
1. 引言:大语言模型深度利用的迷思
在咖啡厅里,我正和同事讨论一个有趣的现象:为什么某些大语言模型在增加层数后性能提升并不明显?这个问题困扰着许多研究者。最近北大和MIT联合发表在NIPS Workshop上的论文《What Affects the Effective Depth of Large Language Models?》恰好解答了这个疑惑。
论文揭示了一个反直觉的发现:大语言模型往往只利用了其架构深度的一部分。就像给一个学生增加学习时间,但超过某个临界点后,额外时间只是用来反复检查已完成的作业,而非学习新知识。这种现象被称为"深度利用不足"(Depth Underutilization)。
2. 研究背景与方法论
2.1 有效深度的定义与测量
有效深度(Effective Depth)指的是模型中实际参与特征组合和深层推理的层数比例。想象一下,你有一把20档位的电动螺丝刀,但实际使用中发现超过15档后扭矩不再增加——这就是"有效档位"的概念类比。
研究团队采用了五种互补的测量方法:
-
残差余弦相似度:测量每一层的输出与残差流之间的角度关系。正值表示特征增强,负值表示特征擦除。
-
Logit Lens:通过解码中间隐藏状态,观察模型预测何时趋于稳定。就像在烘焙过程中不断取样测试蛋糕是否烤熟。
-
层跳过实验:选择性禁用某些层,观察对后续计算的影响。类似于关闭某些生产线环节看最终产品质量如何变化。
-
残差擦除:将特定token的残差向量置零,检测信息保留情况。好比在流水线上临时屏蔽某个部件的输入。
-
积分梯度:量化每一层对最终预测的贡献度。类似于分析公司各部门对整体业绩的具体贡献。
2.2 实验模型选择
研究主要基于Qwen-2.5系列模型及其蒸馏版本DeepSeek-R1-Distill。这些模型采用预归一化Transformer架构,使用RMSNorm替代传统层归一化,这种设计在训练稳定性方面表现出色。
3. 核心研究发现
3.1 模型规模与有效深度的关系
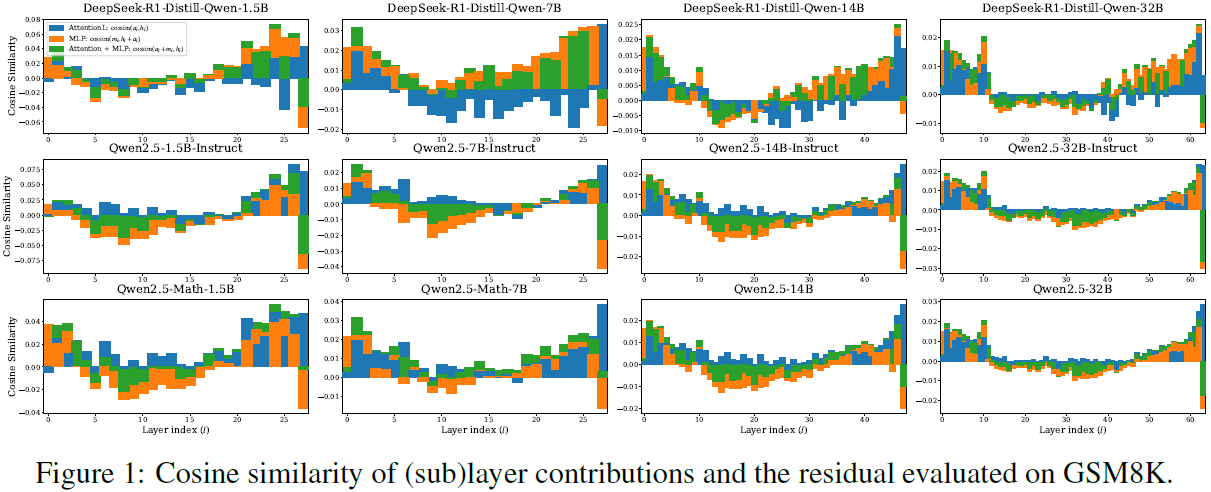
图1:不同规模模型的残差余弦相似度分析
研究发现,无论模型规模如何变化,有效深度比率保持惊人的稳定性。具体表现为:
-
所有模型都呈现三阶段模式:
- 初期:特征擦除主导(负相似度)
- 中期:急剧相位转变
- 后期:特征增强主导(正相似度)
-
更大模型只是增加了"无效"层数,而非有效利用更深层次。好比给建筑增加楼层,但新增楼层只是重复已有功能。
-
Logit Lens分析显示,KL散度在半深度附近急剧下降,表明预测快速稳定化。
关键发现:模型规模扩大时,应该关注如何提高深度利用率,而非简单增加层数。
3.2 思维链模型的深度利用
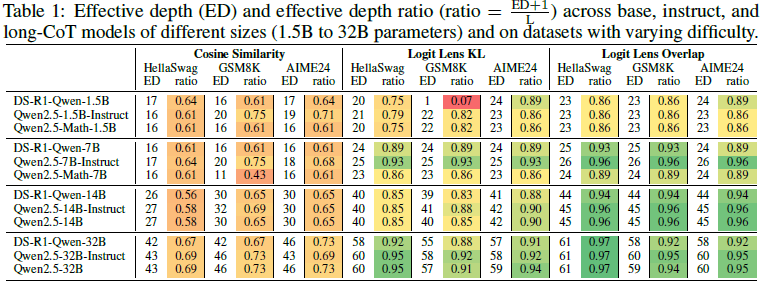
图2:基础模型与思维链模型的深度利用对比
长思维链(CoT)模型虽然在复杂推理上表现优异,但研究发现:
- 基础模型与CoT模型的有效深度比率无显著差异(表1数据)
- 所有测量方法(残差分析、跳层实验等)都支持这一结论
- CoT能力提升可能来自注意力机制优化,而非更深层利用
