
1. 论文概述:Point-SRA的创新与贡献
Point-SRA是AAAI 2026会议上发表的一篇关于3D点云表征学习的创新论文。这篇论文针对当前掩码自编码器(MAE)在3D点云处理中的两个关键局限性提出了系统性解决方案:
核心问题识别:
- 固定掩码率策略忽视了不同掩码率下表征的互补性
- 传统逐点确定性重建无法处理点云固有的几何多样性
创新解决方案:
论文提出的Point-SRA框架通过三个关键技术突破解决了这些问题:
- 自蒸馏与概率建模实现的双重表征对齐机制
- MeanFlow Transformer(MFT)的概率重建能力
- 流场条件微调架构
2. 理论基础与关键发现
2.1 掩码率互补性理论
论文通过信息瓶颈理论框架,建立了掩码率与表征特性之间的数学关系:
定理A(掩码率互补性):
对于不同掩码率r_l < r_h,存在:
- 互信息关系:I(P;f_θ_l*(X_rl)) > I(P;f_θ_h*(X_rh))
- 语义压缩度:C(f_θ_h*(X_rh)) > C(f_θ_l*(X_rl))
这个理论发现表明:
- 低掩码率(≤30%)的表征更擅长保留几何细节
- 高掩码率(≥75%)的表征更擅长捕捉语义抽象
2.2 重建不确定性分析
论文揭示了传统MAE逐点重建的局限性:
定理B(重建不确定性):
给定可见区域P_V,掩码区域P_M的条件分布满足:
H(p(P_M|P_V)) > 0
这意味着同一可见区域可能对应多种合理的重建结果,传统确定性重建方法无法有效处理这种多样性。
3. Point-SRA方法详解
3.1 整体架构设计
Point-SRA包含四个核心组件:
- MAE模块:基础几何特征学习
- MFT模块:概率轨迹建模
- MAE-SRA:掩码率层面的表征对齐
- MFT-SRA:时间状态层面的表征对齐
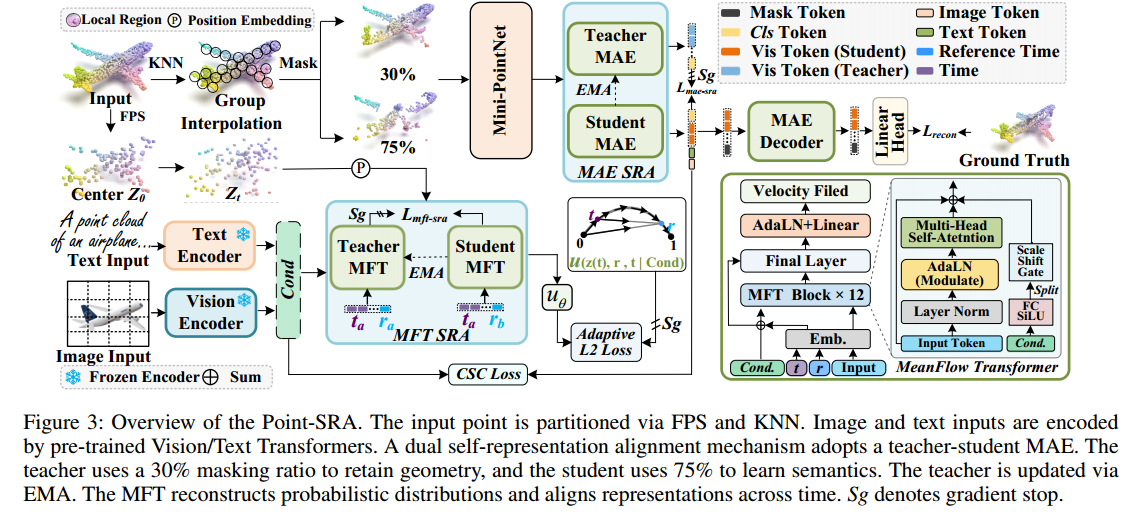
3.2 MeanFlow Transformer设计
MFT通过以下创新设计实现了稳定的概率建模:
平均速度场预测:
u_θ(z_t,r,t|c) ≈ (z_r - z_t)/(r - t)
条件特征构造:
c = e_t(t) + e_r(r) + W_imgf_img + W_textf_text
自适应L2损失:
L_MFM = E[sg(w)·||u_θ - u_target||²]
其中w = 1/(||u_θ - u_target||² + ε)^p
3.3 双重自表征对齐机制
3.3.1 MAE-SRA
实现不同掩码率表征的对齐:
- 学生模型:高掩码率(75%)
- 教师模型:低掩码率(30%)
损失函数:
L_mae-sra = 1 - (h_student·h_teacher)/(|h_student|·|h_teacher|)
3.3.2 MFT-SRA
实现不同时间步表征的对齐:
L_mft-sra = ||h_ta - sg(h_tb + u_θ·(ta - tb))||²
4. 实验验证与结果分析
4.1 主要实验结果
ScanObjectNN分类任务:
- OBJ_BG:95.53%(+5.51%)
- OBJ_ONLY:93.31%(+5.02%)
- PB_T50_RS:90.77%(+5.59%)
颅内动脉瘤分割:
- 动脉IoU:96.07%
- 动脉瘤IoU:86.87%
3D目标检测:
- AP@50:47.3%(+5.12%)
4.2 消融研究
核心组件有效性:
- 完整Point-SRA相比基线提升显著
- MeanFlow单独带来5.45%的准确率提升
流条件微调架构:
- 投影+门控组合效果最佳(分割性能84.88%)
概率建模方法对比:
- MeanFlow在分类准确率和训练稳定性上均优于扩散模型
5. 技术实现细节
5.1 训练配置
优化器:
- AdamW,初始学习率3e-4
- 权重衰减0.05
- 训练300个epoch
损失权重:
- λ_flow = 0.5
- λ_mae-sra = 0.2
- λ_mft-sra = 0.2
5.2 网络结构
MFT设计:
- 12层Transformer块
