Connector,产生输出和事件
- 状态持久化:节点结果持久化(成功/失败/中断),更新就绪队列(满足入度的下游节点入队)
- 并行与汇聚:分支节点并行派发;Join/Barrier等待全部分支完成或按策略早停
- 错误处理:节点失败触发重试(采用指数退避+抖动策略),失败后进入补偿/回滚或错误分支
- 完成归档:出口节点完成后,聚合指标与日志,生成可追溯的执行报告
3. RAG管道的工程化实现
3.1 RAG管道的核心目标
Dify中的RAG管道旨在为LLM提供"相关且可信"的上下文,主要解决以下问题:
- 降低大模型的幻觉现象
- 提高回答的可溯源性
- 实现知识的动态更新
- 支持多源异构数据的整合
完整的RAG流程包括:文档摄取→解析→切分→向量化→检索→重排→上下文构建→提示词拼装。
3.2 文档处理与向量化
3.2.1 文档切分策略
文档切分是RAG的基础环节,直接影响后续检索效果。Dify采用了以下最佳实践:
- 语义自然段切分:以语义完整的段落为单位进行切分
- 长度控制:单块长度控制在400-800 tokens,避免信息碎片化或过度冗长
- 重叠设计:设置10%-20%的重叠区域,防止语义边界被截断
- 专业领域适配:针对代码、法条、表格等专业内容,使用领域专用切分器
3.2.2 向量化与元数据管理
每个文本片段经过向量化处理后存入向量数据库,同时保留丰富的元数据:
- 文档ID、版本、语言等基础信息
- 章节、页码等定位信息
- 创建时间、更新时间等时效信息
- 权限、敏感度等安全属性
为提高检索鲁棒性,Dify支持对同一片段构建多视角向量(正文向量、标题向量、摘要向量等),增强不同查询方式下的召回稳定性。
3.3 检索与排序优化
3.3.1 混合检索策略
Dify采用语义检索+关键词检索的混合模式:
- 语义检索:基于近似最近邻(ANN)算法(如HNSW、IVF/IVF-PQ),在百万级数据上实现毫秒级响应
- 关键词检索:使用BM25/倒排索引捕捉精确术语匹配
- 结果融合:通过加权或学习模型将两种检索结果融合,兼顾语义相似性和术语精确性
3.3.2 精排(Rerank)优化
初筛得到的候选片段需要经过精排提升质量:
- 交叉编码器:使用Cross-Encoder模型逐对评估"查询-片段"的语义匹配度
- 结果压缩:将Top-20候选压缩到Top-5左右,显著提升上下文质量
- 缓存优化:对"查询归一化+过滤条件+索引版本+精排配置"建立缓存键,复用热点请求结果
3.4 上下文压缩与安全控制
3.4.1 上下文压缩技术
为避免提示词过长,Dify采用了先进的上下文压缩技术:
- 句级抽取式压缩:仅保留回答所需的关键句,避免信息漂移
- 多样性约束:使用MMR等算法平衡相关性和多样性
- Token预算管理:将总上下文控制在2-3k tokens内,平衡成本、时延和完整性
