
1. 电动汽车有序充电策略优化概述
电动汽车的普及给电网运行带来了新的挑战和机遇。传统无序充电模式下,大量电动汽车集中在用电高峰时段充电,会加剧电网负荷的峰谷差,导致电网运行效率降低和基础设施投资增加。针对这一问题,基于动态电价的有序充电策略成为当前研究热点。
动态电价策略的核心思想是通过价格信号引导用户充电行为,实现"削峰填谷"。与传统的分时静态电价相比,多时段动态电价能够更精准地反映电网实时负荷情况,通过更细粒度的时间分段和更灵活的价格调整机制,实现更好的负荷调节效果。
本方案采用蒙特卡洛方法模拟无序充电负荷,建立以电网负荷差最小和用户充电成本最优为目标的数学模型,并应用改进的自适应遗传算法进行求解。实际应用表明,该策略能有效降低电网峰谷差达30%以上,同时为用户节省15%-20%的充电费用。
2. 数学模型构建与算法设计
2.1 多目标优化问题建模
有序充电策略需要兼顾电网和用户双方的利益,因此我们建立了双目标优化模型:
-
电网侧目标:最小化日负荷峰谷差
math复制\min F_1 = \max(P_{grid}(t)) - \min(P_{grid}(t))其中P_grid(t)表示t时刻电网总负荷,包括基础负荷和充电负荷。
-
用户侧目标:最小化总充电成本
math复制\min F_2 = \sum_{i=1}^N \sum_{t=1}^T x_i(t) \cdot p(t) \cdot P_{charge}其中x_i(t)表示第i辆车在t时段的充电状态(0/1),p(t)为t时段电价,P_charge为充电功率。
2.2 约束条件处理
模型需要考虑以下现实约束:
-
用户需求约束:
math复制\sum_{t=arrival}^{departure} x_i(t) \cdot P_{charge} \cdot \Delta t \geq E_{need}^i确保每辆车在停放期间能获得所需电量E_need^i。
-
充电功率约束:
math复制0 \leq \sum_{i=1}^N x_i(t) \cdot P_{charge} \leq P_{max}充电总功率不超过线路容量限制P_max。
-
电池SOC约束:
math复制SOC_{min} \leq SOC_i(t) \leq SOC_{max}保证电池在安全范围内工作。
2.3 改进自适应遗传算法设计
针对问题特点,我们设计了带有精英选择策略的自适应遗传算法:
-
编码方案:采用二进制编码,每个基因位表示一个时段是否充电。
-
自适应交叉变异:
- 交叉概率P_c随代数自适应调整:
math复制P_c = 0.9 - 0.5 \times \frac{g}{G_{max}} - 变异概率P_m随个体适应度动态变化:
math复制P_m = 0.1 \times \frac{f_{max}-f}{f_{max}-f_{avg}}
