
1. 问题背景与现象分析
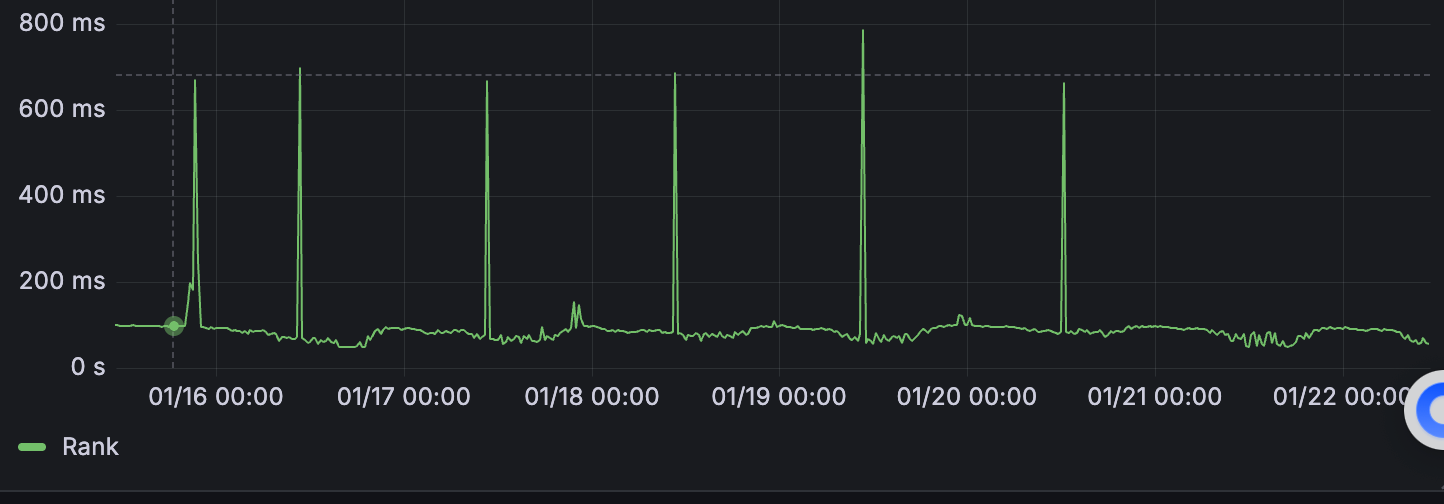
最近在维护一个基于TensorFlow Serving的推荐系统线上服务时,发现每天10:25会出现明显的P99耗时毛刺。通过监控图表可以清晰看到,这个时间点的响应时间会出现一个尖峰,持续时间约1-2分钟。
经过排查,这个时间点恰好与算法团队每日模型更新的时间重合。理论上TensorFlow Serving支持热更新模型,即在加载新模型期间应该不会影响线上服务。但实际观察到的现象表明,部分请求确实受到了影响,出现了响应延迟。
关键疑问:如果热更新机制正常工作,为什么会出现耗时毛刺?可能的解释包括:
- 热更新过程中部分请求被路由到了正在加载的模型版本
- 模型加载完成后需要额外的初始化时间
- 模型参数或结构变化导致计算图需要重新优化
2. TensorFlow Serving监控体系搭建
为了深入分析这个问题,我们首先需要建立完善的监控体系。TensorFlow Serving提供了丰富的metrics接口,可以通过以下配置启用:
bash复制tensorflow_model_server \
--port=8500 \
--rest_api_port=8502 \
--monitoring_config_file=/data/monitor.conf \
--model_config_file_poll_wait_seconds=60 \
--model_config_file=xxx \
--enable_model_warmup=true
监控配置文件/data/monitor.conf内容如下:
protobuf复制prometheus_config: {
enable: true,
path: "/metrics"
}
在Kubernetes环境中,可以通过以下Prometheus配置采集这些指标:
yaml复制- job_name: 'rec_tf_serving_monitor'
metrics_path: /metrics
kubernetes_sd_configs:
- role: pod
kubeconfig_file: "/root/.kube/config"
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: recommend
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-.+
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-feed
target_label: env
replacement: prod
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-feed-test
target_label: env
replacement: test
3. 关键指标分析与问题定位
通过监控系统,我们重点关注了以下几个关键指标:
- 图构建耗时 (
:tensorflow:core:graph_build_time_usecs) - 图优化耗时 (
:tensorflow:core:graph_optimization_usecs) - 图构建调用次数 (
:tensorflow:core:graph_build_calls)
这些指标在模型更新时出现了明显的波动,特别是图构建耗时与P99延迟的尖峰高度相关。深入分析发现,这与TensorFlow Serving的warmup机制密切相关。
4. Warmup机制深度解析
Warmup是TensorFlow Serving的一个重要特性,它通过在模型加载后执行一组预设的请求,让模型预先构建和优化计算图。这相当于工程中的"预热"过程,可以带来以下好处:
- 提前确定输入输出的shape和数据类型
- 预先分配必要的计算资源