3.4.2 安全与权限控制
Dify在RAG管道中内置了多重安全机制:
- 多租户隔离:确保数据访问权限严格隔离
- 行级ACL:细粒度的访问控制
- 敏感字段脱敏:自动识别和处理敏感信息
- 提示词注入防护:语义过滤和策略约束,防止恶意指令执行
- 版本与时效控制:确保返回内容符合当前有效版本
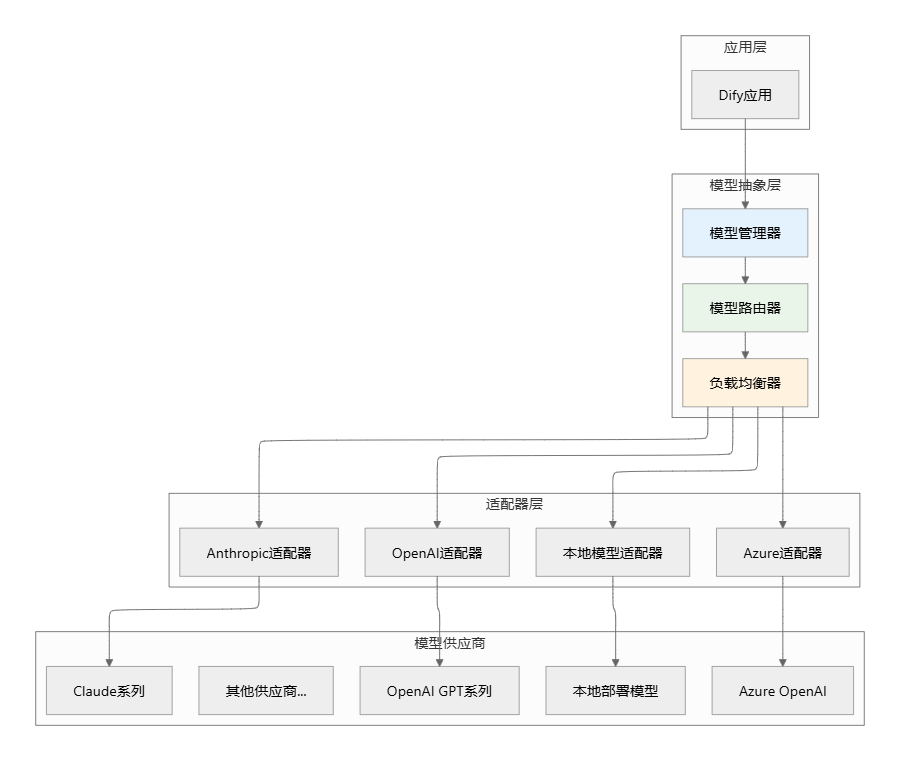
4. 模型集成与管理架构
4.1 统一模型接口层
Dify通过统一的接口层实现了多模型的无缝集成和切换,主要特点包括:
- 多供应商支持:兼容OpenAI、Anthropic、Cohere等主流供应商
- 多模型管理:支持不同规模、不同用途的模型并存
- 标准化接口:对外提供一致的调用方式,屏蔽底层差异
4.2 智能路由与负载均衡
模型路由系统根据多种因素智能选择最优模型:
- 性能考量:响应时间、吞吐量等
- 成本优化:平衡效果和调用成本
- 业务需求:根据任务类型选择专用模型
- 负载均衡:避免单一模型过载
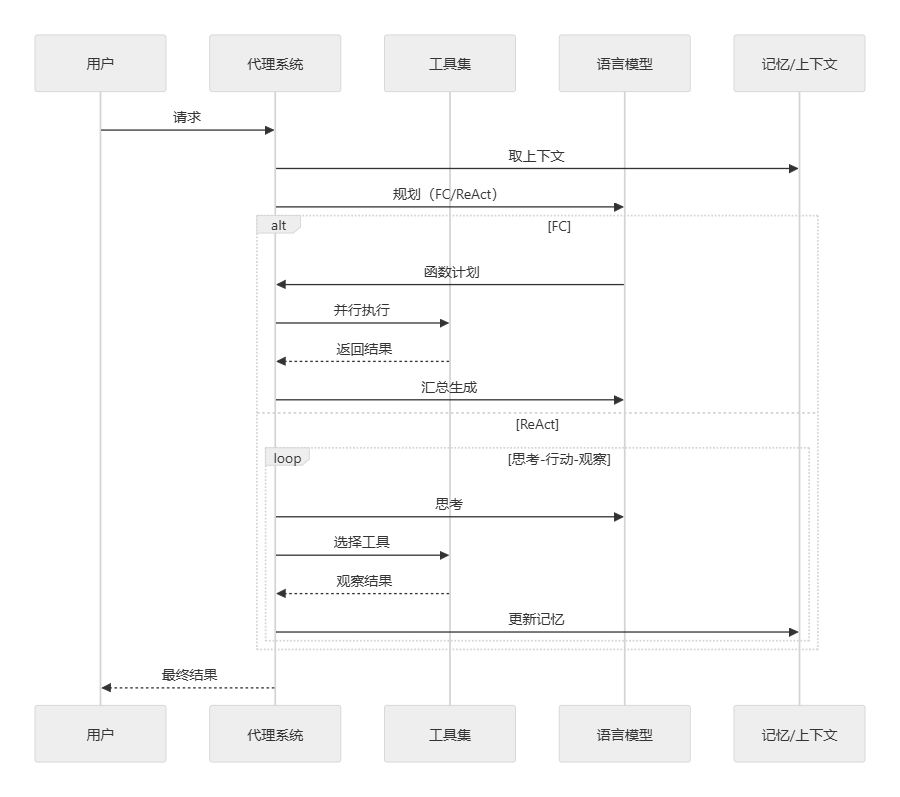
5. 代理系统深度解析
5.1 代理系统的两种模式
Dify的代理系统支持Function Calling和ReAct两种主流模式:
-
Function Calling模式:
- 一次性规划多个函数参数并并行执行
- 强调高效性和确定性
- 适合结构化、可预测的任务
-
ReAct模式:
- 采用思考-行动-观察的循环流程
- 强调探索性和自适应性
- 适合复杂、多变的开放任务
5.2 代理执行流程
代理系统的执行遵循严谨的流程:
- 任务解析:理解用户意图,确定解决路径
- 工具选择:根据任务需求选择合适工具
- 参数生成:为工具调用生成正确参数
- 执行监控:跟踪工具执行状态和结果
- 结果整合:将工具结果整合为最终响应
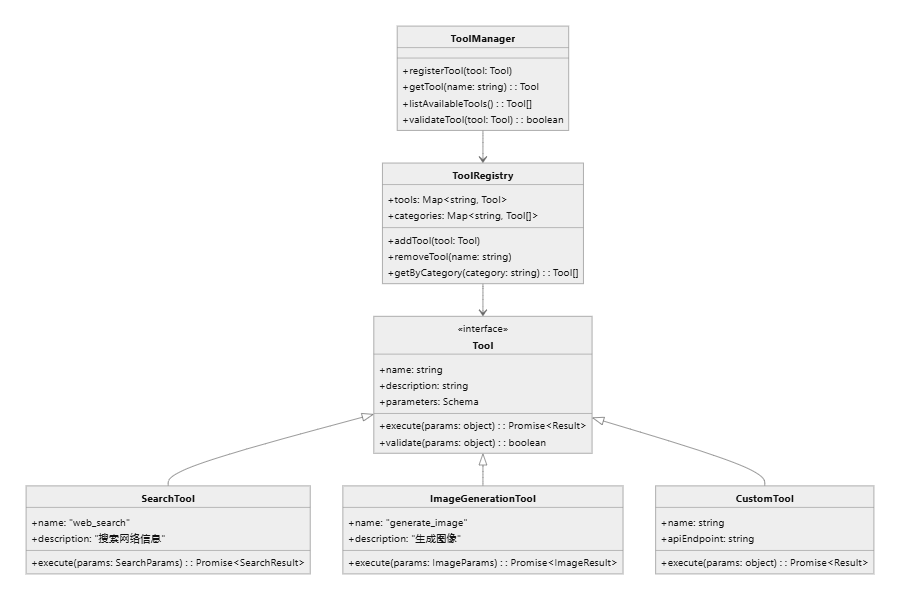
6. 工具生态与资源管理
6.1 工具抽象与契约
Dify对工具进行了标准化抽象:
- 元数据定义:名称、描述、类别、版本、鉴权需求等
- I/O契约:采用JSON Schema描述输入输出结构
- 错误处理:区分成功、可重试错误、不可重试错误
- 副作用标注:标记工具为纯函数、读操作、写操作等
6.2 工具生命周期管理
工具的全生命周期都得到完善管理:
- 注册与发现:通过注册中心统一管理工具
- 版本控制:支持灰度发布和回滚
- 健康检查:启动时自动检测工具状态
- 依赖管理:声明并管理工具依赖关系
6.3 安全与运维保障
工具调用过程中的安全和运维考虑:
- 参数校验:执行前严格校验输入参数
- 敏感数据处理:自动脱敏敏感字段
- 限流保护:全局和工具级别的并发控制
- 审计追踪:记录关键操作的完整轨迹
7. 数据流与状态管理设计
