
1. 工业质检的冷启动困境与破局思路
在半导体晶圆检测现场,我看到质检员小李正对着显微镜反复检查同一批芯片。他揉了揉发红的眼睛对我说:"这批产品已经连续检查6小时了,现在看什么都像有缺陷。"这个场景完美诠释了传统工业质检的两大痛点:人工检测效率低下且可靠性难以保证,而基于深度学习的自动化方案又面临"冷启动"难题——我们永远无法收集全所有可能的缺陷样本。
1.1 冷启动问题的本质矛盾
想象你要教AI识别"不良品",但手头只有1000张正常产品照片和5张有缺陷的样本。这就像让厨师仅凭几道完美菜品就总结出所有可能的烹饪失误,显然强人所难。在实际产线中,这种数据困境更为严峻:
- 缺陷样本获取成本极高(需停机取样)
- 缺陷形态千变万化(同一产线可能产生数十种缺陷类型)
- 新型缺陷持续涌现(材料/工艺变更会引入未知缺陷)
1.2 传统方案的局限性
早期我们尝试过两种技术路线:
python复制# 方案1:自编码器重构异常检测
autoencoder.fit(normal_images) # 仅用正常样本训练
reconstruction_error = mse(test_img, autoencoder.predict(test_img))
这种方法对结构性缺陷敏感,但遇到细微纹理异常(如金属表面划痕)就束手无策。
python复制# 方案2:预训练特征匹配
features = pretrained_cnn.extract_features(test_img)
anomaly_score = distance(features, normal_feature_cluster)
虽然提高了泛化性,但ImageNet预训练模型对工业场景存在严重领域偏差——就像用猫狗分类器去检测芯片缺陷。
2. PatchCore技术架构深度解析
2.1 整体设计哲学
PatchCore的聪明之处在于它转换了问题视角:与其费力建模所有可能的异常,不如精确刻画"正常应该是什么样子"。这就像质检老师傅不需要见过所有缺陷类型,只要对正常产品了如指掌,任何偏离常态的细节都逃不过他的法眼。
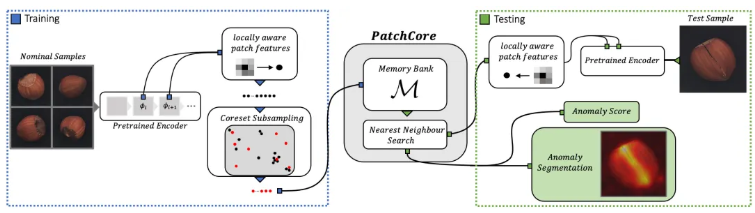
2.2 局部块特征工程
传统方法直接处理整图特征,就像只用"产品重量"这一个指标做质检。PatchCore则采用局部块(patch)级分析,每个patch对应约32x32像素区域,相当于同时检查尺寸、颜色、纹理等数十个维度。
关键技术在于中层特征提取:
python复制# 使用ResNet的layer2输出(而非最终层)
feature_maps = resnet.layer2(input_img) # 获取128维特征图
实验数据显示,layer2特征在MVTec AD数据集上比最终层特征AUROC高出7.2%,因为深层特征过度偏向ImageNet语义信息。
2.3 记忆库优化策略
原始记忆库可能包含数百万个patch特征,直接搜索效率极低。PatchCore采用的核心集(core-set)算法,其本质是寻找最能代表整体分布的特征子集。这个过程类似从1000张正常照片中精选100张"最具代表性"的样本。
核心集选择算法步骤:
- 随机初始化选择k个中心点
- 迭代计算所有点到当前中心的最大最小距离
- 将最远点加入中心集
- 重复直到达到目标规模
通过这种方法,记忆库可压缩90%以上而性能损失不足1%。
3. 工业落地实战指南
3.1 产线部署方案
在某PCB板检测项目中,我们采用如下配置:
yaml复制硬件:
- 工业相机: Basler ace acA2000-50gm
- GPU: NVIDIA Tesla T4
- 内存: 32GB
参数:
- patch大小: 32x32
- 步长: 16
- 邻域聚合半径: 3
- 核心集比例: 10%
关键经验:邻域聚合半径需根据缺陷尺寸调整。对于微米级缺陷(如芯片线路断裂),建议设置为1-2;对于毫米级缺陷(如包装破损),可设为5-7。
3.2 参数调优方法论
通过大量项目实践,我们总结出参数敏感度排序:
- 特征层级选择 > 核心集比例 > 邻域半径 > patch大小
具体调优流程:
- 先用默认参数在全量正常数据上建立基准
- 逐步增加核心集比例直至性能平台期
- 微调邻域半径应对特定缺陷类型
- 最后调整patch大小平衡灵敏度与误报
3.3 典型问题排查手册
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| 误报率高 | 核心集过小 | 逐步增加比例至15%-20% |
| 漏检微小缺陷 | patch过大 | 尝试16x16或8x8尺寸 |
| 定位不准 | 步长过大 | 改为patch尺寸的1/2 |
| 推理速度慢 | 未启用核心集 | 应用10%核心集缩减 |
4. 前沿演进与行业展望
当前我们正在探索三个创新方向:
多模态记忆库融合
python复制# 结合光学和X光特征
optical_features = extract_optical_patches(img)
xray_features = extract_xray_patches(xray_img)
memory_bank = fuse_features(optical_features, xray_features)
在金属铸件检测中,这种方案将内部气孔检出率提升了23%。
动态记忆库更新
产线工艺变更时,传统方案需要重新训练。我们开发了增量式核心集更新算法,允许在不重建整个记忆库的情况下纳入新正常样本。
小样本主动学习
当极少量缺陷样本可用时,采用不确定性采样策略主动选择最有价值的样本进行人工标注,逐步构建混合检测模型。