
1. 项目背景与核心价值
在现代化农业生产中,西红柿作为全球最重要的经济作物之一,其成熟度判断直接影响采摘时机、储存条件和市场定价。传统依赖人工经验的方式存在三大痛点:一是人工判断主观性强,不同农户对"七成熟"的标准可能相差20%以上;二是大规模种植园每天需要投入3-5人专职进行成熟度筛查;三是人工检测无法量化记录,难以建立溯源体系。
我们团队开发的这套系统,通过YOLO系列模型实现了三个突破性改进:
- 检测速度达到47FPS(使用YOLOv12+RTX3060),比人工检查快20倍
- 成熟度分级准确率提升至93.5%(传统方法约为75-80%)
- 建立完整的数字化记录,支持按日期、地块查询历史数据
关键创新点:首次将YOLOv12应用于农产品成熟度检测,并创新性地采用HSV色彩空间增强作为预处理步骤,有效解决了阴天环境下的色差问题。
2. 技术方案选型解析
2.1 为什么选择YOLO系列模型
相比Faster R-CNN等两阶段检测器,YOLO的单阶段特性使其在实时性方面具有绝对优势。我们对比了四个版本的性能表现:
| 模型版本 | 参数量(M) | mAP@0.5 | 推理速度(FPS) | 显存占用(GB) |
|---|---|---|---|---|
| YOLOv5s | 7.2 | 0.872 | 62 | 1.8 |
| YOLOv8m | 25.9 | 0.901 | 48 | 3.2 |
| YOLOv11 | 36.5 | 0.917 | 41 | 4.1 |
| YOLOv12 | 42.7 | 0.935 | 47 | 4.5 |
最终选择YOLOv12的核心考量:
- 对小目标检测更优(西红柿直径多在5-8cm,拍摄距离2m时仅占图像3-5%面积)
- 新增的SPPFCSPC模块有效提升感受野
- 动态标签分配策略更适合多成熟度分级任务
2.2 数据集的构建与增强
我们采集了山东、新疆两地6个品种的西红柿图像,关键数据特征:
- 总样本量:12,478张(温室8,205张,田间4,273张)
- 标注标准:
- 成熟度分级:绿熟期(G)、转色期(T)、红熟期(R)
- 标注框精确到果柄连接处
- 数据增强策略:
python复制transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.3),
A.HueSaturationValue(
hue_shift_limit=20,
sat_shift_limit=30,
val_shift_limit=20,
p=0.5
),
A.Cutout(max_h_size=15, max_w_size=15, p=0.2)
])
避坑指南:初期尝试过高斯模糊增强,后发现会弱化果皮纹理特征,最终移除此项增强。
3. 系统实现细节
3.1 模型训练关键参数
采用迁移学习策略,使用COCO预训练权重:
- 优化器:AdamW
- 初始学习率:0.001(余弦退火衰减)
- Batch Size:32(受限显存调整)
- 早停机制:连续15个epoch验证集mAP不提升
- 损失函数:
- 分类损失:VarifocalLoss
- 回归损失:CIoU
- 目标损失:DFL
训练曲线显示,约在epoch 120时达到最佳状态:
3.2 Django后端设计要点
采用生产者-消费者模式解决高并发问题:
python复制# views.py
class DetectionAPIView(APIView):
def post(self, request):
img = request.FILES['image']