这就像两个学生:一个通过改进学习方法提高成绩,另一个通过延长学习时间。研究发现CoT模型属于前者。
3.3 任务难度对深度利用的影响
研究选取了三个难度递增的任务:
- HellaSwag(语言理解)
- GSM8K(小学数学)
- AIME24(高中数学竞赛)
结果发现:
- 有效深度在不同难度任务间保持稳定
- 模型不会为困难任务"激活"更多层
- 当前架构缺乏动态深度分配机制
这类似于工厂用相同的生产线处理不同复杂度产品,无法根据产品需求调整生产环节。
4. 技术细节与实现
4.1 残差余弦相似度计算
具体计算公式为:
code复制cos_sim(l) = cosine(h_l - h_{l-1}, h_{l-1})
其中h_l表示第l层的隐藏状态。这个指标可以清晰区分三种层行为:
- 特征新增:cos_sim ≈ 0(正交)
- 特征擦除:cos_sim < 0
- 特征增强:cos_sim > 0
4.2 Logit Lens实现细节
研究采用了两种量化指标:
- KL散度:D_KL(P_final || P_intermediate)
- Top-5 token重叠率
实现时需要注意:
- 使用与训练时相同的tokenizer
- 考虑温度参数对概率分布的影响
- 多次采样减少随机性
4.3 跳层实验设计
跳过第l层的实现方式:
code复制h_{l+1} = h_{l-1} + F_{l+1}(h_{l-1})
通过比较跳过不同层后的输出变化,可以评估各层的重要性。
5. 实践意义与未来方向
5.1 对模型设计的启示
研究发现对架构设计有重要影响:
- 盲目增加深度可能浪费计算资源
- 需要开发更有效的深度利用机制
- 动态深度分配可能是未来方向
5.2 训练策略优化
基于发现的训练建议:
- 中期层可能需要特殊初始化
- 后期层或许需要不同的学习率
- 考虑分层课程学习策略
5.3 未来研究方向
论文指出了几个有前景的方向:
- 开发更鲁棒的有效深度度量
- 探索动态深度自适应架构
- 研究深度利用与泛化能力的关系
6. 实操建议与注意事项
6.1 模型选择建议
根据研究结果,在实际应用中:
- 不必盲目追求更大更深的模型
- 中等规模但优化良好的模型可能性价比更高
- 选择经过深度利用率优化的架构
6.2 模型微调技巧
针对已有模型的优化建议:
- 可以尝试冻结后半部分层
- 对中间层进行针对性微调
- 监控各层的激活情况
6.3 常见误区
需要避免的错误认知:
- "更深一定更好"的简单思维
- 忽视模型的实际深度利用情况
- 过度依赖增加参数量的改进方式
7. 个人实践心得
在实际项目中应用这些发现时,我有几点深刻体会:
-
模型剖析很重要:不能只看最终指标,要理解模型的内部工作机制。我养成了定期用Logit Lens分析模型的习惯。
-
资源分配要合理:与其增加层数,不如优化现有层的效率。我们团队通过调整注意力机制,用较小模型达到了与大模型相当的效果。
-
动态架构有潜力:我们正在实验根据输入复杂度动态跳过某些层的机制,初步结果令人鼓舞。
这个研究最宝贵的启示是:在AI领域,有时候"少即是多"。理解模型的真实行为比盲目扩大规模更重要。就像好的厨师知道,烹饪的关键不在于拥有更多厨具,而在于精通使用现有的每一件工具。