- 隐藏维度768
- 16个注意力头
时间调度:
- 均匀采样策略表现最佳
- 时间区间[0,1]
6. 实际应用建议
6.1 部署注意事项
- 掩码率配置:
- 教师模型推荐30%掩码率
- 学生模型推荐75%掩码率
- 最佳掩码率差约0.45
- 训练技巧:
- 使用自适应L2损失稳定训练
- EMA动量系数m=0.999
- 批量大小至少64
6.2 下游任务适配
分类任务:
- 直接使用[CLS]token特征
- 微调学习率设为预训练的1/10
分割任务:
- 采用流条件微调架构
- 冻结编码器参数
- 仅微调解码器
7. 扩展思考与未来方向
7.1 方法局限性
- 计算成本:
- MFT模块增加了约30%的计算开销
- 训练需要较大显存(建议≥32GB)
- 小数据集表现:
- 在数据量<1k时优势不明显
- 需要足够多样的掩码样本
7.2 潜在改进方向
- 高效蒸馏:
- 探索隐状态知识蒸馏
- 降低MFT计算复杂度
- 多模态扩展:
- 融合更多模态条件
- 跨模态对比学习
- 动态掩码策略:
- 自适应掩码率调整
- 基于内容的掩码生成
8. 关键代码实现
8.1 MeanFlow核心代码
python复制class MeanFlowTransformer(nn.Module):
def __init__(self, dim=768, depth=12, heads=16):
super().__init__()
self.layers = nn.ModuleList([
TransformerBlock(dim, heads) for _ in range(depth)
])
self.time_embed = nn.Sequential(
nn.Linear(1, dim//4),
nn.SiLU(),
nn.Linear(dim//4, dim)
)
def forward(self, x, t, c):
t_emb = self.time_embed(t.unsqueeze(-1))
x = x + t_emb + c
for layer in self.layers:
x = layer(x)
return x
8.2 自表征对齐实现
python复制def mae_sra_loss(student_feat, teacher_feat):
# 特征归一化
student_feat = F.normalize(student_feat, p=2, dim=-1)
teacher_feat = F.normalize(teacher_feat, p=2, dim=-1)
# 余弦相似度损失
return 1 - (student_feat * teacher_feat).sum(dim=-1).mean()
def mft_sra_loss(h_ta, h_tb, u_theta, delta_t):
target = h_tb.detach() + u_theta * delta_t
return F.mse_loss(h_ta, target)
9. 常见问题解答
Q1:如何选择掩码率?
建议采用渐进式策略:
- 预训练阶段:教师30%,学生75%
- 微调阶段:根据任务调整(分类20-40%,分割40-60%)
Q2:处理小规模数据集的技巧?
- 使用更强的数据增强
- 降低MFT的层数(如8层)
- 增加MAE-SRA的损失权重
Q3:训练不稳定的解决方法?
- 检查梯度裁剪(max_norm=1.0)
- 使用混合精度训练
- 增大batch size或累积梯度
10. 总结与个人实践建议
Point-SRA通过系统的理论分析和创新的架构设计,在3D表征学习领域取得了显著进展。在实际应用中,我发现以下几点特别值得注意:
- 掩码策略对最终性能影响很大,需要仔细调参
- MFT的时间调度对训练稳定性很关键,推荐均匀采样
- 流条件微调在下游任务中能带来稳定提升
对于想要复现或应用该方法的研究者,建议:
- 先从标准配置开始,逐步调整
- 关注表征的可视化分析,理解不同模块的作用
- 根据具体任务特点调整对齐机制的权重