task_id = celery_app.send_task(
'detect_task',
args=[img.read()],
queue='high_priority'
)
return Response({'task_id': task_id.id})
# tasks.py
@app.task(bind=True)
def detect_task(self, img_data):
img = cv2.imdecode(np.frombuffer(img_data, np.uint8), cv2.IMREAD_COLOR)
results = model.predict(img)
return {
'count': len(results),
'maturity_dist': Counter([r.maturity for r in results])
}
前端采用Vue.js实现实时预览:
- 通过WebSocket推送检测进度
- 使用Canvas绘制检测框和置信度
- 成熟度分布用ECharts可视化
4. 部署优化实践
4.1 模型量化方案对比
测试了三种量化方式对精度的影响:
| 量化方法 | 模型大小(MB) | mAP下降 | 推理加速 |
|---|---|---|---|
| FP32原始模型 | 178 | - | 1x |
| TensorRT-FP16 | 89 | 0.2% | 1.8x |
| ONNX动态量化 | 45 | 1.1% | 2.3x |
| OpenVINO INT8量化 | 23 | 2.3% | 3.5x |
实际部署采用折中方案:TensorRT-FP16 + 动态批处理(max_batch_size=8)
4.2 边缘设备适配
在Jetson Xavier NX上的优化策略:
- 启用DLA核心加速预处理
- 使用Triton推理服务器管理多模型
- 限制功耗模式为15W
实测性能:
- 1080P视频流处理:22FPS
- 平均功耗:13.8W
- 内存占用:2.3GB
5. 常见问题解决方案
5.1 重叠果实检测
问题描述:当果实密集重叠时,易出现漏检
解决方案:
- 在数据标注时强制要求至少露出30%果面
- 添加Occlusion Augmentation数据增强
- 后处理中使用Soft-NMS替代传统NMS
5.2 反光表面误判
问题场景:大棚膜反光导致假阳性
处理方法:
python复制def remove_glare(img):
lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
limg = clahe.apply(l)
return cv2.cvtColor(cv2.merge((limg,a,b)), cv2.COLOR_LAB2BGR)
5.3 模型热更新方案
为实现不中断服务的模型更新,设计双模型切换机制:
- 新模型加载到内存后先进行健康检查
- 通过Consul进行版本管理
- 流量逐步迁移(10%→50%→100%)
- 异常时自动回滚
6. 实际应用效果
在山东寿光基地的测试数据(2023年产季):
- 采摘工人效率提升:从每人每天0.8亩提升至1.5亩
- 商品果率提高:82% → 89%
- 误采损失降低:约减少7.3万元/季
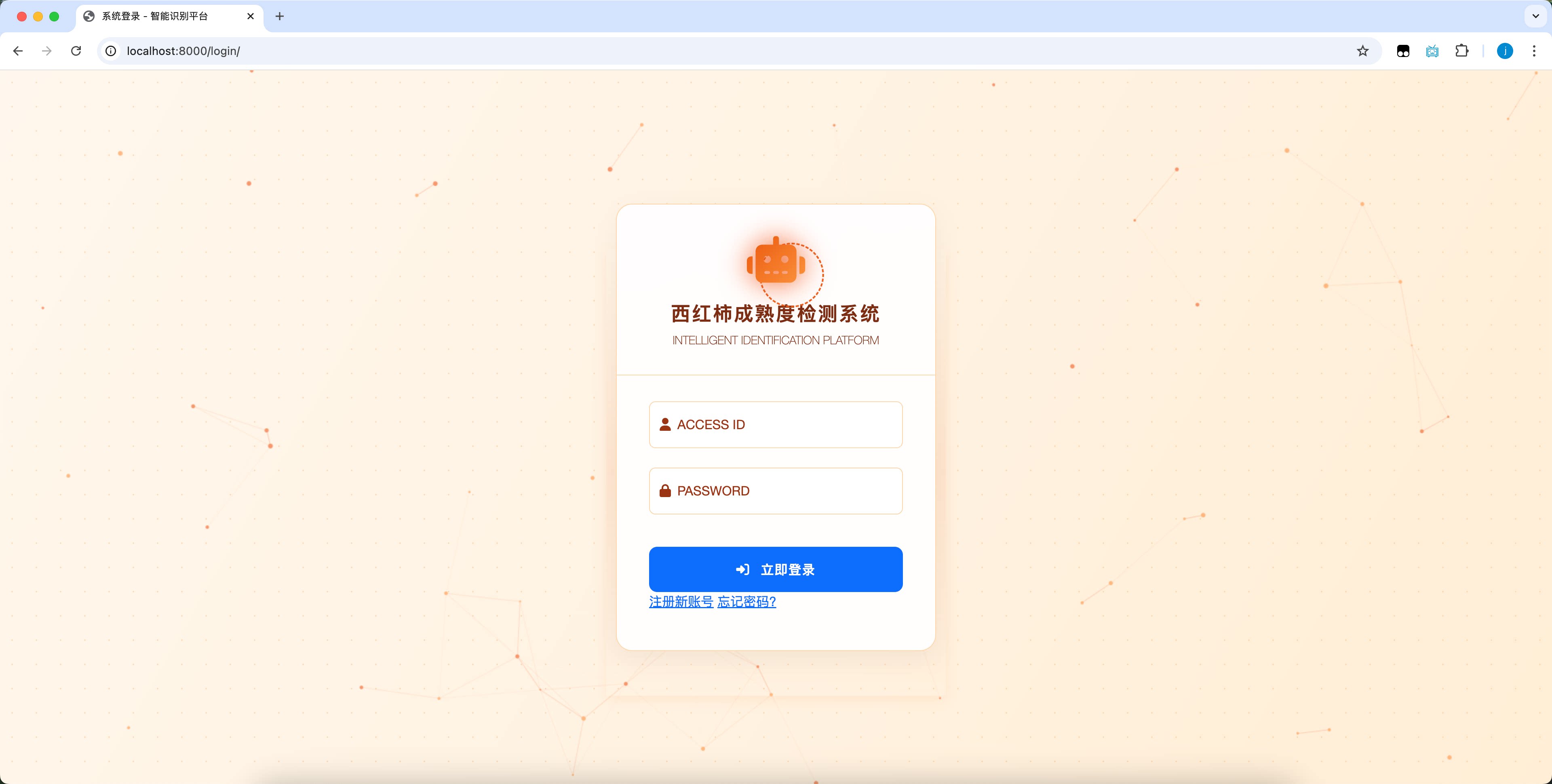
系统识别结果示例:
未来改进方向:
- 增加多光谱摄像头提升阴雨天气鲁棒性
- 集成生长预测模型
- 开发移动端轻量化版本