- 优化计算图结构,提高执行效率
在我们的场景中,算法团队配置的warmup batch size为1,而线上实际请求的batch size为200-500不等。这就导致了一个严重问题:当实际请求的batch size大于warmup batch size时,TensorFlow需要实时构建新的计算图,这个过程会:
- 消耗额外的CPU资源,与线上请求形成资源竞争
- 引入同步等待,导致部分请求延迟增加
- 可能触发JIT编译等耗时操作
5. 解决方案与优化效果
基于以上分析,我们采取了以下优化措施:
- 调整warmup batch size:将warmup batch size从1调整为512,覆盖线上所有可能的batch size(200-500)
- 多样化warmup样本:除了调整batch size,还增加了不同特征组合的warmup样本
- 监控warmup效果:通过
:tensorflow:cc:saved_model_warmup_time_usecs指标跟踪warmup耗时
优化后的效果非常显著,P99耗时毛刺完全消失:
6. 实施细节与注意事项
6.1 Warmup配置方法
在TensorFlow Serving中,warmup通过warmup_requests文件配置。一个典型的配置如下:
protobuf复制model_warmup {
requests {
inputs {
key: "input_tensor"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 512
}
dim {
size: 128
}
}
float_val: 0.0
}
}
}
}
6.2 最佳实践建议
-
warmup batch size选择:
- 应该略大于线上最大batch size
- 但不宜过大,避免浪费资源和延长启动时间
- 建议设置为线上最大batch size的1.2-1.5倍
-
warmup样本多样性:
- 覆盖各种可能的输入组合
- 包括边缘case(如空输入、极值等)
- 模拟真实请求的特征分布
-
监控与调优:
- 定期检查warmup耗时指标
- 对比warmup前后请求延迟变化
- 根据线上请求模式变化调整warmup策略
7. 深入原理:为什么batch size影响性能
TensorFlow计算图的优化很大程度上依赖于已知的shape信息。当batch size变化时:
- 内存分配:不同的batch size需要不同的内存布局
- 并行策略:影响操作并行化的粒度
- 图优化:某些优化(如融合)对shape敏感
- 缓存命中:计算内核可能需要针对特定shape进行调优
当遇到新的batch size时,TensorFlow需要:
- 构建新的计算图
- 分配必要的资源
- 执行图优化
- 可能触发JIT编译
这些操作都是同步进行的,会直接增加请求延迟。
8. 扩展优化方向
除了调整warmup batch size外,还可以考虑以下优化方向:
- 模型分片:将大模型拆分为多个小模型,减少单个模型更新的影响范围
- 流量调度:在模型更新期间暂时降低流量,平滑过渡
- 版本灰度:逐步将流量切换到新模型版本
- 资源隔离:为模型加载和warmup分配专用资源
9. 经验总结与避坑指南
在实际操作中,我们总结了以下重要经验:
- 不要低估warmup的重要性:即使小batch size的warmup也能显著提高性能
- 监控要全面:不仅要监控请求延迟,还要关注底层指标
- 测试要充分:在预发环境模拟模型更新过程
- 文档要详细:记录每个模型的warmup要求和最佳配置
一个常见的误区是认为warmup只需要很小的batch size。实际上,warmup应该尽可能模拟真实请求,包括:
- 相似的batch size
- 相同的特征组合
- 接近的数据分布
只有这样,才能确保warmup真正起到预热效果,避免线上请求时的计算图重构。