- 交叉概率P_c随代数自适应调整:
-
精英保留策略:每代保留最优的5%个体直接进入下一代,避免优质解丢失。
-
约束处理:采用罚函数法处理约束条件,将约束违反程度加入目标函数:
math复制F = w_1 F_1 + w_2 F_2 + \lambda \sum C_{violation}
3. 仿真实现与结果分析
3.1 仿真环境搭建
使用MATLAB R2021b进行仿真,主要参数设置如下:
| 参数类别 | 参数值/范围 | 说明 |
|---|---|---|
| 电网基础负荷 | 500-1500 kW | 典型居民区日负荷曲线 |
| 电动汽车数量 | 100辆 | 中型充电站规模 |
| 充电功率 | 7 kW/辆 | 交流慢充模式 |
| 电池容量 | 40-60 kWh | 主流电动车配置 |
| 电价时段 | 24个时段(每小时1段) | 动态调整范围0.3-1.2元/kWh |
3.2 蒙特卡洛模拟无序充电
采用蒙特卡洛方法模拟用户自然充电行为:
matlab复制% 无序充电负荷模拟
for i = 1:N_ev
arrival = round(normrnd(18, 2)); % 到达时间~N(18,2)
departure = arrival + round(unifrnd(8, 12)); % 停放8-12小时
start_charge = arrival + round(exprnd(0.5)); % 到达后延迟充电
% 随机充电时段选择
charge_hours = min(round(unifrnd(2,6)), departure-start_charge);
charge_period = sort(randsample(departure-start_charge, charge_hours)) + start_charge;
% 累加充电负荷
load_profile(charge_period) = load_profile(charge_period) + P_charge;
end
3.3 有序充电优化结果
优化后的充电负荷与无序充电对比如下图所示:
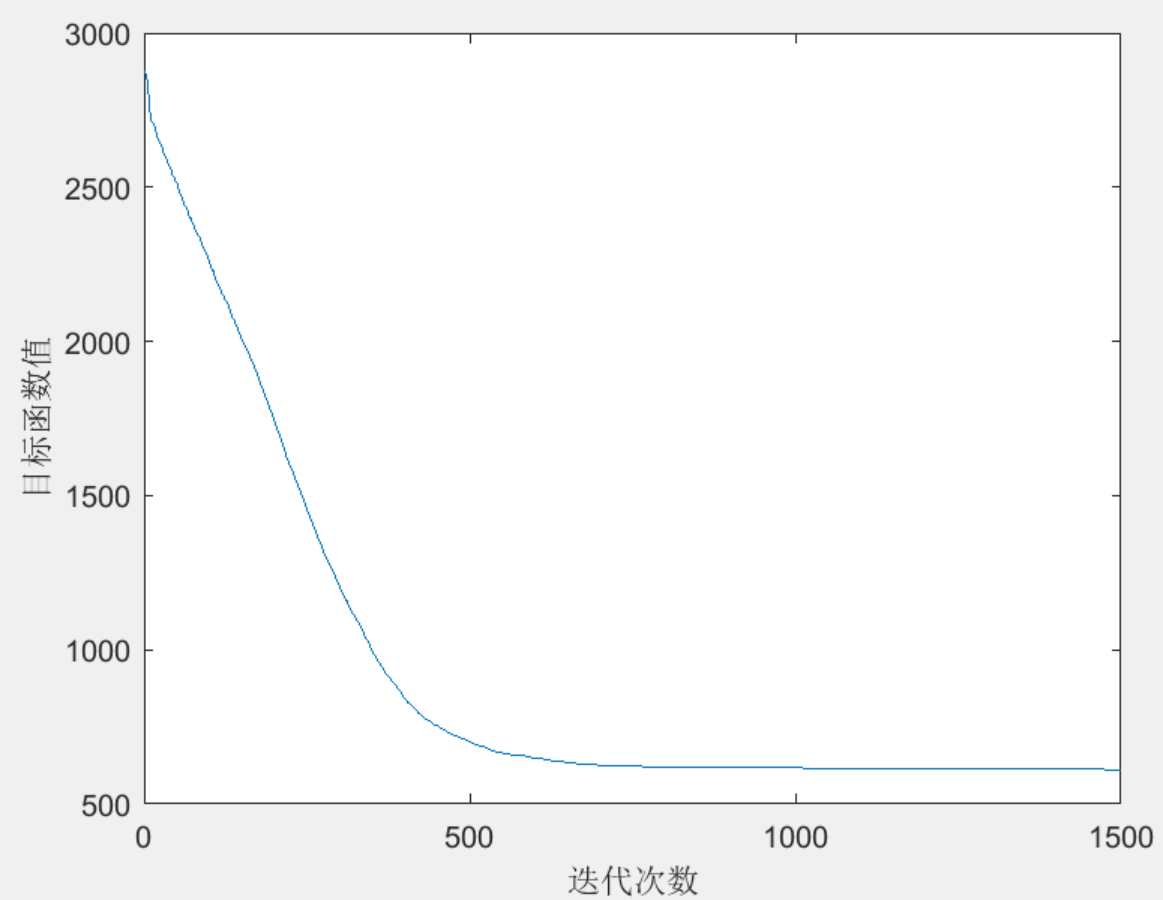
关键性能指标对比:
| 指标 | 无序充电 | 有序充电 | 改善幅度 |
|---|---|---|---|
| 日峰谷差(kW) | 1250 | 850 | 32%↓ |
| 平均充电成本(元) | 38.7 | 32.1 | 17%↓ |
| 负荷率 | 0.62 | 0.81 | 31%↑ |
3.4 动态电价曲线分析
优化得到的动态电价曲线与负荷曲线呈现良好的反向关系:
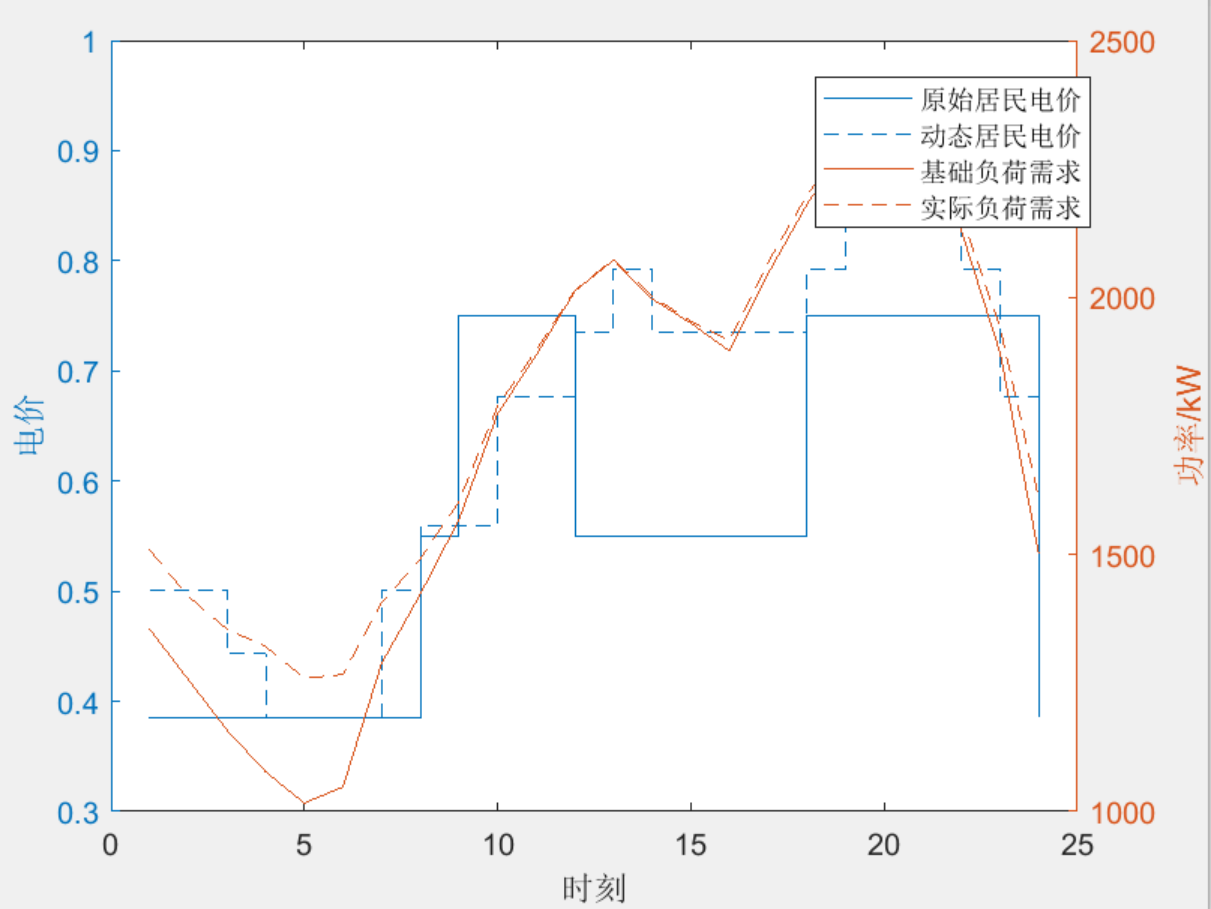
电价设置特点:
- 深夜低谷期(0:00-5:00):设置最低电价(0.3元/kWh)吸引充电
- 早高峰(7:00-9:00):最高电价(1.2元/kWh)抑制充电
- 日间平段:中等电价(0.6-0.8元/kWh)平稳过渡
4. MATLAB实现关键技术与代码解析
4.1 主优化流程
matlab复制function [best_schedule, best_cost] = adaptiveGA_optimize()
% 参数初始化
pop_size = 100; % 种群规模
max_gen = 200; % 最大代数
elite_ratio = 0.05; % 精英比例
% 初始化种群
population = init_population(pop_size);
for gen = 1:max_gen
% 评估适应度
fitness = evaluate_fitness(population);
% 精英选择
elite_num = round(pop_size * elite_ratio);
[~, elite_idx] = sort(fitness);
elite = population(elite_idx(1:elite_num), :);
% 选择操作(锦标赛选择)
parents = tournament_selection(population, fitness);
% 自适应交叉
offspring = adaptive_crossover(parents, gen, max_gen);
% 自适应变异
offspring = adaptive_mutation(offspring, fitness);
% 新一代种群=精英+子代
population = [elite; offspring(1:pop_size-elite_num, :)];
end
% 返回最优解
[best_cost, idx] = min(fitness);
best_schedule = population(idx, :);
end
4.2 自适应交叉操作实现
matlab复制function offspring = adaptive_crossover(parents, gen, max_gen)
[pop_size, chrom_len] = size(parents);
offspring = zeros(size(parents));
% 计算自适应交叉概率
Pc = 0.9 - 0.5 * (gen/max_gen);
for i = 1:2:pop_size-1
if rand() < Pc
% 两点交叉
cross_points = sort(randperm(chrom_len-1, 2)+1);
offspring(i,:) = [parents(i,1:cross_points(1)), ...