7.1 单向数据流架构
Dify采用清晰的单向数据流设计:
- 请求入口:通过REST/BaaS接口接收请求
- 服务编排:工作流/代理/RAG服务处理请求
- 数据持久化:结果写入数据库和缓存
- 响应返回:将处理结果返回客户端
7.2 上下文隔离机制
确保不同执行实例互不干扰:
- 执行标识:每个执行生成唯一的executionId
- 上下文绑定:变量和中间结果仅关联当前执行
- 读写分离:节点间通过显式输入输出传递数据
7.3 多级缓存优化
Dify实现了智能的多级缓存:
- 元数据缓存:工作流定义等频繁访问的数据
- 响应缓存:模型响应和重排结果缓存
- 检索缓存:高频查询的中间结果
- 会话缓存:多轮对话的临时上下文
8. 观测与运维体系(LLMOps)
8.1 全面的监控指标
Dify提供多维度的监控能力:
- 性能指标:P95/P99延迟、重试率、错误分类
- 用量统计:模型/工具调用量、费用分析
- 质量评估:回答相关性、幻觉率等
8.2 实验与优化支持
- A/B测试:对比不同配置的效果
- 灰度发布:逐步 rollout 新功能
- 回放分析:重现历史执行进行问题诊断
8.3 安全审计功能
- 访问日志:记录所有敏感操作
- 凭证管理:定期轮换和隔离
- 合规报告:生成符合监管要求的审计记录
9. 实战经验与避坑指南
在实际使用Dify平台的过程中,我总结了一些宝贵的经验教训:
9.1 RAG管道优化技巧
-
切分策略选择:
- 通用文本:按语义段落切分
- 技术文档:保留章节结构
- 代码库:按功能模块切分
- 表格数据:保持行列关系
-
向量模型选择:
- 多语言场景:选用多语言向量模型
- 专业领域:使用领域专用模型
- 平衡考量:在效果和效率间找到平衡点
9.2 工作流设计最佳实践
-
节点粒度控制:
- 单一职责:每个节点只做一件事
- 适度聚合:避免过度碎片化
- 复用考量:设计可复用的子工作流
-
错误处理设计:
- 明确重试策略:次数、间隔、退避算法
- 设计补偿逻辑:关键操作的逆向操作
- 提供友好错误:用户可理解的错误信息
9.3 性能优化关键点
-
缓存策略:
- 热点数据优先缓存
- 合理设置TTL
- 考虑缓存失效策略
-
并发控制:
- 限制最大并发数
- 实现优先级队列
- 关键资源加锁保护
10. 典型应用场景解析
10.1 智能客服系统
使用Dify构建的智能客服系统可以实现:
- 知识增强:整合产品文档、FAQ等知识库
- 多轮对话:维护对话上下文和历史
- 工具集成:连接订单查询、工单系统等
- 无缝转人工:复杂问题自动转接人工客服
10.2 数据分析助手
基于Dify的数据分析助手特点:
- 自然语言查询:用自然语言描述分析需求
- 自动SQL生成:转换为数据库查询语句
- 可视化呈现:自动生成图表和报告