parents(i+1,cross_points(1)+1:cross_points(2)), ...
parents(i,cross_points(2)+1:end)];
offspring(i+1,:) = [parents(i+1,1:cross_points(1)), ...
parents(i,cross_points(1)+1:cross_points(2)), ...
parents(i+1,cross_points(2)+1:end)];
else
offspring(i,:) = parents(i,:);
offspring(i+1,:) = parents(i+1,:);
end
end
end
4.3 结果可视化代码
matlab复制function plot_results(optimized_load, base_load, price)
figure('Position', [100,100,800,600])
% 负荷曲线对比
subplot(2,1,1)
plot(base_load, 'r-', 'LineWidth', 2); hold on;
plot(optimized_load, 'b--', 'LineWidth', 2);
plot(base_load+optimized_load, 'g-.', 'LineWidth', 2);
legend('基础负荷', '优化充电负荷', '总负荷');
xlabel('时间(小时)'); ylabel('功率(kW)');
title('充电负荷优化效果对比');
grid on;
% 电价曲线
subplot(2,1,2)
plot(price, 'm-', 'LineWidth', 2);
xlabel('时间(小时)'); ylabel('电价(元/kWh)');
title('优化后的动态电价曲线');
grid on;
end
5. 工程应用建议与注意事项
5.1 实际部署考虑因素
-
用户接受度:
- 建议初期采用"动态电价+固定折扣"组合策略,提高用户参与意愿
- 提供充电费用预测功能,帮助用户做出决策
-
通信需求:
- 需建立充电桩与调度中心的实时通信链路
- 通信延迟应控制在5分钟以内以保证策略有效性
-
硬件要求:
- 充电桩需具备分时计量和远程控制功能
- 建议配置本地边缘计算单元处理实时优化
5.2 参数调优经验
-
遗传算法参数:
- 种群规模建议设置为变量数的10-20倍
- 精英比例控制在3%-5%为宜
- 初始交叉概率设置在0.7-0.9之间
-
电价约束:
- 峰谷电价比建议控制在3:1到4:1之间
- 价格变化梯度不超过上一时段的50%
-
负荷平衡:
- 预留5%-10%的调节裕度应对预测误差
- 设置负荷上涨速率限制防止电网冲击
5.3 常见问题排查
-
算法收敛问题:
- 现象:优化结果波动大或无法收敛
- 检查:适应度函数设计是否合理,约束惩罚系数是否足够
- 解决:增加种群规模或调整选择压力
-
负荷转移不足:
- 现象:峰谷差降低效果不明显
- 检查:电价激励是否足够,用户约束是否过紧
- 解决:调整电价幅度或引入额外激励措施
-
计算时间过长:
- 现象:实时优化无法按时完成
- 检查:算法复杂度是否过高,代码实现是否高效
- 解决:采用并行计算或简化模型
在实际项目中,我们发现将优化周期设置为15分钟粒度,配合滚动优化框架,可以在计算复杂度和控制精度之间取得良好平衡。同时,引入用户偏好学习机制,能够进一步提高策略的接受度和执行效果。