- 异常检测:识别数据中的异常模式
10.3 内容生成平台
Dify赋能的内容生成平台优势:
- 风格一致:保持品牌声音和调性
- 事实准确:基于可信知识库生成
- 多模态输出:支持文本、图像、视频等
- 合规检查:自动检测敏感和违规内容
11. 平台扩展与定制开发
11.1 自定义工具开发
开发自定义工具的步骤:
- 定义接口契约:输入输出格式、错误码等
- 实现业务逻辑:核心功能实现
- 注册到平台:通过管理界面或API注册
- 测试验证:确保工具正常工作
11.2 插件机制详解
Dify的插件系统支持:
- UI扩展:添加新的界面组件
- 后端扩展:增加新的服务能力
- 集成适配器:连接第三方系统
- 主题定制:修改平台外观风格
11.3 API深度集成
通过API可以实现:
- 工作流触发:远程启动工作流执行
- 状态查询:获取执行进度和结果
- 数据同步:与业务系统数据互通
- 事件订阅:监听平台关键事件
12. 企业级部署考量
12.1 高可用架构设计
生产环境部署建议:
- 多实例部署:避免单点故障
- 负载均衡:均匀分配请求压力
- 灾备方案:制定灾难恢复计划
- 滚动升级:不影响业务的更新策略
12.2 安全合规配置
企业级安全要求:
- 网络隔离:DMZ、VPC等网络划分
- 访问控制:RBAC权限模型
- 数据加密:传输和存储加密
- 审计日志:满足合规要求的日志记录
12.3 性能调优指南
关键性能参数:
- 数据库配置:连接池大小、索引优化
- 缓存策略:Redis集群配置
- 资源配额:容器资源限制
- 批处理优化:减少频繁IO操作
13. 未来演进方向
基于我对Dify平台的深入理解和使用经验,我认为平台未来可能在以下方向继续演进:
-
更智能的编排能力:
- 基于LLM的自动工作流生成
- 动态流程调整和优化
- 智能异常检测和自愈
-
增强的RAG能力:
- 多模态知识库支持
- 实时知识更新机制
- 更精准的引用和溯源
-
代理系统进化:
- 长期记忆和个性化适配
- 多代理协作框架
- 工具学习能力
-
开发者体验提升:
- 更丰富的模板和示例
- 本地开发调试工具链
- 增强的测试和模拟能力
14. 学习路径建议
对于想要掌握Dify平台的开发者,我建议按照以下路径系统学习:
-
基础阶段:
- 理解大模型基本原理
- 学习Prompt Engineering
- 掌握RAG核心概念
-
平台入门:
- 熟悉Dify界面和功能
- 完成官方教程和示例
- 构建简单工作流
-
进阶开发:
- 自定义工具开发
- 复杂工作流设计
- 性能调优技巧
-
专家级:
- 平台扩展开发
- 企业级部署实践
- 疑难问题排查
15. 常见问题解决方案
在实际项目中,我们总结了以下常见问题及解决方法:
-
检索效果不佳:
- 检查切分策略是否合适
- 尝试不同的向量模型
- 调整检索参数(top-k, 相似度阈值)
-
工作流执行失败:
- 检查节点日志定位问题
- 验证输入数据格式
- 确认依赖服务可用性
-
性能瓶颈:
- 分析执行时间分布
- 检查资源利用率
- 优化高延迟节点
-
模型响应质量差:
- 优化Prompt设计
- 尝试不同模型
- 增加上下文相关性
16. 资源与社区支持
为了帮助开发者更好地使用Dify,以下资源非常有用:
- 官方文档:最权威的参考指南
- GitHub仓库:源码和问题追踪
- 社区论坛:与其他开发者交流
- 示例库:各种场景的实现示例
- 技术博客:深度技术解析和案例分享
17. 个人实践心得
在多个Dify项目实施过程中,我总结了以下几点深刻体会:
-
设计先行:在动手开发前,花时间设计合理的工作流结构和数据流,可以避免后期的大量重构。
-
渐进式复杂:从简单原型开始,逐步增加复杂度,比一开始就设计复杂系统更容易成功。
-
监控不可或缺:完善的监控系统不仅能发现问题,还能为优化提供数据支持。
-
团队协作关键:Dify项目的成功往往需要业务专家、AI工程师和软件开发者的紧密协作。
-
持续迭代优化:AI应用需要根据用户反馈和数据表现不断调整和优化。
18. 典型错误与教训
在Dify平台使用过程中,我们曾遇到过以下典型问题,值得新手警惕:
-
过度复杂的工作流:试图在一个工作流中解决所有问题,导致难以维护和调试。解决方案是拆分为多个子工作流。
-
忽视错误处理:初期未充分考虑各种错误场景,导致系统脆弱。后来我们为每个关键节点都设计了完善的错误处理逻辑。
-
向量模型选择不当:曾因选择不合适的向量模型导致检索效果差。通过A/B测试不同模型找到了最佳选择。
-
缺乏性能考量:第一个版本没有考虑性能优化,导致响应时间过长。通过引入缓存和异步处理显著改善了性能。
-
安全配置疏忽:曾因权限配置不当导致数据泄露风险。后来建立了严格的安全评审流程。
19. 效能提升技巧
经过多次项目实践,我们总结出以下提升开发效能的技巧:
-
模板库建设:将常用工作流模式保存为模板,新项目可以快速复用。
-
调试工具链:构建本地调试环境,使用mock服务加速开发测试循环。
-
自动化测试:为关键工作流编写自动化测试脚本,确保核心功能稳定。
-
文档即代码:将设计文档与工作流定义关联,保持文档与实际同步。
-
知识共享机制:定期组织团队内部的技术分享,避免重复踩坑。
20. 结束语
Dify平台代表了AI应用开发的新范式,将复杂的大模型技术工程化、产品化,显著降低了AI应用开发的门槛。通过本文的详细解析,相信你已经对Dify的核心架构和关键技术有了深入理解。
在实际项目中,建议采取"小步快跑"的策略,从简单场景入手,逐步扩展复杂度。同时要重视监控和可观测性建设,这是保证系统稳定运行的关键。最后,Dify平台的强大功能需要与实际业务场景深度结合,才能真正发挥价值。